3.3. технология моделирования случайных факторов
3.3. технология моделирования случайных факторов
3.3.1. Генерация псевдослучайных чисел
Как уже отмечалось ранее, имитационное моделирование ЭИС, как правило, предполагает необходимость учета различных случайных факторов — событий, величин, векторов (систем случайных величин), процессов.
В основе всех методов и приемов моделирования названных случайных факторов лежит использование случайных чисел, равномерно распределенных на интервале [0; 1].
До появления ЭВМ в качестве генераторов случайных чисел применяли механические устройства — колесо рулетки, специальные игральные кости и устройства, которые перемешивали фишки с номерами, вытаскиваемые вручную по одной.
По мере роста объемов применения случайных чисел для ускорения их моделирования стали обращаться к помощи электронных устройств. Самым известным из таких устройств был электронный импульсный генератор, управляемый источником шума, разработанный широко известной фирмой RAND Corporation. Фирмой в 1955 г. была выпущена книга, содержащая миллион случайных чисел, сформированных этим генератором, а также случайные числа в записи на магнитной ленте. Использовались и другие подобные генераторы — например, основанные на преобразовании естественного случайного шума при радиоактивном распаде. Все эти генераторы обладают двумя недостатками:
невозможно повторно получить одну и ту же последовательность случайных чисел, что бывает необходимо при экспериментах с имитационной моделью;
технически сложно реализовать физические генераторы, способные длительное время выдавать случайные числа "требуемого качества".
В принципе, можно заранее ввести полученные таким образом случайные числа в память машины и обращаться к ним по мере необходимости, что сопряжено с понятными негативными обстоятельствами — большим (причем неоправданным) расходом ресурсов ЭВМ и затратой времени на обмен данными между долгосрочной и оперативной памятью (особенно существенно для "больших" имитационных моделей).
В силу этого наибольшее распространение получили другие генераторы, позволяющие получать так называемые псевдослучайные числа (ПСЧ) с помощью детерминированных рекуррентных формул. Псевдослучайными эти числа называют потому, что фактически они, даже пройдя все тесты на случайность и равномерность распределения, остаются полностью детерминированными. Это значит, что если каждый цикл работы генератора начинается с одними и теми же исходными данными, то на выходе получаем одинаковые последовательности чисел. Это свойство генератора обычно называют воспроизводимостью последовательности ПСЧ.
Программные генераторы ПСЧ должны удовлетворять следующим требованиям:
ПСЧ должны быть равномерно распределены на интервале [0; 1] и независимы, т. е. случайные последовательности должны быть некоррелированы;
цикл генератора должен иметь возможно большую длину;
последовательность ПСЧ должна быть воспроизводима;
генератор должен быть быстродействующим;
генератор должен занимать малый объем памяти.
Первой расчетной процедурой генерации ПСЧ, получившей достаточно широкое распространение, можно считать метод срединных квадратов, предложенный фон Нейманом и Метрополисом в 1946 г. Сущность метода заключается в последовательном нахождении квадрата некоторого тп-значного числа; выделении из него т средних цифр, образующих новое число, которое и принимается за очередное в последовательности ПСЧ; возведении этого числа в квадрат; выделении из квадрата т средних цифр и т. д. до получения последовательности требуемой длины.
Как следует из описания процедуры метода, он весьма прост в вычислительном отношении и, следовательно, легко реализуем программно. Однако ему присущ очень серьезный недостаток — обусловленность статистических свойств генерируемой последовательности выбором ее корня (началъногр значения), причем эта обусловленность не является "регулярной", т. е. трудно определить заранее, можно ли использовать полученные данным методом ПСЧ при проведении исследований.
Это обстоятельство иллюстрируется рис. 3.3.1, на котором представлены результаты генерации последовательности из ста ПСЧ при следующих исходных данных: число знаков m = 4; корни последовательности а) Х0 = 2152; б) Х0 = 2153; в) Х0 = 3789; г) Х0 = 3500. Из анализа рисунка видно, что при Х0 = 2152 уже с 78-го члена последовательности все ПСЧ принимают нулевые значения; при Х0 = 2153, начиная с 36-го значения, последовательность перестает быть случайной; при Х0 = 3789 первые 100 членов последовательности можно использовать в качестве ПСЧ (дальнейшее поведение последовательности ПСЧ требует дополнительных исследований); при Х0 = 3500 (2500; 4500 и т. д.) нулевые значения
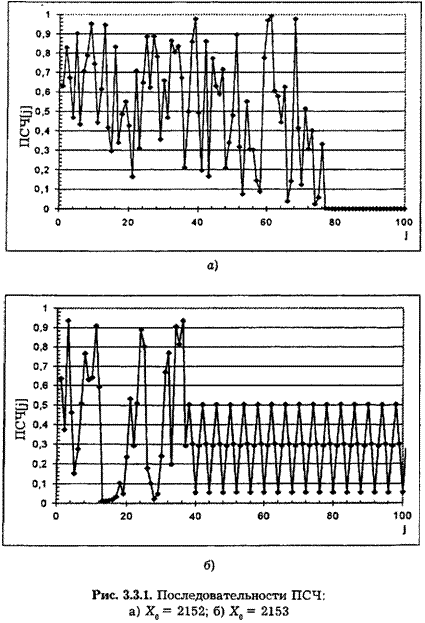
принимают все ПСЧ. Иными словами, метод срединных квадратов не позволяет по начальному значению оценить качество последовательности ПСЧ, в частности ее период.
