2 введение в линейную модель регрессии
2 введение в линейную модель регрессии
Одним из краеугольных камней эконометрики является так называемая линейная модель регрессии и обычный метод наименьших квадратов (МНК). В первой части этой книги мы рассмотрим линейную модель регрессии с ее предположениями, как эту модель можно оценить и как ее можно применить для проверки экономических гипотез и построения прогнозов.
В отличие от многих учебников я не излагаю статистическую модель регрессии, начиная со стандартных предположений Гаусса-Маркова. С моей точки зрения при первом обсуждении самого важного метода эконометрики, обычного метода наименьших квадратов, роль предположений, лежащих в основе линейной модели регрессии, лучше всего понимается с помощью алгебраических, а не статистических средств. Этой теме посвящается раздел 2.1. Затем в разделе 2.2 вводится линейная модель регрессии, в то время как в разделе 2.3 обсуждаются свойства МНК-функции оценивания ("estimator")
В английском языке "an estimator" — это функция от результатов наблюдения, используемая для оценивания интересующего нас параметра, в то время как "an estimate" — это численное значение соответствующей оценки, полученное для заданных значений имеющихся наблюдений. В русском языке и то, и другое понятие определяется словом «оценка». В дальнейшем там, где это не вызывает путаницы этих двух понятий, мы будем использовать для перевода и "an estimator", и "an estimate" слово «оценка» (прим. научн. ред. перевода).
этой модели при так называемых предположениях Гаусса—Маркова. В разделе 2.4 обсуждаются меры качества приближения данных линейной моделью, а в разделе 2.5 рассматривается проверка гипотез. В разделе 2.6 мы переходим к случаям, когда свойства Гаусса-Маркова не обязательно удовлетворяются и неизвестны свойства МНК-оценок при малых выборках. В таких случаях, чтобы аппроксимировать свойства МНК-оценок при малых выборках, обычно используется предельное (асимптотическое) поведение этой оценки, когда, гипотетически, объем выборки становится бесконечно большим. В разделе 2.7 представлен эмпирический пример модели ценообразования финансовых активов (ЦФАМ). В разделах 2.8 и 2.9 обсуждаются соответственно мультиколлинеарность и прогнозирование. Для иллюстрации главных проблем на всем протяжении используется эмпирический пример, касающийся заработной платы молодых рабочих. В главе 3 проводится дополнительное обсуждение, как интерпретировать коэффициенты линейной модели, как проверить некоторые из модельных допущений и как сравнивать альтернативные модели.
2.1. Обычный метод наименьших квадратов как алгебраический инструмент
2.1.1. Обычный метод наименьших квадратов (МНК)
Предположим, что мы имеем выборку из N наблюдений по заработной плате и некоторым основным характеристикам. Мы заинтересованы в ответе на главный вопрос, как в этой выборке заработная плата связана с другими наблюдаемыми переменными. Обозначим заработную плату через у, а другие К — 1 переменных через #2, • • • ? хкНиже станет ясным, почему такая нумерация переменных удобна. Теперь мы можем задать вопрос: какая линейная комбинация #2 ? • • • ? \%к с константой дает хорошую аппроксимацию для у? Чтобы ответить на этот вопрос, сначала запишем произвольную линейную комбинацию, включая константу, в виде
Pi + Р2\%2 + . . . + РкХК
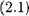
где Рк являются константами, которые должны быть подобраны. Проиндексируем наблюдения через г, так что г = 1,... , N. Теперь, разность между наблюдаемым значением и его линейной аппроксимацией равна
Уг ~ [01 + 02X12 + . . . + РкХік] . (2.2)
Чтобы упростить выводы, мы введем некоторую краткую систему обозначений. Для читателей, не знакомых с применением векторной системы обозначений, подробности дополнительно предоставляются в Приложении А. Сначала мы объединяем х-значения для индивидуальных і в вектор Хі, который включает константу. То есть,
Хі = (1 Хі2 Хіз ... ХікУ
Объединяя коэффициенты /3 в К-мерный вектор /3 = (/Зі, ... , (ЗкУ, мы можем кратко записать выражение (2.2) в виде
Уг-х'ф. (2.3)
Ясно, что мы хотели бы подобрать такие значения для констант •Зі, ... , Ркч чтобы разности (2.3) были малыми. Хотя можно использовать разные критерии, чтобы определить, что мы подразумеваем под понятием «малые», однако самый общий подход состоит в выборе такого вектора констант /3, что сумма квадратов разностей была бы как можно меньше. Мы определяем вектор (3, таким образом, чтобы минимизировать следующую целевую функцию:
N _
S(/?) = J>«-s'«/?)2. (2.4)
1=1
Этот метод называется обычным методом наименьших квадратов или МНК. Возведение в квадрат разностей гарантирует, что при суммировании положительные и отрицательные разности не погашают друг друга.
