1.5. линейная модель множественной регрессии
1.5. линейная модель множественной регрессии
Рассматриваемая ниже линейная модель составляет основу эконометрики. Базируясь на определенном наборе допущений, изложим основополагающую процедуру эконометрического оценивания параметров этой модели — метод наименьших квадратов (МНК). Значительная часть стандартного курса эконометрики посвящена адаптации этого метода к ситуациям, в которых одна или несколько так называемых классических предпосылок не работают. Для того, чтобы предлагаемый обзор имел как можно более общий характер, далее в этой главе используется в основном матричная форма записи.
1.5.1. Классические допущения,
МНК и теорема Гаусса—Маркова
Пусть процесс, порождающий значения наблюдаемой переменной уп есть сумма линейной комбинации к объясняющих переменных xJt, 7 = 1, к и случайного отклонения ut:
Уі ~ Рл + Р2*2/ + Рз*з/ + + $kxkt + ut > f = V2,...,7 (1.21)
где р7 неизвестны.
Главная задача эконометрики состоит в том, чтобы получить «оптимальные» оценки неизвестных параметров зависимости (1.21). Имея исходный массив наблюдений {(уь хь х^ь х^), t— 1, 2, 7), можно от системы соотношений (1.21) перейти к записи в матричной форме:
7 = ZP + w, (1.22)
где
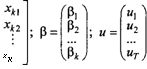 |
Y =
Уг
Ут)
; х =
Х\ Х2 Х3 Х2 х22 Х32
ХТ \%2Т ХЗТ
Таким образом, Y — вектор наблюдаемых значений зависимой (объясняемой) переменной размерности Txl ; X — матрица наблюдений объясняющих переменных («регрессоров») размерности Тхк р — вектор неизвестных коэффициентов размерности kxl; и — вектор ненаблюдаемых случайных отклонений (регрессионных ошибок) размерности Txl . Матрицу X иногда также называют «матрицей плана».
В классической линейной регрессионной модели вводится ряд допущений, позволяющих установить различные свойства эконо-метрических оценок коэффициентов.
1. Все случайные отклонения имеют нулевые математические
ожидания, одинаковые дисперсии а2 и являются взаимно некоррелированными:
E{u)=0, Var(w) = a2/.
2. Объясняющие переменные неслучайны и, таким образом, не зависят от случайных отклонений:
Е(Х'и) = 0.
3. Объясняющие переменные линейно независимы: гапк(ХХ) = гапк(Х) = к
и, следовательно, существует обратная матрица (Х'Х) 1.
Важно отметить, что до сих пор не было сделано никаких допущений относительно характера статистического распределения случайных отклонений. Также не говорилось, что отклонения распределены независимо (т.е. не требовалось, чтобы функция плотности их совместного распределения была равна произведению функций плотности отдельных отклонений), хотя при условии нормальности распределения это свойство следует из нулевой корреляции.
Оценка по методу наименьших квадратов (МНК-оценка) р для вектора р является результатом минимизации суммы квадратов остатков, получаемых при подстановке вместо неизвестных коэффицинтов р произвольного набора конкретных числовых
значений Ь:
S(b) = (Y-Xb)'(Y-Xb)-+ min. (1.23)
b є R
Необходимые условия экстремума (условия первого порядка) для функции (1.23) примут вид:
^ = -2X'(Y-Xb) = 0,
это выражение можно переписать в форме «нормальных уравнений»:
Х7 = Х'ХЬ (1.24) и, поскольку согласно допущению 3 матрица (Х'Х) невырожденная, то, решая уравнение (1.24) относительно й, получим оценку по методу наименьших квадратов:
$ = (Х'ХУ1ХГ. (1.25)
Выражение (1.25) описывает решение задачи минимизации (1.23), поскольку в точке Ъ = р выполнены достаточные условия экстремума (условия второго порядка):
d2S db db
7 = 2Х'Х,
где Х'Х — положительно определенная матрица.
Поскольку элементы матрицы X фиксированы, выражение
(XX)'1 XY можно интерпретировать как линейную функцию, которая отображает («проектирует») любой вектор Y из Г-мерного пространства в вектор р из А:-мерного пространства:
(ХХ)~Х X':RT ->Rk.