Мультипликативный метод
Основная формула мультипликативного генератора для расчета значения очередного ПСЧ по значению предыдущего имеет вид:
Х.+1 — аХ (mod т),
где а, т — неотрицательные целые числа (их называют множитель и модуль).
Как следует из формулы, для генерации последовательности ПСЧ необходимо задать начальное значение (корень) последовательности, множитель и модуль, причем период (длина) последовательности Р зависит от разрядности ЭВМ и выбранного модуля, а статистические свойства — от выбранного начального значения и множителя. Таким образом, следует выбирать перечисленные величины так, чтобы по возможности максимизировать длину последовательности и минимизировать корреляцию между генерируемыми ПСЧ. В специальной литературе приводятся рекомендации по выбору значений параметров метода, использование которых обеспечивает (гарантирует) получение определенного количества ПСЧ с требуемыми статистическими свойствами (отметим, что данное замечание можно отнести ко всем конгруэнтным методам). Так, если для машины с двоичной системой счисления задать m = 2b,a = 8T±3-V, где Ъ — число двоичных цифр (бит) в машинном слове; Т — любое целое положительное число; V — любое положительное нечетное число, получим последовательность ПСЧ с периодом, рав-m
ным Р = 2Ь ~ 2 = —. Заметим, что в принципе возможно за
счет другого выбора модуля m увеличить длину последовательности до Р = m — 1, частично пожертвовав скоростью вычислений [48]. Кроме того, важно, что получаемые таким образом ПСЧ оказываются нормированными, т. е. распределенными от 0 до 1.
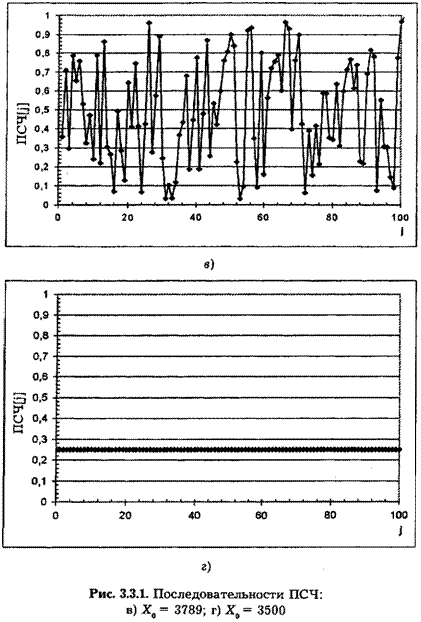
На рис. 3.3.2 приведены последовательности ПСЧ, полученные по мультипликативному методу со следующими параметрами: Х0 = 15; Т = 3; V = 1; а) Ъ — 4; б) Ъ = 6 (столь малые значения b объясняются стремлением проиллюстрировать работоспособность рекомендованных формул). Очевидно, что в первом случае длина последовательности до повторений равна 4, а во втором — 16 ПСЧ. Легко показать, что от выбора корня последовательности ее длина не зависит (при равенстве остальных параметров).
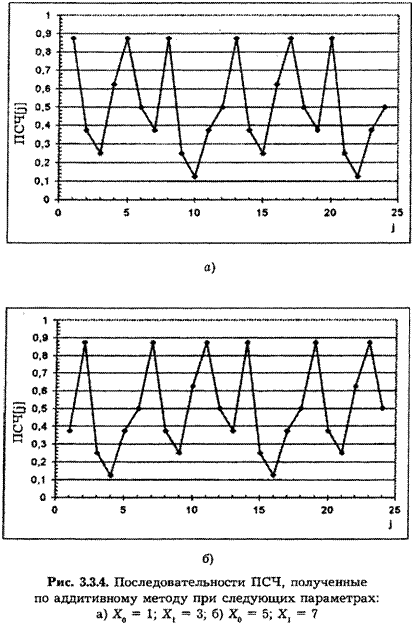
Аддитивный метод
Основная формула для генерации ПСЧ по аддитивному методу имеет вид:
Х.+1 = а(Х. + X^Xmod m),
где т — целое число.
