Использование сезонных фиктивных переменных
Использование сезонных фиктивных переменных
Исследователи, использующие данные временных рядов, в целом предпочитают погодовым данным сведения по кварталам по той простой причине, что за счет этого они получают в 4 раза больше наблюдений в рассматриваемый период. Вместе с тем иногда заметное воздействие на зависимость оказывает сезонный фактор. В этом случае желательно непосредственно принять его во вни
В табл. 9.4 представлены расходы потребителей на газ и электричество в США в постоянных ценах с I квартала 1977 г. по IV квартал 1982 г. Следует обратить внимание, что для обозначения кварталов года используются римские цифры I—IV. Ряд характеризуется небольшой тенденцией к повышению и сильными сезонными колебаниями. Как и следовало предполагать, расходы такого рода всегда значительно выше зимой, чем летом.
Произвольно возьмем I квартал года в качестве эталонной категории и будем использовать фиктивные переменные для оценки разницы между ним и другими кварталами. Запишем модель как
у = а + р/ + b2D2 + b3D3 + b4D4 + u, (9.26)
где Dv D3 и D4 — фиктивные переменные, определяемые следующим образом: D2 равно единице, когда наблюдение относится ко II кварталу, и нулю в остальных случаях; /)3 равно единице в III квартале и нулю в остальных случаях; D4 равно единице в IV квартале и нулю в остальных случаях.
Величины 52, 53 и 84 — их коэффициенты; они дают численную величину эффекта, вызываемого сменой сезонов. Коэффициент 52 показывает дополнительное потребление газа и электричества во II квартале относительно I квартала, связанное со сменой времени года. По аналогии с этим 83 и 84 показывают соответствующие дополнительные количества в III и IV кварталах относительно I квартала. Все эти «сдвиги» даются относительно I квартала, потому что он выбран в качестве эталонной категории.
 |
Полная совокупность наблюдений за расходами на газ и электричество, данные о времени и фиктивные переменные приведены в табл. 9.5. Оценив регрессионную зависимость расходов от времени и фиктивных переменных, получаем:
у = 7,50 + 0,030/ 2,78/)2 2,58/)3 2,19Z)4; R2 = 0,98. (9.27) (со.) (0,09) (0,005) (0,09) (0,10) (0,10)
Из этого результата мы выводим отдельные уравнения для каждого квартала:
у = 7,50 + 0,030/ (I квартал)
у = 4,72 + 0,030/ (II квартал) (9.28)
у = 4,92 + 0,030/ (III квартал)
Уравнения (9.28) можно графически проиллюстрировать (рис. 9.4). (Следует отметить, что в этом конкретном случае временной тренд настолько незначителен, что линии оказываются почти горизонтальными.)
При желании можно использовать оцененную регрессию для получения оценки сезонных колебаний в каждом квартале. Выражение (9.28) дает четыре отдельные линии регрессии. Усредняя их, получаем:
^ = 5,61 + 0,030/. (9.29)
Расстояние между отдельной линией регрессии для любого квартала и усредненной линией, которое представлено разностью значений постоянного члена
 у = 5,31 + 0,030/ (IV квартал)
у = 5,31 + 0,030/ (IV квартал)
О 5 10
—1—
15
20 t
Рис. 9.4. Сезонные колебания, смоделированные при помощи фиктивных переменных
в уравнении регрессии, дает оценку сезонных отклонений в этом квартале. Она составляет:
для I квартала: для II квартала: для III квартала: для IV квартала:
7,50 5,61 4,72 5,61 4,92 5,61 5,31-5,61
1,89; -0,89; -0,69; -0,30.
(Проверка: Сумма сезонных отклонений должна равняться нулю, и в данном случае это действительно так.)