Соответственно, матрицу (XX)~lXf часто называют проекционной матрицей Рх. Полезно отметить, что РхХ-1. Очевидно,
что оценка fi = PxY —линейная функция от К Она также является несмещенной в том смысле, что математическое ожидание оценки р равно вектору истинных значений оцениваемых параметров р:
Еф) = ЩХХ)-1 XY] = Е[(ХХУ1 ХХ$ + и)] =
= р + (ЛГЯГ)"1£(ЛГ4|) = р, (1.26)
В сделанных преобразованиях использовано выражение РХХ = 1, а также допущение 2 (о неслучайности объясняющих переменных). Из уравнения (1.26) следует, что р является также линейной функцией ошибок и.
Ковариационная матрица вектора оценок Р легко вычисляется с помощью выражения р = р + Рх и :
Уаг(р) = эдр-рхМ)т^
= (XX)-lX'(c2l)x(XXyl =а2{ХХ)(1.27)
в преобразованиях использованы допущения 1 и J.
Можно показать, что при выполнении допущений і—3 для любой другой линейной несмещенной оценки р вектора коэффициентов р «дисперсия» р превосходит «дисперсию» р в том смысле, что [Var(P) Var(P)] — неотрицательно определенная матрица (теорема Гаусса—Маркова). Действительно, поскольку р — линейная оценка, ее можно записать в виде fi = AY, где А — матрица констант размерности к х Т.
Пусть С = А-(ХХ)~ХX', тогда очевидно, что
$ = [(XX)~lX' + C]Y =рї)_1Г + С](ір + «) = = $+Оф + [(ХХу1Х' + С]и.
Таким образом,
£(р) = р + ОГр.
Следовательно, поскольку оценка р должна быть несмещенной, то СХ = О. Тогда
Var(j3) = Еф PXP P)' = Щ5Г)~1І' + C]uu '[(Х'Х)'1 X' + C]' = = а2[(П)-1 + СС].
Следовательно,
Var(P>-Var(P)=<j2CC Итак, Var(P) превышает Var(P) на неотрицательно определенную матрицу. В частности, диагональные элементы матрицы <т2СС" неотрицательны, поэтому выполняются неравенства:
D(Py)-D(p.)>0; у = 1, к.
Таким образом, при выполнении допущений 1—3 каждая из МНК-оценок р • является наилучшей (имеет наименьшую дисперсию) в классе несмещенных линейных оценок параметра р..
1.5.2. Качество модели: коэффициент детерминации и дисперсия отклонений
Получив МНК-оценку р, мы можем представить вектор Y как
сумму «объясненной» составляющей Y и «необъясненной» составляющей и:
Y = X$ + u = Y + u. (1.28)
Один из способов определить, насколько хорошо предложенная модель согласуется с наблюдёнными значениями, состоит в том,
чтобы рассчитать долю вариации Y, объясняемую вариацией Y, и необъясняемую долю, связанную с вариацией остатков й. В качестве одной из мер разброса можно использовать YY — сумму квадратов значений уг Пользуясь уравнением (1.28), получим
Y7 = $X'X$ + u'u + 2$X'u. (1.29)
С помощью МНК-оценки р строится вектор остатков
u = Y-X$, который, как легко показать, ортогонален к объясняющим переменным:
X'u = X'(Y-X$)=X'[I-X(XXylX,]Y = 0.
Отсюда следует, что последний элемент в уравнении (1.29) равен нулю. Таким образом, величина ГУ может быть разбита на две составляющие, одна из которых выражена через объясняющие переменные, а другая не объясняется моделью:
YY = jl'XXJi + u'u = YY + u'u.. (1.30)
Однако обычно принято измерять разброс значений переменной вокруг ее среднего. Введем соответствующий показатель для переменной у — общую сумму квадратов отклонений (TSS, total sum of squares):
t=
-і т
где у = Т тогда
TSS = 7T-ry2. Вычитая Т у2 из выражения (1.30), получим
TSS = (YY-T у2) + й'й. (1.31)
Если модель содержит свободный член, то хи= для всех значений /, и первая строка системы нормальных уравнений (1.24) примет вид:
x[Y = x[J$ = Т$,
ГДЄ Х| = (Xj | ,Xj2,Хц) =(1, 1, 1),
тогда у = Т~х S yt = Т~хх[Х$ = Г"1 £ у, = J.