Чтобы решить проблему минимизации, мы можем обратиться к условиям первого порядка, полученным дифференцированием S((3) по вектору /?. (В Приложении А приводятся некоторые правила дифференцирования скалярных выражений, подобных выражению (2.4), по вектору.) Условия дают следующую систему из К уравнений:
N
-2]Г*г(уг-*;/?)=0, (2.5)
г=1
или
, N ч N
(Х>**і)0 = ]С*іїк(2-6)
М=1 ' г=1
Эти уравнения иногда называются системой нормальных уравнений. Поскольку система имеет К неизвестных, то можно получить единственное решение для вектора констант (3 при условии, что
N
симметрическую матрицу Х{х, которая содержит суммы квадраті
тов и перекрестных произведений регрессоров Хг, можно обратить. В настоящий момент мы предположим, что это так. Решение проблемы минимизации, которое мы обозначим через Ь, тогда имеет вид
, N ч-1 JV
Ь = ( XiXi ) £ ХіУі' (2*7)
м=1 ' 1=1
Проверкой условий второго порядка, легко убедиться, что вектор Ь действительно соответствует минимуму.
Получающаяся в результате линейная комбинация х^, таким образом, задается как
и эта комбинация является наилучшей линейной аппроксимацией для переменной у по переменным Х2,...,хх и константе. Выражение «наилучшей» относится к тому факту, что решение методом наименьших квадратов Ь приводит к минимальной сумме квадратов разностей (ошибок аппроксимации).
При выводе линейной аппроксимации мы не использовали никакой экономической или статистической теории. МНК — это всего лишь алгебраический инструмент и он применяется независимо от способа порождения данных. Таким образом, при заданном множестве переменных мы всегда можем определить наилучшую линейную аппроксимацию для одной переменной, используя другие переменные. Единственное предположение, которое мы должны были сделать (которое непосредственно проверяется на данных), состоит
N
в том, что К х К матрица Х{х обратима. Это значит, что ни
г=1
одна из переменных Х{ не является точной линейной комбинацией других переменных и, таким образом, не является избыточной. Такое предположение обычно называется предположением «отсутствия мультиколлинеарности». Следует подчеркнуть, что линейная аппроксимация является внутривыборочным результатом (то есть, в принципе она не дает информацию о наблюдениях (индивидуумах), которые не представлены в выборке), и прямая интерпретация коэффициентов отсутствует.
Несмотря на эти ограничения алгебраические результаты по методу наименьших квадратов очень полезны. Определяя остаток Єі как разность между наблюдаемым и аппроксимированным значением, ег — уг — уг — уг — х'гЪ, мы можем разложить наблюдаемое значение Уі в виде
Уг = Уг + Єі = хЬ + Єі. (2.8)
Это позволяет нам записать минимальное значение целевой функции как
N
ЗД = 5>2, (2-9)
1=1
которое называется остаточной суммой квадратов. Можно показать, что аппроксимированное значение х[Ъ и остаток удовлетворяют определенным свойствам, как говорится, по построению. Например, если мы перепишем выражение (2.5), подставляя МНК-оценки Ь, то мы получим
N N
J2 *г{Уг " Xjb) = J2 Х^ = 0(2Л0)
г=1 г=1
Это означает, что вектор е = (ei,... , eyv)' ортогонален ^ каждому вектору наблюдений Хі векторной переменной х. Например, если вектор Хі содержит константу, то это подразумевает, что
N г=1
То есть, среднее значение остатков равно нулю. Понятно, что это привлекательный результат. Если среднее значение остатков было бы не нулевым, то это означало бы, что мы могли бы улучшить аппроксимацию, добавляя или вычитая одну и ту же константу для каждого наблюдения, то есть, изменяя константу Ъ. Следовательно, для среднего наблюдения справедливо, что
Говорят, что два вектора х и у являются ортогональными, если х у = 0, то есть, если хіУі = 0 (см. Приложение А).
У = х'Ь, (2.11)
выгде у = (-jyj ^Гуі, а х = (^Л J^x*, — if-мерный вектор
' i=l ^ ' i=l
борочных средних значений. Данный вывод показывает, что для среднего наблюдения нет никакой ошибки аппроксимации. Аналогичные интерпретации справедливы для других компонент вектора х: если производная по Pk (к = 2, 3,... , К) суммы квадратов
N
ошибок аппроксимации положительна, то есть, если х^Єі > 0, то
это означает, что мы можем улучшить значение целевой функции, уменьшая (3k
2.1.2. Простая (парная) модель линейной регрессии
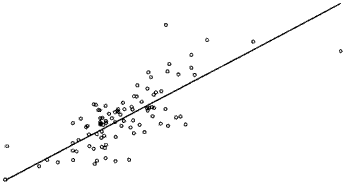
При К = 2 имеется только один регрессор и константа. В этом случае наблюдения2^ (уі, хі) можно нанести на двумерный график со значениями Хі на горизонтальной оси и значениями у і на вертикальной оси. Это сделано на рисунке 2.1 для совокупности данных, которые
У о
-.2 -
-.1
—Г" .2
2) В этом пункте параграфа для обозначения одного регрессора будет применяться хі так, чтобы он не включал константу.