Очевидно, что для инициализации генератора, построенного по этому методу, необходимо помимо модуля т задать два исходных члена последовательности. При Х0 = 0; Xj = 1 последовательность превращается в ряд Фибоначчи. Рекомендации по выбору модуля совпадают с предыдущим случаем; длину последовательности можно оценить по приближенной формуле
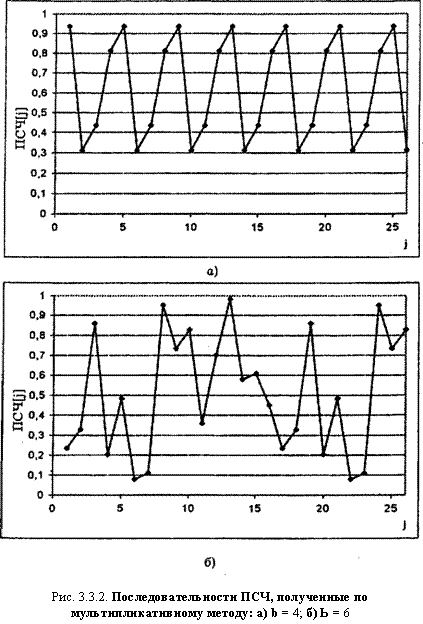
Р = 2Ь+І 2(Ь 1). На рис. 3.3.3 приведены две последовательности ПСЧ, полученные при исходных данных: а) Ъ = 3; Х0 = 1; X, = 3; б) в = 4; Х0 = 5; Xt = 7. В обоих случаях период последовательности ПСЧ равен 12.
Смешанный метод
Данный метод несколько расширяет возможности мультипликативного генератора за счет введения так называемого коэффициента сдвига с. Формула метода имеет вид:
Х<+, = (аХ. + c)(mod т).
а)
J
За счет выбора параметров генератора можно обеспечить максимальный период последовательности ПСЧ Р = 2Ь.
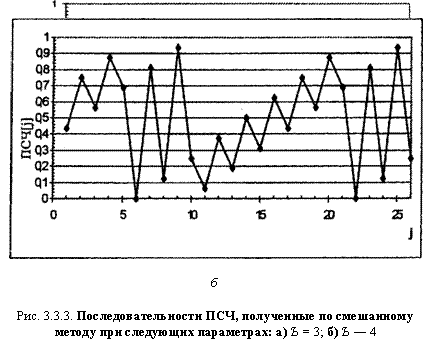
На рис. 3.3.4 показаны две последовательности ПСЧ, полученные при следующих исходных данных: с = 13; а = 9; a) b = 3; б) b = 4. В первом случае длина последовательности равна 8, а во втором — 16 ПСЧ.
Разработано множество модификаций перечисленных конгруэнтных методов, обладающих определенными преимуществами при решении конкретных практических задач, а также рекомендаций по выбору того или иного метода [48]. Для весьма широкого круга задач вполне удовлетворительными оказываются типовые генераторы ПСЧ, разработанные, как правило, на основе смешанного метода и входящие в состав стандартного общего программного обеспечения большинства ЭВМ. Специальным образом генерацию ПСЧ организуют либо для особо масштабных имитационных исследований, либо при повышенных требованиях к точности имитации реального процесса (объекта).
Подводя итог вышеизложенному, подчеркнем, что разработка конгруэнтных методов зачастую осуществляется на основе эвристического подхода, основанного на опыте и интуиции исследователя. После модификации известного метода тщательно проверяют, обладают ли генерируемые в соответствии с новой формулой последовательности ПСЧ требуемыми статистическими свойствами, и в случае положительного ответа формируют рекомендации по условиям ее применения.
3.3.2. Моделирование случайных событий
В теории вероятностей реализацию некоторого комплекса условий называют испытанием. Результат испытания, регистрируемый как факт, называют событием.
Случайным называют событие, которое в результате испытания может наступить, а может и не наступить (в отличие от достоверного события, которое при реализации данного комплекса наступает всегда, и невозможного собы-
тия, которое при реализации данного комплекса условий не наступает никогда). Исчерпывающей характеристикой случайного события является вероятность его наступления. Примерами случайных событий являются отказы в экономических системах; объемы выпускаемой продукции предприятием каждый день; котировки валют в обменных пунктах; состояние рынка ценных бумаг и биржевого дела и т. п.
Моделирование случайного события заключается в " определении ("розыгрыше") факта его наступления.
Для моделирования случайного события А, наступающего в опыте с вероятностью РА, достаточно одного случайного (псевдослучайного) числа R, равномерно распределенного на интервале [0; 1]. В случае попадания ПСЧ R в интервал [0; РА] событие А считают наступившим в данном опыте; в противном случае — не наступившим в данном опыте. На рис. 3.3.5 показаны оба исхода: при ПСЧ Rt событие следует считать наступившим; при ПСЧ R2 — событие в данном испытании не наступило. Очевидно, что чем больше вероятность наступления моделируемого события, тем чаще ПСЧ, равномерно распределенные на интервале [0; 1], будут попадать в интервал [0; РА], что и означает факт наступления события в испытании.