Таким образом, первое слагаемое из правой части уравнения (1.31), стоящее в скобках, измеряет разброс значений объясняемой
части Y, т.е. Y, вокруг своего среднего значения или объясненную сумму квадратов отклонений (ESS, explained sum of squares). Легко показать, что остатки, полученные с помощью МНК, имеют нулевое среднее значение, поэтому второй член, стоящий справа в уравнении (1.31), отражает разброс значений необъясняемой моделью части Y, т.е. й, вокруг своего нулевого среднего или необъяс-ненную (остаточную) сумму квадратов (USS, unexplained sum of squares):
TSS = ESS + USS, (1.32)
где ess = £cp,-J02; uss=.£*,2.
t= t=
Коэффициент детерминации, или R2 , измеряет долю объясненной дисперсии (ESS) в общей дисперсии (TSS) зависимой переменной:
Я2 = ESS=1_.USSe (133) TSS TSS
Очевидно, что 0<R2 <1. Коэффициент R2 показывает качество подгонки модельных значений yt к фактически наблюдённым
значениям yt . Чем R2 ближе к единице, тем лучше подгонка по
модели регрессии.
С ростом числа регрессоров коэффициент детерминации Л2 не может убывать, в большинстве случаев он возрастает. В этом плане
R2 не совсем удобен при сравнении нескольких регрессионных уравнений. Последнее является основанием для рассмотрения подправленного {adjusted) коэффициента детерминации R2dJ , в котором делается корректировка на число степеней свободы, «неучтенных» при конструировании R2: к степеней свободы используют для коррекции величины ESS (по числу параметров, которые потребовалось оценить для его вычисления) и одну степень свободы — при расчете TSS (из-за наличия величины^, оценивающей среднее значение у).
Подправленный коэффициент детерминации задается формулой:
R2 Ш8/(Г-*)=1 u'uKT-k)
adj TSs/(r-l) (уГ-Ту2)І(Т-)
или Л^=-1_(1_Л2)Х^1
1.5.3. Дисперсия отклонений
Несмещенная оценка дисперсии отклонений ст обычно обозначается как s2:
s2 = й'й 1(Т -к).
Докажем, что s2 — действительно является несмещенной оценкой ст2. Пусть М = 1Х(ХХ)~Х X', тогда й = Y-X$ = (Х$ + и)-(Х$ + ХРхи) = (I-ХРХ)и .
Таким образом, й = Ми , где М = 1 ХРХ.
Очевидно, что матрица М симметрична (М = М') и идемпо-тентна [м2 = м|. Следовательно, й и и'М'Ми = и'Ми, откуда
s2 — и'Ми 1{Т — к). (1.35)
Поскольку величина s2 — скаляр, то она, очевидно, равна своему следу1. Пользуясь свойствами следа, получим:
E(s2) = E[tr[u'Mu]/(T к)] = = tr[M • Еии'] l(T -к) = tr[Ma2/] /(Г к) = = о2(Ш)/(Т-к).
Поскольку trM = trIT ЪХ(ХХу[ Х' = Тtr(XX)_l XX Т trlk = = Т-к9 то
E(s2) = o2. (1.36)
Таким образом, s2 является несмещенной оценкой а2. Можно показать, что если из двух регрессионных моделей одна является истинной, то математическое ожидание s2 для истинной
модели не превышает математического ожидания s2 для альтернативной модели. Действительно, пусть Y Х$ + и является истинной моделью, a y = Zy + w — альтернативная модель, где X и Z — матрицы размерностей Тхкх и Txkz соответственно, а X содержит
по меньшей мере одну переменную, не включенную в Z . Пользуясь тем, что для первой модели
й = Y Хр = Y X(PXY) = (I ХРХ )Y = MXY9 где Мх =І-Х(ХХУ1Х получим
s2x=YMxY/(T-kx). Аналогично, для второй модели имеем
s2z~Y'MzYI(J-kz
1 Напомним, что следом квадратной матрицы А называется число tr04), равное сумме элементов, стоящих на главной диагонали матрицы. Для матриц А и В размерностей к х пи п х к, соответственно, выполняется свойство:$г(АВ) ti(BA).
где М2 = / Z(Z'Z)-1 Z' .
Отсюда следует, что
(Г-kz)E(s)~ E(Y'MZY) = E[(X$ + u)'Mz(X$ + u)] = = pX'MzX$ + E(u'Mzu) =pXfMzX$ + (T-kz)o2 >(T-kz)c2.
Следовательно, E{sz)><32, и, учитывая несмещенность оценки s2x в «истинной модели», получим
£(4)>£(4). (1.37)
Соотношение (1.37) иногда используют для обоснования стратегии выбора спецификации, максимизирующей R2, поскольку из
ии выбора спецификации, уравнения (1.33) следует, что
*2=1-^^, (1.38)
где s2 — выборочная дисперсия yt.
