3.2. эксперимент по методу монте-карло
3.2. эксперимент по методу монте-карло
По-видимому, никто точно не знает, почему эксперимент по методу Монте-Карло называется именно так. Возможно, это название имеет какое-то отношение к известному казино как символу действия законов случайности.
Основное понятие будет объяснено посредством аналогии. Предположим, что свинья обучена находить трюфели. Это дикорастущие земляные грибы, встречающиеся во Франции и Италии и считающиеся деликатесом. Они дороги, так как их трудно найти, и хорошая свинья, обученная поиску трюфелей, стоит дорого. Проблема состоит в том, чтобы узнать, насколько хорошо свинья ищет трюфели. Она может находить их время от времени, но возможно также, что большое количество трюфелей она пропускает. В случае действительной заинтересованности вы могли бы выбрать участок земли, закопать трюфели в нескольких местах, отпустить свинью и посмотреть, сколько грибов она обнаружит. Посредством такого контролируемого эксперимента можно было бы непосредственно оценить степень успешности поиска.
Какое отношение это имеет к регрессионному анализу? Проблема в том, что мы никогда не знаем истинных значений аир (иначе зачем бы мы использовали регрессионный анализ для их оценки?). Поэтому мы не можем сказать, хорошие или плохие оценки дает наш метод. Эксперимент по методу Монте-Карло — это искусственный контролируемый эксперимент, дающий возможность такой проверки. Простейший возможный эксперимент по методу Монте-Карло состоит из трех частей. Во-первых:
выбираются истинные значения а и Р;
в каждом наблюдении выбирается значение х;
используется некоторый процесс генерации случайных чисел (или берется последовательность из таблицы случайных чисел) для получения значений случайного фактора и в каждом из наблюдений.
Во-вторых, в каждом наблюдении генерируется значение у с использованием соотношения (3.1) и значений а, р, х и и.
В-третьих, применяется регрессионный анализ для оценивания параметров а и b с использованием только полученных указанным образом значений у и данных для х. При этом вы можете видеть, являются ли а и b хорошими оценками а и р, и это позволит почувствовать пригодность метода построения регрессии.
На первых двух шагах проводится подготовка к применению регрессионного метода. Мы полностью контролируем модель, которую создаем, и знаем истине ные значения параметров, потому что сами их определили. На третьем этапе мы определяем, может ли поставленная нами задача решаться с помощью метода регрессии, т. е. могут ли быть получены хорошие оценки для аир при использовании только данных об у и х. Заметим, что проблема возникает вследствие включения случайного фактора в процесс получения у. Если бы этоТ/фактор отсутствовал, то точки, соответствующие значениям каждого наблюдения, лежали бы точно на прямой (3.1) и точные значения аир можно было бы очень просто определить по значениям у и х.
Произвольно положим а = 2 и р = 0,5, так что истинная зависимость имеет вид:
у=2 + 0,5х + и. (3.7)
Предположим для простоты, что имеется 20 наблюдений и что х принимает значения от 1 до 20. Для случайной остаточной составляющей и будем использовать случайные числа, взятые из нормально распределенной совокупности с нулевым средним и единичной дисперсией. Нам потребуется набор из 20 значений, обозначим их т{, га20. Случайный член их в первом наблюдении просто равен /ті| и т. д.
Зная значения хи и в каждом наблюдении, можно вычислить значения у, используя уравнение (3.7); это сделано в табл. 3.1. Теперь при оценивании регрессионной зависимости у от х получим:
j>= 1,63 + 0,54х. (3.8)
В данном случае оценка а приняла меньшее значение (1,63) по сравнению с а (2,00), а Ъ немного выше Р (0,54 по сравнению с 0,50). Расхождения вызваны совместным влиянием случайных членов в 20 наблюдениях.
Очевидно, что одного эксперимента такого типа едва ли достаточно для оценки качества метода регрессии. Он дат довольно хорошие результаты, но, возможно, это лишь счастливый случай. Для дальнейшей проверки повторим эксперимент с тем же истинным уравнением (3.7) и с теми же значениями х, но с новым набором случайных чисел для остаточного члена, взятых из того же распределения (нулевое среднее и единичная дисперсия). Используя эти значения и значения х, получим новый набор значений у.
В целях экономии места таблица с новыми значениями и и у не приводится. Вот результат оценивания регрессии между новыми значениями у и х:
у= 2,52 + 0,48х. (3.9)
| Таблица 3.1 | |||||
| X | и | У | X | и | У |
| 1 | -0,59 | 1,91 | 11 | 1,59 | 9,09 |
| 2 | -0,24 | 2,76 | 12 | -0,92 | 7,08 |
| 3 | -0,83 | 2,67 | 13 | -0,71 | 7,79 |
| 4 | 0,03 | 4,03 | 14 | -0,25 | 8,75 |
| 5 | -0,38 | 4,12 | 15 | 1,69 | 11,19 |
| 6 | -2,19 | 2,81 | 16 | 0,15 | 10,15 |
| 7 | 1,03 | 6,53 | 17 | 0,02 | 10,52 |
| 8 | 0,24 | 6,24 | 18 | -0,11 | 10,89 |
| 9 | 2,53 | 9,03 | 19 | -0,91 | 10,59 |
| 10 | -0,13 | 6,87 | 20 | 1,42 | 13,42 |
Второй эксперимент также был успешным. Теперь а оказалось больше a, a b — несколько меньше р. В табл. 3.2 приведены оценки а и b при 10-кратном повторении эксперимента с использованием разных наборов случайных чисел в каждом варианте.