Для моделирования одного из полной группы N случайных несовместных событий Al, А2,..., AN с вероятностями наступления {РА1, РА2, -»paN}, соответственно, также достаточно одного ПСЧ R.
Напомним, что для таких случайных событий можно записать:
 |

0
R
1
Рис. 3.3.5. Моделирование случайных событий
Факт наступления одного из событий группы определяют исходя из условия принадлежности ПСЧ R тому или иному интервалу, на который разбивают интервал [0; 1]. Так, на рис. 3.3.6 для ПСЧ Rj считают, что наступило событие А2. Если ПСЧ оказалось равным R2, считают, что наступило событие A(N-l).
•—і—зк—і 1—
*0 TP~ PAi + PA2 ' • ' Pai + -+Pa,n-d 'l
Рис. 3.3.6. Моделирование полной группы несовместных событий
Если группа событий не является полной, вводят дополнительное (фиктивное) событие A(N+1), вероятность которого определяют по формуле:
N
Далее действуют по уже изложенному алгоритму для полной группы событий с одним изменением: если ПСЧ попадает в последний, (N+l)-ft интервал, считают, что ни одно из N событий, составляющих неполную группу, не наступило.
В практике имитационных исследований часто возникает необходимость моделирования зависимых событий, для которых вероятность наступления одного события оказывается зависящей от того, наступило или не наступило другое событие. В качестве одного из примеров зависимых событий приведем доставку груза потребителю в двух случаях: когда маршрут движения известен и был поставщиком дополнительно уточнен, и когда уточнения движения груза не проводилось. Понятно, что вероятность доставки груза от поставщика к потребителю для приведенных случаев будет различной.
Для того чтобы провести моделирование двух зависимых случайных событий А и В, необходимо задать следующие полные и условные вероятности:
Р(А); Р(В); Р(В/А); Р(ВА).
Заметим, что, если вероятность наступления события В при условии, что событие А не наступило, не задана, ее можно определить по формуле:
гшл^Р{В)~Р{А)Р{в1л)
1-Р(А)
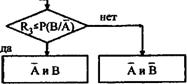
Существуют два алгоритма моделирования зависимых событий. Один из них условно можно назвать "последовательным моделированием"; другой — "моделированием после предварительных расчетов".
Последовательное моделирование
Алгоритм последовательного моделирования представлен на рис. 3.3.7.
Несомненными достоинствами данного алгоритма являются его простота и естественность, поскольку зависимые события "разыгрываются" последовательно — так, как они наступают (или не наступают) в реальной жизни, что и является характерной особенностью большинства имитационных моделей. Вместе с тем алгоритм предусматривает троекратное обращение к датчику случайных чисел (ДСЧ), что увеличивает время моделирования.
 |
 |
Рис. 3.3.7. "Последовательное моделирование" зависимых событий 300
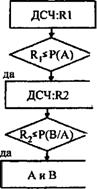
Моделирование после предварительных расчетов
Как легко заметить, приведенные на рис. 3.3.7 четыре исхода моделирования зависимых событий образуют полную группу несовместных событий. На этом основан алгоритм моделирования, предусматривающий предварительный расчет вероятностей каждого из исходов и "розыгрыш" факта наступления одного из них, как для любой группы несовместных событий (см. выше). Рис. 3.3.8 иллюстрирует разбиение интервала [0; 1] на четыре отрезка, длины которых соответствуют вероятностям исходов наступления событий.
О a b с 1
tz^zzfc
Р(А • В)
Р(А-В) Р(АВ) Р(АВ) Р(А-В)
Рис. 3.3.8. Разбиение интервала [0; 1] для реализации алгоритма моделирования зависимых событий "после предварительных расчетов"
На рис. 3.3.9 представлен алгоритм моделирования. Данный алгоритм предусматривает одно обращение к датчику случайных чисел, что обеспечивает выигрыш во времени
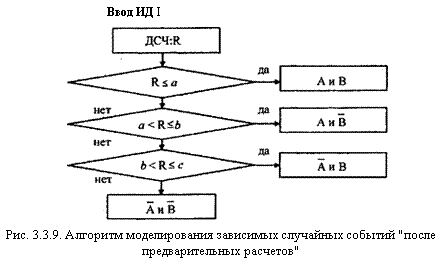 |
имитации по сравнению с "последовательным моделированием", однако перед началом работы алгоритма исследователь должен рассчитать и ввести вероятности реализации всех возможных исходов (естественно, эту несложную процедуру можно также оформить программно, но это несколько удлинит алгоритм).
3.3.3. Моделирование случайных величин
В практике создания и использования имитационных моделей весьма часто приходится сталкиваться с необходимостью моделирования важнейшего класса факторов — случайных величин (СВ) различных типов.