Последнее соотношение показывает, что отбор переменных, направленный на минимизацию s2, одновременно ведет к максимизации R2.
1.5.4. Линейные ограничения
Предположим, что в соответствии с некоторой экономической теорией, лежащей в основе рассматриваемой модели, параметры р
этой модели должны удовлетворять одному или нескольким линейным ограничениям. Тогда желательно, что^ы и оценки параметров тоже удовлетворяли этим ограничениям.
Любой набор линейных ограничений можно записать в виде:
R$ = r9 (1.39)
где R — матрица размерности q х к; q — число ограничений; г —
вектор размерности q х 1.
Нет смысла рассматривать систему несовместных ограничений. Также не следует включать в число ограничений те, которые можно представить в виде линейных комбинации других. Поэтому разумно считать, что q < к, гапк(Л) = q.
Если, например, в модели с тремя параметрами, необходимо получить вектор оценок р = (Р}, р2, Рз)', удовлетворяющий ограничениям
Р1=2; р2+рз=1, (1.40)
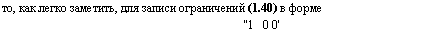
0 1 1
(1.39) достаточно ввести матрицу R =
1.5.5. Оценивание с учетом линейных ограничений
МНК-оценка РЛ, учитывающая ограничения на коэффициенты
(restricted least squares estimator), получается в результате решения задачи условной оптимизации — на этой оценке сумма квадратов остатков достигает минимума в множестве всех р, удовлетворяющих условию (1.39). Общеизвестным способом решения такой задачи является нахождение безусловного минимума функции Лагранжа:
L = (YX$)'(Y Х$) + 2А/(др г) -> min, (1.41)
где к — вектор множителей Лагранжа размерности q х 1. Условие первого порядка для (1.41) записывается в виде
^ = -2XY + 2X'X$ + 2R'X = 0; (1.42)
JL = *p-r = 0. (1.43)
ok
Умножая равенство (1.42) на R(X'X)~X и учитывая условие
(1.43), получим
[R(X'XYXR']k = R(X'XylXY-R$ = R$-r , (1.44)
где P = P^ =(X'X)~] XY— безусловная (unrestricted) МНК-оценка. Теперь легко получить, что вектор к выражается в виде
k = [R(X'Xy]RT]W-r), (1.45) Подстановка полученного выражения в уравнение (1.42) и умножение на (Х'Х)~Х приводит к МНК-оценке, учитывающей ограничение:
Ря =^-(XXylR,[R(XXylR,Yl(R^-r). (1.46)
Если ограничение справедливо и все классические предпосылки регрессионной модели выполняются, то вектор Rfi-г будет мал,
поскольку для оценок, полученных с помощью обычного МНК, ограничения будут почти верны (с ростом объема выборки компоненты вектора Rfi-r по вероятности стремятся к нулю). Далее, из соотношения (1.46) следует, что МНК-оценки, учитывающие ограничения, и безусловные МНК-оценки будут приблизительно совпадать.
Таким образом, чем больше отличаются оценки р и рл, тем меньше оснований верить в справедливость рассматриваемых ограничений. Для формализации этих интуитивных соображений сделаем ряд дополнительных допущений.
1.5.6. Распределение МНК-оценки и проверка гипотезы о линейных ограничениях
Выше мы сформулировали три классических требования, которые использовались для вывода некоторых свойств МНК-оценок. Одно из них состояло в том, что вектор регрессионных отклонений имеет нулевое математическое ожидание (Щи) = 0) и стандартную (так называемую «скалярную») ковариационную матрицу
(Var(w) = а2/) . Для того, чтобы продвинуться дальше, например для
вывода закона распределения МНК-оценок и тестирования гипотез, необходимо сделать дополнительные предположения о статистическом распределении отклонений.
Обычно предполагается, что вектор и имеет многомерное нормальное распределение с параметрами — нулевым вектором средних и скалярной ковариационной матрицей:
и~Щ0,о21), (1.47)
другими словами, предполагается, что процесс ut является гауссовским белым шумом.