Все г-тесты, относящиеся к коэффициентам при фиктивных переменных, показывают высокую значимость, как и F-тест для их совместной объясняющей способности. Суммы квадратов остатков в регрессиях с фиктивными переменными и без них равны соответственно 0,51 и 29,76; таким образом, F-стати-стика равна (29,25/3)/(0,51/19) = 363,2. Критический уровень ^сЗи 19 степенями свободы составляет 5,01 при однопроцентном уровне значимости.
Упражнения
9.4. В нижеследующей таблице приведены поквартальные данные о жилищном строительстве (кроме сельской местности) в США в течение периода 19771982 гг. (в миллиардах долларов, в ценах 1972 г.). Оценка регрессионной зависимости этого показателя от временного тренда и сезонных фиктивных переменных, определенных для II, III и IV кварталов, дала следующий результат (в скобках указаны стандартные ошибки):
9 = 13,69 + 3,02/)2 + 4,08/)3 + 3,00Д4 -0,3If; (со.) (0,65) (0,73) (0,73) (0,73) (0,04)
Л2 = 0,83.
Дайте полную интерпретацию регрессии.
9.5. Оцените уравнения регрессии аналогично тому, как это сделано в упражнении 9.4, используя данные для одного из видов потребительских расходов
 |
(табл. Б.З) и компьютер. Дайте интерпретацию полученных результатов и выполните соответствующие статистические тесты. Оцените регрессию еще раз без фиктивных переменных и выполните /'-тест для проверки их совместной значимости.
9.6. Предположим, что вы оцениваете регрессионную зависимость расходов на мороженое от располагаемого личного дохода, используя наблюдения по месяцам. Объясните, как вы введете совокупность фиктивных переменных для оценки сезонных колебаний.
9.3. Множественные совокупности фиктивных переменных
Может потребоваться включение в уравнение регрессии более одной совокупности фиктивных переменных. Это особенно часто встречается при работе со статистическими данными перекрестных выборок, когда могут быть собраны данные по ряду как качественных, так и количественных характеристик. При этом если четко определены рамки работы, то расширение использования в данном случае фиктивных переменных не представляет проблемы.
Мы поясним эту процедуру, используя пример с весом новорожденных. Предположим, что вы желаете исследовать воздействие семейного положения матери на вес при рождении, а также влияние того, рожала ли она раньше. Одинокие матери (матери, живущие на собственные средства независимо от того, состоят ли они формально в браке) как группа подвержены экономическим и социальным лишениям, что вызывает неблагоприятные последствия для течения беременности и развития ребенка. В странах с достаточно развитой системой социального обеспечения обычно прилагаются усилия, направленные на снижение такого неблагоприятного воздействия; в первую очередь, конечно, из соображений гуманности, но также и потому, что такая забота может снизить потребность в лечении после рождения ребенка и, следовательно, привести к экономии ресурсов. Указанием на успех или неудачу работы социальной системы в этом отношении может служить сравнение веса новорожденных, родившихся у одиноких матерей, с весом новорожденных, родившихся у замужних матерей, предполагая, что воздействие других характеристик является постоянным.
В данном контексте мы введем фиктивную переменную UM, которая по определению должна принимать значение 1 для одиноких матерей и 0 — для всех остальных. Мы определим также фиктивную переменную числа родов в прошлом (Z>), равную, как и раньше, единице для матерей, которые рожали в прошлом, и нулю для матерей, которые ранее не рожали.
При этой двойной классификации мы имеем четыре возможных случая с соответствующими комбинациями значений фиктивных переменных:
Замужняя мать, первые роды UM = 0; D = 0;
Одинокая мать, первые роды UM = 1; D = 0;
Замужняя мать, не первые роды UM =0; D = 1;
Одинокая мать, не первые роды UM = 1; D = 1.