Случайной называют переменную величину, которая в результате испытания принимает то или иное значение, причем заранее неизвестно, какое именно. При этом под испытанием понимают реализацию некоторого (вполне определенного) комплекса условий. В зависимости от множества возможных значений различают три типа СВ:
непрерывные;
дискретные;
смешанного типа.
Исчерпывающей характеристикой любой СВ является ее закон распределения, который может быть задан в различных формах: функции распределения — для всех типов СВ; плотности вероятности (распределения) — для непрерывных СВ; таблицы или ряда распределения — для дискретных СВ.
В данном пункте изложены основные методы моделирования СВ первых двух типов как наиболее часто встречающихся на практике.
Моделирование непрерывных случайных величин
Моделирование СВ заключается в определении ("розыгрыше") в НУЖНЫЙ ПО ХОДУ ИМИТаЦИИ МОМеНТ времени 7сок7сретного значения СВ в соответствии с требуемым (заданным) законом распределения.
Наибольшее распространение получили три метода:
метод обратной функции;
метод исключения (Неймана);
метод композиций.
Метод обратной функции
Метод позволяет при моделировании СВ учесть все ее статистические свойства и основан на следующей теореме:
Если непрерывная СВ Y имеет плотность вероятности /(у), то СВ X, определяемая преобразованием
х= ]f(y)dy=F(y),
имеет равномерный закон распределения на интервале [0; 1].
Данную теорему поясняет рис. 3.3.10, на котором изображена функция распределения СВ Y.
F(y)

Рис. 3.3.10. Функции распределения СВ Y
Теорему доказывает следующая цепочка рассуждений, основанная на определении понятия "функция распределения" и условии теоремы:
F(x) = P(X —со Таким образом, получили равенство F(x) = х, а это и означает, что СВ X распределена равномерно в интервале [0; 1]. Напомним, что в общем виде функция распределения равномерно распределенной на интервале [а; Ъ] СВ X имеет вид: F(x)= 0,х<а; х-а ,а<х<Ь Ь-а ,х>Ъ. Теперь можно попытаться найти обратное преобразование функции распределения F(-1)(x). Если такое преобразование существует (условием этого является наличие первой производной у функции распределения), алгоритм метода включает всего два шага: моделирование ПСЧ, равномерно распределенного на интервале [0; 1]; подстановка этого ПСЧ в обратную функцию и вычисление значения СВ Y: x=F(y)=>y=F^)(x). При необходимости эти два шага повторяются столько раз, сколько возможных значений СВ Y требуется получить. Пример. Длина свободного пробега нейтрона в однородном веществе d (d >0) имеет следующее распределение [18, 35]: F(d) =1-е-**', где ad — среднее квадратическое отклонение длины пробега. 304 Тогда формула для генерации возможного значения СВ D имеет вид: где R — ПСЧ, распределенное равномерно в интервале [0; 1]. Простота метода обратной функции позволяет сформулировать такой вывод: если обратное преобразование функции распределения СВ, возможные значения которой необходимо получить, существует, следует использовать именно этот метод. К сожалению, круг СВ с функциями распределения, допускающими обратное преобразование, не столь широк, что потребовало разработки иных методов. Метод исключения (Неймана) Метод Неймана позволяет из совокупности равномерно распределенных ПСЧ R, по определенным правилам выбрать совокупность значений yt с требуемой функцией распределения f(y) [18, 35]. Алгоритм метода Выполняется усечение исходного распределения таким образом, чтобы область возможных значений СВ Y совпадала с интервалом [а, Ъ]. В результате формируется плотность вероятности /*(у) такая, что ь !f*(y)dy=. а Длина интервала [а, Ъ] определяется требуемой точностью моделирования значений СВ в рамках конкретного исследования. Генерируется пара ПСЧ R1 и R2, равномерно распределенных на интервале [0; 1]. Вычисляется пара ПСЧ R1* и R2* по формулам: Rx* = а + (Ь а) ■ Ri, R* = MR2, где M=max f*(y). ye[a; b] На координатной плоскости пара чисел {Rx*; R2*) определяет точку — например, точку Qj на рис. 3.3.11. На рисунке обозначены: А — прямоугольник, ограничивающий график плотности распределения моделируемой СВ; D — область прямоугольника А, находящаяся ниже графика /*(у); В — область прямоугольника А, находящаяся выше графика f*(y). Если точка (Qj) принадлежит области D, считают, что получено первое требуемое значение СВ t/j = Rj*. Генерируется следующая пара ПСЧ R3 и R4, равномерно распределенных на интервале [0; 1], после пересчета по п. 3 задающих на координатной плоскости вторую точку — Q2. Если точка (Q2) принадлежит области В, переходят к моделированию следующей пары ПСЧ (R5; R6) и т. д. до получения необходимого количества ПСЧ. Очевидно, что в ряде случаев (при попадании изображающих точек в область В соответствующие ПСЧ с нечетными