Согласно второй классической предпосылке о детерминированности элементов матрицы X, из (1.47) непосредственно следует, что вектор У также имеет нормальное распределение:
Y~N(Xp,o2I). (1.48)
Поскольку МНК-оценка вектора р представляет собой линейную функцию от У, она тоже должна быть нормально распределенной с параметрами, вычисленными в (1.26) и (1.27):
р~#(р, с2(Х'ХТ1). (1.49)
Итак, при выполнении классических предположений и (дополнительно) нормальности распределения регрессионных отклонений uy u2, ut МНК-оценка р распределена нормально с математическим
ожиданием яр = р и ковариационной матрицей Var(P) = а2(Х Х)~х. Для вычисления ковариационной матрицы нужно знать дисперсию а2 регрессионных отклонений, однако последняя обычно неизвестна. Поэтому а2 заменяют на величину s2, задаваемую соотношением (1.35) и являющуюся, как было показано ранее, несмещенной оценкой для а2. Таким образом, получается несмещенная оценка ковариационной матрицы:
Уаг(р) = 52даГ1. (1.50)
Мы можем применить эту оценку при тестировании гипотезы о линейных ограничениях, рассмотренной выше. Предположим, что мы хотим оценить следующую нулевую гипотезу:
#0:Др-г = 0, (1.51)
где R — матрица размерности qx к; г — вектор q х 1; 0 — нулевой вектор qx I.
Как уже говорилось, если ограничение (1.51) выполняется, то следует ожидать, что вектор (R$-r) будет близок к началу координат. Пользуясь нормальностью распределения МНК-оЦенки р легко найти распределение Rfiг :
(Яр г) ~ N(0, G2R(XX)'1 R'). (1.52)
Эта запись означает, что величина, стоящая слева от знака « ~ », имеет при выполнении нулевой гипотезы указанное распределение. Из близости вектора (Лр-г) к нулю следует, что квадратичная форма
-^(R$-r)'(R(X'XrlRrl(RP-r) (1.53) а
будет также близка к нулю.
Нам потребуется известный результат из курса математической статистики, представленный ниже без доказательства. Если вектор случайных величин z ~ N(0, £) имеет многомерное нормальное распределение с невырожденной ковариационной матрицей порядка q х q9 то случайная величина у} = z' Z"1 z имеет распределение \%2(q).
В соответствии с (1.52) вектор Лрг имеет ^-мерное нормальное распределение, причем из условия rank R—q следует, что его ковариационная матрица не вырождена. Поэтому величина, опре-
деленная квадратичной формой (1.53), имеет \%2распределение с q степенями свободы:
(R$-r)mx'XTxRrRb-r) ~\%2Ш (1.54) а яо
Так как значение а2 обычно неизвестно, то выражение (1.53) не вычислимо. Поэтому взамен а2 разумно использовать несмещенную оценку s определенную в (1.35). Однако, поскольку s2 сама является случайной величиной, то такая замена в (1.54) приведет к распределению, отличному от х2 • Ниже мы получим это распределение.
Найдем вначале распределение величины s2 . Для этого воспользуемся еще одним известным результатом математической статистики: для произвольной идемпотентной матрицы М и стандартного тауссовского вектора є ~ N(0, I) величина у} = є'Мє имеет ^-распределение с числом степеней свободы, равным рангу матрицы М.
Как было показано в параграфе 1.5.3, й = Ми9 где М = 1Т--Х(ХХ)~l X' — симметричная идемпотентная матрица, а 1Т — единичная матрица порядка Т. Из (1.47) следует, что — N(0, I) — СТаН-СТ
дартный Г-мерный гауссовский вектор. Легко видеть, что
ий и'М'Ми и'М2и и,и 2,
-г = z = z— --М х (rank М).
а а2 а2 а а
Кроме того, по свойству идемпотентных матриц1:
rank М = trM = T-k.
Учитывая независимость оценки s2 =й'й/(Т-к)и вектора МНК-оценок р, имеем:
(T-K)s2/o2 ~Х2(Т-К). (1.55) Из выражений (1.53), (1.54) и (1.55) получаем (Д Р rY[R(XX)R'](R$ -r)lq
„F(q,T--K). (1.56)
1 См. также вывод соотношения (1.36).
зо
Конечно, выражение (1.56) может показаться довольно громоздким, однако оно не содержит неизвестных величин и может быть непосредственно вычислено по имеющимся выборочным наблюдениям. Кроме того, при условии нормальности случайных отклонений и справедливости ограничений на параметры, это выражение подчиняется известному, затабулированному распределению. Наконец, по величине (1.56) можно судить о степени соответствия между имеющимися наблюдениями и ограничениями на параметры — если ее значение слишком велико (превосходит некоторый порог), то с большой долей уверенности можно утверждать, что ограничения не выполняются. Таким образом, величину (1.56) можно использовать в качестве критической статистики при проверке гипотезы о линейных ограничениях.