Рисунок 2-1Простая линейная регрессия: аппроксимированная («подогнанная») линия и точки наблюдений
использованы в разделе 2.7 ниже. Наилучшая линейная аппроксимация для переменной у по переменной у и константе получена минимизацией суммы квадратов остатков. В двумерном случае остаток равен расстоянию, измеренному параллельно вертикальной оси между наблюдаемым и аппроксимированным значением. Все аппроксимированные «подогнанные» (fitted) значения находятся на прямой линии, линии регрессии.
Поскольку 2x2 матрицу можно обратить аналитически, то в этом частном случае решения для коэффициентов Ъ и Ъ2 можно получить из вышеприведенного общего выражения для вектора Ъ. Эквивалентно, можно минимизировать остаточную сумму квадратов относительно двух неизвестных непосредственно. Таким образом, мы имеем
~ ~ N ~ ~ 1=1
Основными элементами при выводе МНК-решений являются условия первого порядка:
ЩїМ = -2 f> -А&х<) = 0, (2.13)
= _2JT хг(уг -ААхг) = 0, (2.14) д(32 <=1
Из уравнения (2.13) можно написать
1 N 1 П
Ьі = = ^2уі -&2др J2Xi = у ~b2X> (2Л5)
1=1 і=1
где решение 62 получается из системы уравнений (2.14) и (2.15). Сначала из уравнения (2.14) получаем
N N , N ч
^2 хш -bi ЕXi ~ (Е хчb<2 = °' i=i i=i ^i=i '
а затем подставляем выражение (2.15), чтобы получить
N , N ч
ХгУг ~ Nxy ~ (^2^Nx2)b2 = 0.
г=1 4=1 '
Таким образом, получаем решение для коэффициента наклона Ъ2 в виде
N
Y^(xi я)(Уі У)
Ь2 = ^ . (2.16)
г=і
При добавлении множителя l/(N — 1) к числителю и знаменателю оказывается, что МНК-решение Ь2 является отношением выборочной ковариации между переменной х и переменной у к выборочной дисперсии переменной х. В выражении (2.15) свободный член Ъ определен так, что делает среднюю ошибку (остаток) аппроксимации равной нулю.
2.1.3. Пример: индивидуальная заработная плата
Пример, который часто будет использоваться в этой главе, основан на выборке индивидуальных заработных плат и некоторых базовых характеристик, таких как пол, национальность и общее число лет обучения. Из американского Национального периодического обследования (NLS*)), мы взяли подвыборку данных 1987 года, которая составила 3296 молодых работников, 1569 из которых — женщины 3^. Средняя почасовая тарифная ставка заработной платы в этой выборке равняется 6,42 доллара для мужчин и 5,15 доллара для женщин. Теперь предположим, что мы пытаемся аппроксимировать заработную плату линейной комбинацией из константы и переменной, которая принимает значение 1 или 0 в зависимости от того, мужчина это или женщина. Таким образом Х{ = 1, если рабочий і является мужчиной, и равен 0 в противном случае. Такую переменную, которая может принимать только значения нуль и единица, называют фиктивной переменной. Используя МНК, в результате имеем
Уі = 5,15 + 1,28^.
NLS — US National Longitudinal Survey (примеч. переводчика). Данные для этого примера доступны как WAGES 1.