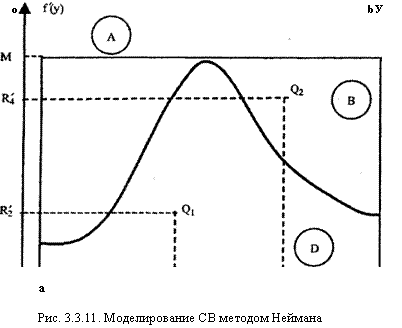
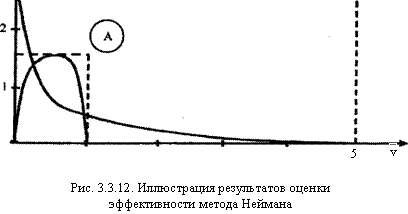
индексами не могут быть включены в требуемую выборку возможных значений моделируемой СВ, причем это будет происходить тем чаще, чем сильнее график /*(у) по форме будет "отличаться" от прямоугольника А. Оценить среднее относительное число q "пустых" обращений к генератору ПСЧ можно геометрическим методом, вычислив отношение площадей соответствующих областей (В и А):
SA= М-(Ъа) = SB+SD = SB + 1; Sb= Sa — 1;
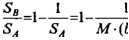 |
о
 |
з
Для первой функции q ~ 0,33; для второй — q ~ 0,92. Таким образом, для ^-распределения метод Неймана почти в три раза эффективнее, чем для у-распределения. В целом для многих законов распределения (особенно для островершинных и имеющих длинные "хвосты") метод исключения приводит к большим затратам машинного времени на генерацию требуемого количества ПСЧ.
Главным достоинством метода Неймана является его универсальность — применимость для генерации СВ, имеющих любую вычислимую или заданную таблично плотность вероятности.
Метод композиции
Применение метода основано на теоремах теории вероятностей, доказывающих представимость одной СВ композицией двух или более СВ, имеющих относительно простые,
более легко реализуемые законы распределения. Наиболее часто данным методом пользуются для генерации ПСЧ, имеющих нормальное распределение. Согласно центральной предельной теореме распределение СВ Y, задаваемой преобразованием . k ,
' .(2^-£),
/А ы
V12
где К, — равномерно распределенные на интервале [0; 1] ПСЧ, при росте к неограниченно приближается к нормальному распределению со стандартными параметрами [ту = 0; сту = 1].
Последнее обстоятельство легко подтверждается следующим образом. Введем СВ Z и найдем параметры ее распределения, используя соответствующие теоремы о математическом ожидании и дисперсии суммы СВ:
M[Z]=m2 = M[imr]=imr=i^-;
<=і /=і /=і 2 2
Напомним, что при равномерном распределении в интервале [0; 1] СВ имеет параметры:
Очевидно, что
и, как любая центрированно-нормированная СВ, имеет стандартные параметры.
Как правило, берут к =12 и считают, что для подавляющего числа практических задач обеспечивается должная точность вычислений. Если же к точности имитации предъявляются особые требования, можно улучшить качество моделирования СВ за счет введения нелинейной поправки [8]:
где у(к) — возможное значение СВ Y, полученное в результате сложения, центрирования и нормирования к равномерно распределенных ПСЧ R{.
Еще одним распространенным вариантом применения метода композиции является моделирование возможных значений СВ, обладающей х2 распределением с п степенями свободы: для этого нужно сложить "квадраты" п независимых нормально распределенных СВ со стандартными параметрами.
Возможные значения СВ, подчиненной закону распределения Симпсона (широко применяемого, например, в радиоэлектронике), моделируют, используя основную формулу метода при к = 2. Существуют и другие приложения этого метода.
В целом можно сделать вывод о том, что метод композиции применим и дает хорошие результаты тогда, когда из теории вероятностей известно, композиция каких легко моделируемых СВ позволяет получить СВ с требуемым законом распределения.
Моделирование дискретных случайных величин
Дискретные случайные величины (ДСВ) достаточно часто используются при моделировании систем. Основными методами генерации возможных значений ДСВ являются:
метод последовательных сравнений;
метод интерпретации.
Метод последовательных сравнений
Алгоритм метода практически совпадает с ранее рассмотренным алгоритмом моделирования полной группы несовместных случайных событий, если .считать номер события номером возможного значения ДСВ, а вероятность наступления события — вероятностью принятия ДСВ этого возможного значения. На рис. 3.3.13 показана схема определения номера возможного значения ДСВ, полученного на очередном шаге.