Можно заметить, что, несмотря на то что в одних случаях оценки принимают заниженные значения, а в других — завышенные, в целом значения а и
| Таблица 3.2 | ||
| Эксперимент | а | b |
| 1 | 1,63 | 0,54 |
| 2 | 2,52 | 0,48 |
| 3 | 2,13 | 0,45 |
| 4 | 2,14 | 0,50 |
| 5 | 1,71 | 0,56 |
| 6 | 1,81 | 0,51 |
| 7 | 1,72 | 0,56 |
| 8 | 3,18 | 0,41 |
| 9 | 1,26 | 0,58 |
| 10 | 1,94 | 0,52 |
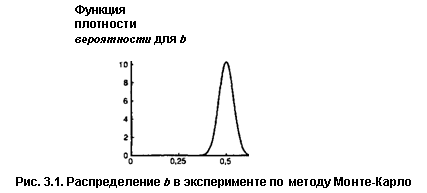 |
b группируются вокруг истинных значений аир, равных соответственно 2,00 и 0,50. При этом хороших оценок получено больше, чем плохих. Например, фиксируя значения b при очень большом числе повторений эксперимента, можно построить таблицу частот и получить аппроксимацию функции плотности вероятности, показанную на рис. 3.1. Это нормальное распределение со средним 0,50 и стандартным отклонением 0,0388.
Выше говорилось, что расхождения между коэффициентами регрессии и истинными значениями параметров вызваны случайным членом и. Отсюда следует, что чем больше элемент случайности, тем, вообще говоря, менее точными являются оценки.
Этот вывод будет проиллюстрирован с помощью второй серии экспериментов по методу Монте-Карло, связанной с первой. Мы будем использовать те же значения аир, что и раньше, те же значения х и тот же источник случайных чисел для генерирования случайного члена, но теперь будем брать
 |
значения случайного члена в каждом наблюдении. Последний выразим через и\i = 1, 2,п), значения которого равны удвоенному случайному числу: и = 2rnv и 20 = 2гп20. Фактически мы используем в точности ту же выборку случайных чисел, что и раньше, но на этот раз удвоим их значения. Теперь на основе данных табл. 3.1 рассчитаем табл. 3.3. Далее, оценивая регрессию между .у и х, получим уравнение:
р= 1,26 + 0,58х. (3.10) Это уравнение гораздо менее точно, чем уравнение (3.8).
| Таблица 3.4 | ||
| Эксперимент | а | b |
| 1 | 1,26 | 0,58 |
| 2 | 3,05 | 0,45 |
| 3 | 2,26 | 0,39 |
| 4 | 2,28 | 0,50 |
| 5 | 1,42 | 0,61 |
| 6 | 1,61 | 0,52 |
| 7 | 1,44 | 0,63 |
| 8 | 4,37 | 0,33 |
| 9 | 0,52 | 0,65 |
| 10 | 1,88 | 0,55 |
В табл. 3.4 приведены результаты всех 10 экспериментов при и' = 2гп. Мы будем называть это серией экспериментов II, а первоначальную серию экспериментов, результаты которых приведены в табл. 3.2, — серией I. При сравнении табл. 3.2 и 3.4 можно видеть, что значения а и b во второй таблице являются значительно более неустойчивыми, хотя в них по-прежнему нет систематической тенденции к занижению или завышению значений оценок.
Детальное исследование позволяет обнаружить важную особенность. В серии I значение b в эксперименте 1 было равно 0,54, и завышение оценки составило 0,04. В серии II значение b в эксперименте 1 равнялось 0,58 и завышение составило 0,08, т. е. оно было ровно вдвое больше, чем раньше. То же самое повторяется для каждого из 9 других экспериментов, а также для коэффициента регрессии а в каждом эксперименте. Удвоение случайного члена в каждом наблюдении приводит к удвоению ошибок в значениях коэффициентов регрессии.
Этот результат следует непосредственно из разложения b в соответствии с уравнением (3.6). В серии I случайная ошибка в b задается в виде Cov (х, H)/Var (х). В серии II она представлена как Cov (х, и')/Уаг (х), и
Соу(х,ц) = Соу(х,2и) = 2 Соу(х,и)
Var(x) Var(x) Var(x) ' "Л1>
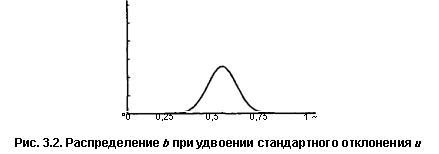
Увеличение неточности отражено в функции плотности вероятности для b в серии II, показанной на рис. 3.2. Эта функция вновь симметрична относительно истинного значения 0,50, однако если вы сравните ее с функцией, изображенной на рис. 3.1, то увидите, что данная кривая более полога и широка. Удвоение значений и привело к удвоению стандартного отклонения распределения.
Функция плотности вероятности для b
12 10
8
б
4
2

Обсуждение Введение в эконометрику
Комментарии, рецензии и отзывы