Ниже приводится удобный способ вычисления данного выражения. Из соотношения (1.46) для МНК-оценок (Зл, учитывающих ограничения, следует, что
XX($-$) = R'[R(XX)-lR-lYl(R$-r). (1.57)
Так как (Зл должна удовлетворять ограничению RfiR = г , то
^лр-гу = (лр-лрлу = (р-рлул'.
Умножив (1.57) слева на (р-рд)', получим
(р ря УХХФ ft,) = (Др r)'[R(XXyl R'T1 (ДР г). (1.58)
Теперь рассмотрим сумму квадратов остатков в модели с ограничениями (e'ReR) и сумму квадратов остатков в модели без ограничений (e'UReUR):
eReR=(Y-XpR)'(Y-XPR); (1.59)
4jr*ur =(Y-XmY-XP) = (T-k)s2. (1.60) Преобразуем выражение (1.59):
e'rer=(Y-XV + XV-XVRy(Y-Xp + XV + xpR)= (l61) = (Y xfoXY Jrp) + (P ря УХХф ря).
Здесь мы воспользовались ортогональностью величин Хи й, т.е. равенством Х'й = X'(YJfp) = 0 . Из (1.60) и (1.61) получим или, используя (1.58),
-е'иеи = (RV-ry[R(XXrRT(RP-r).
Следовательно, критическая статистика (1.56) может быть записана по-другому:
(^7^^-^г"*)(1б2)
erer/(T-k) Яо
Формула (1.62) легко интерпретируется. Так как вектор МНК-оценок в модели без ограничений минимизирует сумму квадратов остатков, то наложение ограничений приводит к увеличению суммы квадратов. Таким образом, выражение в левой части (1.62) показывает относительную величину прироста суммы квадратов, приходящуюся на одно ограничение.
Мы будем отвергать гипотезу об ограничениях, в случае если критическая статистика свидетельствует «о слишком большом» увеличении суммы квадратов. Пороговое значение критической статистики, превышение которого свидетельствует о несправедливости гипотезы, определяется из таблиц /'-распределения, соответствующих заданному уровню вероятности ошибочного решения.
1.5.7. Доверительные интервалы
Рассмотрим снова выражение (1.56). В условиях справедливости нулевой гипотезы (1.51) для истинных значений параметров р выполняется равенство г = Яр, тогда (1.56) можно представить в виде:
Через Fa(q, Т-к) обозначим 100а-процентную точку ^-распределения (где а — уровень значимости критерия), т.е. такую величину, при которой P{F(q, Т-к)> Fa(q, Т к)} = а . Геометрически это означает, что область между осью абсцисс и графиком функции плотности распределения случайной величины F(q, Т-к), расположенная справа от точкиF^(q, Т-к), имеет площадь а. С помощью процентной точки можно построить 100(1 -а)-процентный доверительный эллипсоид:
P^-mxR(xx)-RrR(^^)^FaiqT_k)]=l_a (1б4)
Дадим интерпретацию выражения (1.64). Предположим, у нас есть возможность многократной генерации выборки наблюдений (X, Y) в соответствии с моделью (1.22), причем для получения реализаций вектора Y используется одна и та же матрица значений регрессоров 1и одни и те же (истинные) значения коэффициентов р, но разные векторы случайных отклонений и. Тогда вектор Y от выборки к выборке будет, вообще говоря, меняться,
и, следовательно, будут получаться разные значения оценки р ,
что позволит получить эмпирическое распределение для р . Вопрос о несмещенности и эффективности МНК-оценок, обсуждавшийся ранее, фактически сводится к вопросу о среднем значении и дисперсии этого выборочного распределения. Представим себе теперь, что по каждой из выборок на основе неравенства, стоящего в фигурных скобках в выражении (1.64), построена область в ^-мерном евклидовом пространстве. Соотношение (1.64) означает, что приблизительно в 100(1-а) процентах случаев от числа сгенерированных выборок полученная область будет содержать истинное значение р.
Интересен специальный случай, когда R — единичная матрица.