Из анализа ситуации, показанной на рис. 3.3.13 для ПСЧ R, "попавшего" в интервал [Pjj Р! + Р2], следует сделать вывод, что ДСВ приняла свое второе возможное значение; а для ПСЧ R' — что ДСВ приняла свое (N-l)-e значение и т. д. Алгоритм последовательных сравнений можно улучшить (ускорить) за счет применения методов оптимизации перебора — дихотомии (метода половинного деления); перебора с предварительным ранжированием вероятностей возможных значений по убыванию и т. п.
• іті 1 1—і—і— *►
О »Р, Ip,+P2 I Р, +Р2 + Р3' •• 1 1 1 P,+...+ PN_, 1
Рис. 3.3.13. Моделирование ДСВ методом последовательных сравнений
Метод интерпретации
Метод основан на использовании модельных аналогий с сущностью физических явлений, описываемых моделируемыми законами распределения.
На практике метод чаще всего используют для моделирования биномиального закона распределения, описывающего число успехов в п независимых опытах с вероятностью успеха в каждом испытании р и вероятностью неудачи q = 1-р.
Алгоритм метода для этого случая весьма прост:
моделируют п равномерно распределенных на интервале [0; 1] ПСЧ;
подсчитывают число т тех из ПСЧ, которые меньше р;
это число т и считают возможным значением моделируемой ДСВ, подчиненной биномиальному закону распределения.
Помимо перечисленных, существуют и другие методы моделирования ДСВ, основанные на специальных свойствах моделируемых распределений или на связи между распределениями [7].
3.3.4. Моделирование случайных векторов
Случайным вектором (системой случайных величин) называют совокупность случайных величин, совместно характеризующих какое-либо случайное явление: где X, СВ с теми или иными законами распределения.
X = (Xj, Х2,...,ХП).
Данный пункт содержит материал по методам моделирования непрерывных случайных векторов (все компоненты которых представляют собой непрерывные случайные величины — НСВ).
Исчерпывающей характеристикой случайного вектора является совместная многомерная функция распределения его компонент F(a:1, x2,...,xj или соответствующая ему совместная многомерная плотность вероятности
f(X}, х2,—,хп).
Проще всего моделировать случайный вектор с независимыми компонентами, для которого
л
f{xbx2,...,xn)=X[fi{xt) 1=1
справедливо, т. е. каждую из компонент случайного вектора можно моделировать независимо от других в соответствии с ее "собственной" плотностью вероятности /{(х{).
В случае, когда компоненты случайного вектора статистически зависимы, необходимо использовать специальные методы:
метод условных распределений;
метод исключения (Неймана);
метод линейных преобразований.
Метод условных распределений
Метод основан на рекуррентном вычислении условных плотностей вероятностей для каждой из компонент случайного вектора X с многомерной совместной плотностью вероятности f(xux2,...,xn).
Для плотности распределения случайного вектора X можно записать:
f(Xl,X2,...,Xn) — f(X^'f2(X2/x^-f3(X3/X2,X^'.^fJ^Xn/Xnrl,Xn^2, —tXj)
где /^х,) — плотность распределения СВ Xjj fk(xk/xk-uxk-2~>xi) — плотность условного распределения СВ Хк при условии: X, = а^; Х2 = хг;...; Xfc., = xk_v
Для получения указанных плотностей необходимо провести интегрирование совместной плотности распределения случайного вектора в соответствующих пределах:
fl(xl)=j...ff(xl,x2,...,xn)dx2...dxn);
, /2(v*.)=f-f ••••<**,,);
s2 Л(хі)
" " fl(xl)-f(x2/xl):.,f(xnJxn_2,...,xl)
Порядок моделирования:
♦ моделировать значение а:,* СВ X, по закону /^а:,);
моделировать значение х2* СВ Х2 по закону f2(x2/x*)
...;
моделировать значение хп* СВ Х„ по закону
fn(Xn/Xn-l*> Хп-2*>->Х*)Тогда вектор а:,*, а:2*,...,а:п*) и есть реализация искомого случайного вектора X.
Метод условных распределений (как и метод обратной функции для скалярной СВ) позволяет учесть все статистические свойства случайного вектора. Поэтому справедлив вывод: если имеется возможность получить условные плотности распределения
fk(xk/xk-i>xk-2>->xi)> следует пользоваться именно этим методом.
Метод исключения (Неймана)
Метод является обобщением уже рассмотренного для СВ метода Неймана на случай п переменных. Предполагается, что все компоненты случайного вектора распределены в конечных интервалах
х(е [at, bj, і = 1,2 п.
Если это не так, необходимо произвести усечение плотности распределения для выполнения данного условия. Алгоритм метода:
Генерируются (п+1) ПСЧ
K2,...,R„; Rf,
распределенных, соответственно, на интервалах [а„ bj, [а2, Ь2],...,[а„, bj; [О, /^J; /max=max...max / (хх,х2,...,хп).
х;е[а,-,6|,];/=1,2)...л
Если выполняется условие:
Щ Л^і» К2,...,К„),
то вектор
(Rv R2,...,Rn)
и есть искомая реализация случайного вектора.