Первый случай по смыслу является основной совместной эталонной категорией. Коэффициент при UM будет представлять собой оценку разности веса новорожденных, если мать одинока (мы ожидаем получить отрицательную величину). Коэффициент при D будет представлять собой оценку дополнительного веса при рождении, если ребенок не является первенцем. Ребенок в четвертой категории будет подвержен одновременно обоим воздействиям. Оценивание регрессии с использованием данных о 964 родах дает результат:
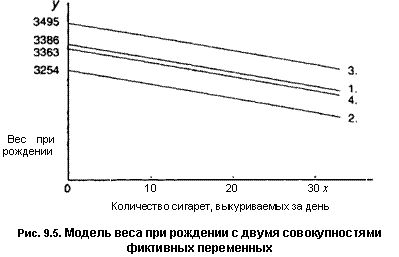
£ = 3386 + 109/)U2UM-7,2jc; R2 = 0,040. (9.30) (со.) (18) (27) (47) (2,1)
Используя четыре рассмотренные комбинации значений для D и UM, можно получить следующие подуравнения:
| 1.3> = 3386-7,2х; | |
| 2.^ = 3254-7,2*; | (9.31) |
| З.у = 3495 -7,2л:; | |
| 4. j> = 3363 -7,2*. |
Графическая иллюстрация этих уравнений представлена на рис. 9.5. Мы делаем вывод, что в совокупности, из которой была взята выборка, имеется значимая тенденция, согласно которой вес детей, рождающихся у одиноких матерей, меньше среднего веса.
Эту процедуру можно обобщить. В рассмотренном случае обе классификации качественной переменной имеют только две категории. На практике каждая классификация может иметь несколько категорий, и в этом случае в каждой классификации фиктивная переменная определяется для каждой категории, кроме эталонной категории. Например, если бы мы более подробно рассмотрели по категориям число родов у матери в прошлом в соответствии с классификацией, используемой в разделе 9.2, то аналог регрессии (9.19) после добавления фиктивной переменной для одиноких матерей имел бы вид:
9 = 3386 + 1182)1 + 902)2 + 922)3 32UM7,2х; Л2 = 0,041. (9.32) (со.) (18) (30) (49) (61) (47) (2,1)
 |
Упражнения
Дайте полную интерпретацию уравнения (9.32).
В свете данных, представленных в таблице, прокомментируйте результат оценивания регрессии, включающей только одну фиктивную переменную UM, определяемую в тексте:
j> = 3412 -169 И/; R2 = 0,014. (со.) (14) (47)
В частности, сравните этот результат с регрессией, показанной в уравнении (9.30).
| Количество в выборке | Процент матерей, которые рожают впервые | Процент матерей, курящих в период беременности | |
| Замужние матери | 881 | 58,7 | 21,6 |
| Одинокие матери | 83 | 80,7 | 42,2 |
9.4. Фиктивные переменные для коэффициента наклона
Мы пока предположили, что качественные переменные, введенные в уравнение регрессии, отвечают только за сдвиги в значении постоянного члена в уравнении регрессии. Мы неявно предположили, что наклон линии регрессии одинаков для каждой категории качественных переменных. Это предположение не обязательно верно, и теперь мы рассмотрим, как сделать его менее строгим и проверить, воспользовавшись инструментом, известным как фиктивная переменная для коэффициента наклона (иногда называемая также фиктивной переменной взаимодействия).
Для объяснения его использования вернемся к примеру с оцениванием регрессионной зависимости веса при рождении (у) от интенсивности курения матери (х) и фиктивной переменной числа родов в прошлом (Z>= 1, если мать рожала раньше; /)=0, если мать раньше не рожала):
y = a + bD + $x + u. (9.6)
В этой формулировке модели мы предполагаем, что воздействие курения матери на вес новорожденного одинаково, независимо от того, рожала ли мать раньше.
Предположим, что теперь мы добавим в уравнение член yDx — произведение D и х с коэффициентом у.
у = а + 8D + рх + yDx + и. (9.33)
Это можно переписать как
у = а + 6Z) + (Р + YD)x + и. (9.34)
Если D = 0, то коэффициент при х:, как и раньше, равен р. Если D = 1, то коэффициент приобретает вид (Р + у). Поэтому величина у может рассматриваться как разность между коэффициентом при показателе интенсивности курения для матерей, которые рожали раньше, и коэффициентом при показателе интенсивности курения для матерей, которые раньше не рожали.