Тогда выражение (1.64) принимает вид:
р^-М*!т-№^а(д, r-*)j = l-a. (1.65)
Это значит, что для 100(1-а) процентов повторных выборок
вектор истинных значений параметров р будет содержаться внутри
эллипсоида, лежащего в ^-мерном евклидовом пространстве и заданного неравенством в фигурных скобках соотношения (1.65).
Другой интересный случай, когда R является ^-мерной строкой с единицей на у-ом месте и нулями на остальных местах. Тогда выражение (1.64) будет иметь вид:
з2[(ХХу\% J
где [ .. означает (у,у)-й (т.е. диагональный) элемент матрицы, заключенной в квадратные скобки.
Пользуясь тем, что квадрат случайной величины t (Т — к), имеющей распределение Стьюдента, описывается распределением Фишера F (I, Т — к), можно записать: или
■P&j-ty(T-K)se$j)*$j <ру +^(Г-ВДру)} = 1-а. (1.67)
Переходя от (1.66) к (1.67), мы воспользовались обозначением стандартной ошибки se($j) для оценки Ру , равной квадратному
корню у-го диагонального элемента матрицы s2(XX)~l, и получили двусторонний доверительный интервал. Пусть, например, Г — к = 60, тогда по таблице процентных точек /-распределения длр 5-процентного уровня значимости найдем /а/(60) = 2 и интервал
/2
[$j + 2se($j), Ру±2^(Ру)], указанный в соотношении (1.67), в среднем
для 95\% повторных выборок, будет содержать истинное значение Р7.
Следует отметить различия между проверкой каждого ограничения по отдельности и проверкой совместного выполнения всех ограничений. Рассмотрим, например, отдельные нулевые гипотезы На: р, = 0 и Hb: р, =0 и совместную нулевую гипотезу
Нс: (р,,р7) = (0, 0)
Допустим, что в 100(1-а) процентах случаев доверительные области как для р, так и для Р7 содержат ноль. Поэтому мы не сможем отклонить ни гипотезу На, ни гипотезу Нь на 100а-м уровне значимости. Однако может так оказаться, что двухмерный 100(1-а)-процентный доверительный эллипс для р, и Р7 не содержит начала координат, так что гипотезу Нс придется отвергнуть
на уровне значимости а (т.е. несмотря на то, что мы не можем отвергнуть гипотезу о равенстве одного из коэффициентов нулю, мы сможем отвергнуть гипотезу о совместном равенстве нулю двух коэффициентов).
Построим теперь совместный доверительный эллипс для р, и р7.
Пусть R — матрица размерности 2 х к с (1, /)и (2, у)-элементами, равными единице, и нулями на остальных местах. Обозначив через
Cov(P/5Py) оцененную ковариацию оценок р, и Р7, стоящую на (/,у)-м месте матрицы s2(XXyl, а арифметические квадратные корни /-го и у-го диагональных элементов этой матрицы как se($f) и se(fij), распишем выражение (1.64):
Р{(1/2ХР, Р/)2^Р/)2 +(1/2ХР> -руМР/ + ■
(168)
+ (P/-p/XP/"Py)Cov(p/>py)^Fa(2> T-k)} = l-a.
Область, описанная неравенством, стоящим в фигурных скобках левой части (1.68), — это эллипс с центром в точке (Р,, р.). Если
допустить, что Cov(P/,P/) =0, то область, задаваемая (1.68), будет прямоугольником с центром (Р,, Ру) и сторонами, равными длинам частных доверительных интервалов, построенных для р, и аналогично (1.67) с уровнями доверия 100(1-а). Однако если известно, что р, и Р7 имеют положительную ковариацию, тогда переоце-ненность (недооцененность) р, будет возникать Одновременно с переоцененностью (недооцененностью) Р7. Это позволяет исключить окрестности угловых точек прямоугольника и получить эллипс, соответствующий совместной доверительной области с уровнем доверия (1 а).
Непосредственно также можно построить доверительную область для постоянной дисперсии случайных отклонений а2. Из выражения (1.55) известно, что (T-k)s2/a2 имеет \%2-распределение с Тк степенями свободы. Пусть \%2 а(Т-к) и \%2а(Т-к) определяют
]~2 2
соответственно (1 у)100и — 100процентные точки ^-распределения с Т— к степенями свободы, тогда
р2 <?~к* ^ 2(Т~к)*2 }. (1.69)
гТ-к, l-a/2) х2(Т.-к, а/2)

Обсуждение Моделирование экономических процессов
Комментарии, рецензии и отзывы