3. Если данное условие не выполняется, переходят к первому пункту и т. д.
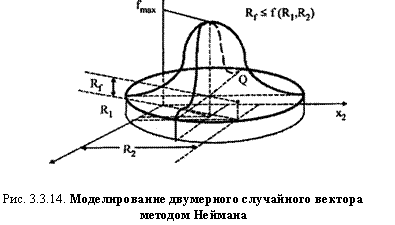
Рис. 3.3.14 содержит иллюстрацию данного алгоритма для двумерного случая.
Возврат к п. 1 после "неудачного" моделирования п ПСЧ происходит тогда, когда т. Q окажется выше поверхности, представляющей двумерную плотность вероятности f{xv х2). Для случая, представленного на рисунке, в качестве (очередной) реализации двумерного случайного вектора следует взять пару ПСЧ (Rlt R2).
Среднюю относительную частоту "неудач" можно вычислить геометрическим способом, взяв отношение объемов соответствующих фигур.
 |
Метод линейных преобразований
Метод линейных преобразований является одним из наиболее распространенных так называемых корреляционных методов, применяемых в случаях, когда при моделировании непрерывного n-мерного случайного вектора достаточно обеспечить лишь требуемые значения элементов корреляционной матрицы этого вектора (это особенно важно для случая нормального распределения, для которого выполнение названного требования означает выполнение достаточного условия полного статистического соответствия теоретического и моделируемого распределений).
Идея метода заключается в линейном преобразовании случайного n-мерного вектора Y с независимыми (чаще всего — нормально распределенными) компонентами в случайный вектор X с требуемыми корреляционной матрицей и вектором математических ожиданий компонент.
Математическая постановка задачи выглядит следующим образом.
Дано: корреляционная матрица и математическое ожидание вектора X
Q = Ы = М[(Х{ тх)Щ mXj)]\;
М = (т т тх )т.
12 п
Требуется: найти такую матрицу В, которая позволяла бы в результате преобразования
X = BY + М, ... (3.3.1)
где Y — n-мерный вектор с независимыми нормально распределенными компонентами со стандартными параметрами, получить вектор X с требуемыми характеристиками.
Будем искать матрицу В в виде нижней треугольной матрицы, все элементы которой, расположенные выше главной диагонали, равны 0. Перейдем от матричной записи к системе алгебраических уравнений:
| Хг |
|
|
|
|
|
| x |
| Х2 |
| ъХ2 ъ22 |
|
| Y2 |
|
|
| ■ |
| ■ |
| X |
| + | • |
| х„ |
|
| ■К |
|
|
| mr |
Xx -mxx=bn-Yx; X2-mX2=b2X-Yx+b22-Y2;
(3.3.2)
Xn~mXn =b„x■ Yx +bn2■ Y2 +... + b„„ Y„.
Поскольку компоненты вектора Y независимы и имеют стандартные параметры, справедливо выражение:
[U=jПочленно перемножив сами на себя и между собой соответственно левые и правые части уравнений системы (3.3.2) и взяв от результатов перемножения математическое ожидание, получим систему уравнений вида:
М[(ХХ-тХх)-(Хх-mXi)) = M[buYxblxYx];
■ M[(Xx-mXi)(X2-mX2)] = M[b2xYx-b22-Y2)-bxx-Yx].
Как легко увидеть, в левых частях полученной системы уравнений — элементы заданной корреляционной матрицы Q а в правых — элементы искомой матрицы В.
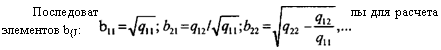 Формула для расчета любого элемента матрицы преобразования В имеет вид:
Формула для расчета любого элемента матрицы преобразования В имеет вид:
7-1
biJ=-^—-;l Таким образом, алгоритм метода линейных преобразований весьма прост: по заданной корреляционной матрице рассчитывают значения коэффициентов матрицы преобразования В; + генерируют одну реализацию вектора Y, компоненты которого независимы и распределены нормально со стандартными параметрами; полученный вектор подставляют в выражение (3.3.1) и определяют очередную реализацию вектора X, имеющего заданные корреляционную матрицу и вектор математических ожиданий компонент; при необходимости два предыдущих шага алгоритма повторяют требуемое число раз (до получения нужного количества реализаций вектора X). В данном пункте рассмотрены основные методы генерации ПСЧ, равномерно распределенных на интервале [0; 1], и моделирования случайных событий, величин и векторов, часто используемые в практике имитационных исследований ЭИС. Как правило, все современные программные средства, применяемые для реализации тех или иных имитационных моделей, содержат встроенные генераторы равномерно распределенных ПСЧ, что позволяет исследователю легко моделировать любые случайные факторы.

Обсуждение Информационные системы в экономике
Комментарии, рецензии и отзывы