Коэффициент у можно оценить, используя уравнение (9.33), где >> связан регрессионной зависимостью с Д х и Dx; показатель Dx, представляющий собой фиктивную переменную для коэффициента наклона, рассматривается как третья и отдельная объясняющая переменная. В табл. 9.6 показано, как вычисляется переменная Dx по 20 наблюдениям, приведенным в табл. 9.1.
Оценивание регрессии по данным выборки о 964 родах дает результат:
9 = 3363 + 143Z) 4,0* 8, IDx; R2 = 0,036. (9.35) (со.) (18) (29) (2,8) (4,1)
Положив D = 0 или D— 1, можно вывести два частных соотношения:
у = 3363 4,0* (для первенцев); (9.36)
у = 3506 12, х (для детей, рожденных не первыми). (9.37)
Результат оценивания регрессии показывает, что снижение веса новорожденного, связанное с курением матери в период беременности, значительно
больше для матерей, которые рожали раньше, чем для матерей, которые раньше не рожали (12,1 г на каждую сигарету в день против 4,0 г), и что различие значимо при уровне значимости в 5\%.
Взаимодействие между фиктивными переменными
Мы до сих пор предполагали, что воздействия качественных характеристик на зависимую переменную являются независимыми друг от друга. Например, в регрессии (9.30) предполагалось, что различие в весе при рождении для детей, родившихся у замужних и одиноких матерей, не зависит от того, рожала ли мать раньше, и наоборот. Мы можем сделать это предположение менее строгим за счет ввода фиктивных переменных взаимодействия, которые определяются по аналогии с фиктивными переменными для коэффициента наклона и имеют такое же назначение.
В рассматриваемом случае мы могли бы ввести фиктивную переменную взаимодействия (UMD), которая определяется как произведение UM и D и которая, следовательно, равна единице для одиноких матерей, рожавших раньше, и равна нулю для трех других комбинаций. Модель регрессии имеет вид:
у = а + 62) + yUM + XUMD + Рх + и, (9.38)
и ее можно переписать либо как
у = а + (5 + X UM)D + у UM + р* + и, (9.39)
либо как
у = а + &D + (у + XD) UM + рх + и. (9.40) Поэтому коэффициент X можно по выбору (оба альтернативных варианта экБивалентны) рассматривать либо как прирост коэффициента при фиктивной переменной числа предшествующих родов, если мать является одинокой, либо как прирост коэффициента для одиноких матерей, если мать рожала раньше.
Оценивание регрессии с использованием данных о 964 родах дает следующий результат:
£ = 3,385 + 113/)\7UM-72UMD-7,3x; 7?2 = 0,041. (9.41)
(со.) (18) (28) (52) (115) (2,1)
Мы видим, что коэффициент при фиктивной переменной взаимодействия значимо не отличается от нуля при уровне значимости в 5\%, и делаем вывод, что может не быть взаимодействия между переменной числа родов в прошлом и переменной для одиноких матерей. Однако следует отметить, что в выборке было только 16 одиноких матерей, которые рожали не в первый раз, и, следовательно, коэффициент при UMD имеет очень большую стандартную ошибку. Этот пример дает предупреждение о том, что даже если выборка большая, но имеется несколько совокупностей фиктивных переменных, то число наблюдений в отдельных подкатегориях может легко оказаться очень малым, и, следовательно, проведение удовлетворительных проверок гипотез может быть затруднено.
Упражнения
При использовании выборки, включающей данные о 964 родах, оценена регрессионная зависимость веса новорожденных (у) от интенсивности курения матери (х), фиктивной переменной (Z>), характеризующейся числом предыдущих родов, фиктивной переменной (М) пола ребенка (определенной как в упражнении 9.2) и фиктивной переменной для коэффициента наклона (Мх), определяемой как произведение Л/и х (в скобках указаны стандартные ошибки):
£ = 3312+ 124/)+ 108Л/-10,5х+5,7Л/х; У?2 = 0,057.
(23) (26) (28) (2,9) (4,1)
Прокомментируйте этот результат.
Та же самая регрессия повторно оценена с включением фиктивной переменной взаимодействия (DM), определяемой как произведение D и Л/(в скобках указаны стандартные ошибки):
у = 3304 + 144/) + 123Л/ 39DM 10,6* + 5,9х; R2 = 0,058.
(26) (38) (35) (53) (2,9) (4,1)
Прокомментируйте этот результат.
9.5. Тест Чоу
Иногда выборка наблюдений состоит из двух или более подвыборок, и трудно установить, следует ли оценивать одну объединенную регрессию или отдельные регрессии для каждой подвыборки. На практике проблема выбора стоит обычно не столь жестко, поскольку могут быть некоторые возможности объединения подвыборок при использовании соответствующих фиктивных переменных и фиктивных переменных для коэффициента наклона, чтобы сделать менее строгим предположение о том, что все коэффициенты должны быть одинаковыми для каждой подвыборки. К этому вопросу мы еще вернемся.
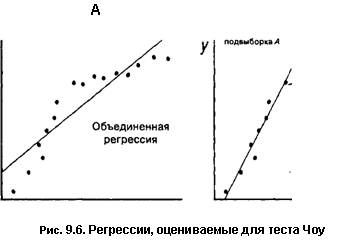
Предположим, что имеется выборка, состоящая из двух подвыборок, и что возникает вопрос, следует ли объединить их для оценивания общей регрессии Р или оценить отдельные регрессии А и В. Обозначим суммы квадратов остатков для регрессий подвыборок UA и UB. Пусть Uf и Uf — суммы квадратов остатков в объединенной регрессии для наблюдений, относящихся к двум рассматриваемым подвыборкам. Так как отдельные регрессии для подвыборок должны соответствовать наблюдениям по меньшей мере так же хорошо, если не лучше, чем объединенная регрессия, то UA < Uf и UB < Uf. Следовательно, (UA + UB) < Up, где общая сумма квадратов остатков в объединенной регрессии Up равна сумме Uf и Uf
Это поясняется на рис. 9.6. Предположим, что имеются данные временного ряда по двум переменным и что в период выборки произошло структурное изменение, разделяющее наблюдения на подвыборки А и В. На рис. 9.6Б регрессии для подвыборок обеспечивают вполне адекватное соответствие данным, обусловливая низкие значения UA и UB. Если бы требовалось оценить объединенную регрессию, как на рис. 9.6А, то остатки в обеих подвыборках в целом были бы значительно больше.
Равенство между Up и (UA + UB) будет иметь место только при совпадении коэффициентов регрессии для объединенной регрессии и регрессий подвыборок. В общем случае при разделении выборки будет наблюдаться улучшение качества уравнения, что можно представить как (Up UA UB). Это имеет свою цену: используются (к+ 1) дополнительных степеней свободы, так как вместо (к + 1) параметров для одной объединенной регрессии мы теперь должны оценить в сумме (2к + 2) параметров (к — число объясняющих переменных, единица соответствует постоянному члену). После разделения выборки, однако, остается необъясненная сумма квадратов остатков (UA + UB) и, кроме того, (п-2к~ 2) степеней свободы.
Б
 |
 У
У х
Теперь мы можем определить, является ли значимым улучшение качества уравнения после разделения выборки. Для этого используется .F-статистика:
Улучшение качества уравнения / Использованные степени свободы Необъясненная дисперсия / Число остающихся степеней свободы =
AUP-UA-UB)/{k + ) (UA + UB)/(n-2k-2)' <9'42)
которая распределена с (£+ 1) и (n — 2k—2) степенями свободы.
Теперь, например, давайте вернемся к случаю парной регрессионной зависимости веса новорожденных от интенсивности курения их матерей, и пусть мы еще не решили, следует ли объединять подвыборки, включающие 584 матери, которые ранее не рожали, и 380 матерей, которые ранее рожали. Оценивание объединенной регрессии и регрессий для подвыборок дает результаты, показанные в таблице.
| Выборка | Оцененное уравнение | R2 | Сумма квадратов остатков |
| Объединенная выборка | /=3418-7,2* (со.) (143) (2,1) | 0,012 | 158,6 x 106 (9.43) |
| Первенцы | £=3363-4,0* (со.) (18) (2,8) | 0,004 | 91,2X 106 (9.44) |
| Непервенцы | >> = 3506 12,1л-(со.) (23) (3,1) | 0,039 | 63,5 x 106 (9.45) |
Соответствующая F-статистика, следовательно, равна:
(158,6-91,2-63,5)/2 F " (91,2 + 63,5) /960 " 12Д* <9'46)
Критическое значение F с 2 и 960 степенями свободы составляет 6,91 (при уровне значимости в 0,1\%), поэтому мы делаем вывод, что не следует оценивать объединенную регрессию.
Регрессии для подвыборок идентичны регрессиям, представленным соотношениями (9.36) и (9.37), и это не простое совпадение. В основной регрессии (9.35) составляющая, не связанная с фиктивной переменной, включает постоянный член и показатель зависимости от интенсивности курения. К этому добавляются фиктивная переменная, позволяющая различать значения постоянного члена для первенцев и детей, родившихся не первыми, и фиктивная переменная для коэффициента наклона, также позволяющая различать коэффициенты при показателе интенсивности курения для двух рассматриваемых подвыборок. Следовательно, в (9.35) мы не задаем заранее какой-либо коэффициент одинаковым для обеих подвыборок и, таким образом, получаем такие же оценки коэффициентов, как и в отдельных регрессиях для подвыборок.
Рассматривая лишь соотношение (9.35), мы можем проверить, оправдана ли эта гибкость, выяснив, вносят ли указанные фиктивные переменные как группа значимый вклад в объясняющую способность уравнения. Сумма квадратов остатков, если фиктивные переменные не включены в уравнение, составляет 158,6 х 106, а когда они включены в уравнение, эта сумма равна 154,7 х 106. Следовательно, /'-статистика для проверки объясняющей способности фиктивных переменных как группы имеет вид:
(158,6 -154,7) /2 * 154,7/960 ^' <9-47>
т. е. она в точности такая же, как в тесте Чоу.
Можно показать, что это общий результат. Выбор между использованием рассмотренной процедуры теста Чоу или оцениванием сложной регрессии с фиктивными переменными на основе соотношения (9.35) будет зависеть от целей, которые ставит перед собой исследователь. Тест Чоу выполняется быстрее, и он достаточен, если требуется только установить, что зависимости в подвы-борках в некоторой степени различаются. Оценивание регрессии с фиктивными переменными более информативно в том отношении, что оно позволяет выполнять /-тесты с рассмотрением вклада каждой фиктивной переменной, а также всей группы в целом и может привести к компромиссу, в котором исследователь предполагает, что некоторые коэффициенты одинаковы в обеих подвыборках, и использует фиктивные переменные для дифференциации значений остальных коэффициентов.
Упражнения
Выполните тест Чоу, чтобы определить, имел ли место структурный разрыв зависимости расходов на автомобили от располагаемого личного дохода в 1973 г., используя данные табл. 9.2.
Исследователь, интересующийся воздействием особенностей национальной культуры на структуру потребления, предлагает 20 малайским, 20 китайским, 20 индийским и 20 другим семьям, живущим в Куала-Лумпуре, подробно записывать свои расходы на продукты питания в течение одного года. Кратко опишите преимущества и недостатки оценивания одной функции спроса, описанной уравнением с фиктивными переменными, для всех 80 семей в сравнении с оцениванием четырех отдельных уравнений для различных этнических групп.
Приложение 9.1
Качественные зависимые переменные
Может случиться так, что переменная, детерминанты которой требуется исследовать, является качественной по своему характеру. Например, в нашем исследовании в области акушерства можно рассмотреть вопрос оценки факторов, приводящих в критических обстоятельствах к необходимости родоразрешения путем кесарева сечения. Наша цель заключается в уменьшении частоты проведения такой операции, что важно само по себе и для снижения расходов на специальное оборудование для ухода за младенцами и т. д.
Упрощенный способ рассмотрения этой проблемы заключается в определении зависимой переменной emsec как фиктивной переменной и в оценивании регрессии обычным способом. Например, мы можем считать emsec равной единице, если родоразрешение проводилось путем кесарева сечения, и равной нулю, когда роды были нормальными. Используя данные о 964 родах, мы получаем следующий результат:
emsec = 0,08 0,08/) + 0,01о/</ + 0,07short + QfiSheavy 0,02c/ass + 0,01 MVf + 0,0018 х, (9.48)
где D — фиктивная переменная числа родов в прошлом (значение 1 — если мать рожала раньше, значение 0 — в других случаях); old — фиктивная переменная возраста (1 — когда матери 36 или более лет, 0 — в других случаях); short — фиктивная переменная роста матери (1 — если мать находится в низшем квинтиле по росту, т. е. имеет рост 157 см или меньше, 0 — в других случаях); heavy — фиктивная переменная веса матери (1 — если мать относится к верхнему квинтилю по весу, т. е. имеет вес 68 кг или больше, 0 — в других случаях); class — фиктивная переменная посещения занятий по предродовой подготовке (1 — если мать регулярно посещала эти занятия, 0 — в других случаях); UM — фиктивная переменная семейного положения (1 — если мать является одинокой, 0 — в противном случае); х — количество сигарет, выкуриваемых в день в период беременности.
Последние три переменные представляют интерес для социальной политики; остальные включены в уравнение, потому что, как известно, они имеют отношение к частоте проведения операции кесарева сечения, и если они не будут включены, это может привести к смещению оценок коэффициентов регрессии.
Прогнозируемое значение emsec для любого наблюдения показывает вероятность родоразрешения путем кесарева сечения, если даны значения параметров в правой части уравнения. Коэффициент при каждой переменной увеличивает вероятность кесарева сечения для матери с соответствующим параметром. Например, эта вероятность на 8\% ниже для матерей, которые рожали ранее, по сравнению с матерями, которые ранее не рожали.
Недостатки линейной вероятностной модели, как известно, связаны с тем, что ее случайный член не удовлетворяет обычным предположениям. В частности, он не распределен нормально, поэтому нельзя выполнить обычную проверку значимости. Кроме того, он может привести к появлению прогнозируемых значений зависимой переменной больше единицы или меньше нуля, что невозможно.
Для преодоления этих трудностей разработано несколько статистических методов, аналогичных методам построения линейной вероятностной модели, но основанных на других принципах. Возможно, наиболее широко известным из них является логит-анализ, основанный на методе максимального правдоподобия. Рассмотрение этого метода выходит за рамки данной книги, и дос-
таточно отметить, что его возможное использование на практике во многом Совпадает с практическим применением регрессионного анализа.
В рассматриваемом примере логит-анализ дает следующий результат (в скобках приведены ґ-статистики):
emsic = Константа 0,1 ID + 0,1 old + 0,Q5short + 0,05heavy (0 (-4,61) (3,46) (2,45) (2,27)
0,02с/<ш + 0,01 UM + 0,0025x (9.49) (-1,09) (0,33) (1,26)
(постоянный член не был вычислен при помощи использованного алгоритма). Уравнение показывает значимые воздействия первых четырех переменных, как это и ожидалось, но не показывает значимого влияния социальных переменных.

Обсуждение Введение в эконометрику
Комментарии, рецензии и отзывы