Это означает, что для женщин наилучшая аппроксимация равна 5,15 доллара, а для мужчин равна 5,15 + 1,28 = 6,42 доллара. Нет случайного совпадения в том, что эти числа в точности равны выборочным средним в двух подвыборках мужчин и женщин. Ведь из приведенных выше результатов легко проверить, что
Ьі = У/, b2 = ym-yf,
где
У^ХіУі
Угп = ~
является выборочным средним заработной платы для мужчин, а
5^(1 -Хі)Уг г
— выборочным средним для женщин. 2.1.4. Матричные обозначения
Поскольку в эконометрике в качестве краткой записи часто применяются матричные выражения, то для чтения эконометрической литературы необходимо некоторое ознакомление с таким матричным «языком». В этой книге мы регулярно будем формулировать результаты, используя матричную систему обозначений, и иногда, когда альтернатива чрезвычайно громоздка, ограничимся только матричными выражениями. Используя матрицы, решение методом наименьших квадратов получаем быстрее, но требуется некоторое знание матричного дифференциального исчисления. Мы вводим следующую систему обозначений:
/і Хі2 ... Хік
Х =
У
1 xN2
XNK )
VnJ
Таким образом, в N х К матрице X г-ая строка соответствует наблюдению г, а /с-ый столбец соответствует наблюденным значениям k-ой объясняющей переменной (регрессора). Критерий минимизации, заданный выражением (2.4), можно переписать в матричной системе обозначений, используя тот факт, что скалярное произведение вектора с самим собой {х'х) является суммой квадратов его элементов (см. приложение А). То есть,
S0) = (уХр)'{у Х0) = у'у 2у'Хр + Р'Х'Хр, (2.17)
из которого следует МНК-решение посредством дифференцирования4^ относительно (3 и приравнивания результата к нулю:
= -2(Х'у-Х'Х(3) = 0* (2.18)
д(3
Решая уравнения (2.18), приходим к МНК-решению
Ъ=(Х'ХГ1Х'у, (2.19)
которое является в точности тем же самым, что получено в выражении (2.7), но теперь записанное в матричных обозначениях. Заметим,
N
что мы снова должны предположить, что матрица XіX — Хіх[
і=і
обратима, то есть, что не существует точной (или полной) мульти-кол л инеарности.
Как и прежде, мы можем разложить у в виде
у = ХЬ + е, (2.20)
где е — N-мерный вектор остатков. Условия первого порядка подразумевают, что Xі {у — ХЪ) = 0, или
Х'е = 0. (2.21)
Последнее выражение означает, что каждый столбец матрицы X ортогонален вектору остатков. С помощью выражения (2.19) мы также можем записать (2.20) как
y = Xb + e = X(XfX)~lX,y + е = у + е, (2.22)
так что прогнозное значение для переменной у имеет вид:
у = ХЪ = Х{Х'Х)-1Х'у = Рху. (2.23)
4) См. Приложение А для некоторых правил дифференцирования матричных выражений по вектору.
Отметим, что левая и правая части этого соотношения представляют собой векторы столбцы размерности К, так что 0 в правой части — это вектор-столбец, размерности К, состоящий из одних нулей (прим. научн. ред. перевода).
В линейной алгебре матрица Рх = Х(Х'Х)~1Х' известна как матрица проектирования (см. Приложение А). Она проектирует вектор у на столбцы матрицы X (то есть на пространство «натянутое» на столбцы матрицы X). Это — просто геометрическая интерпретация получения наилучшей линейной аппроксимации у по столбцам (регрессорам) матрицы X. Остаточный вектор проектирования
е — у — ХЪ — (I — Рх)у — МхУ является ортогональным дополнением. Он является проекцией у на пространство, ортогональное к пространству, натянутому на столбцы матрицы X. Такая интерпретация иногда полезна. Например, проектирование дважды на одно и то же пространство должно оставить результат неизменным, так что справедливо РхРх — Рх и МхМх = МхЧто еще более важно, справедливо, что МхРх — 0, так как пространство столбцов матрицы X и его ортогональное дополнение совместно не имеют ничего общего (кроме нулевого вектора). Это — альтернативный способ интерпретации результата, что ре, а также X и е ортогональны. Интересующийся читатель отсылается к Дейвидсону и МакКиннону (Davidson, MacKinnon, 1993, Chapter 1), к превосходному обсуждению геометрии метода наименьших квадратов.
2.2. Линейная модель
множественной регрессии
Обычно экономисты хотят больше, чем просто получение наилучшей линейной аппроксимации одной переменной по заданному множеству других переменных. Им хочется получить экономические соотношения, в общем являющиеся более адекватными, чем выборка, которую они иногда имеют. Экономисты хотят извлечь выводы о том, что случится, если фактически одна из переменных изменится. То есть: они хотят сказать кое-что о вещах, которые не наблюдаются (еще). В этом случае мы хотим, чтобы соотношение, которое найдено, было бы более чем просто случайное историческое стечение обстоятельств; оно должно отражать фундаментальные отношения. Чтобы прийти к этому, предполагается существование общего соотношения, которое справедливо для всех возможных наблюдений из хорошо-определенной генеральной совокупности (например, все домашние хозяйства США, или все фирмы в определенной отрасли промышленности). Ограничивая внимание линейными соотношениями, мы определим статистическую модель в виде
Уі = 0і+ 02ХІ2 + ... + РкХік + Єі (2.24)
или
Уі = х'ф + Єі,
(2.25)
где у і и $і — наблюдаемые переменные, а є і — не наблюдаемая переменная, которая называется членом ошибки или членом возмущения*^. Равенство в (2.25) предполагается справедливым для любого возможного наблюдения, тогда как мы наблюдаем только выборку из N наблюдений. Мы рассматриваем эту выборку как одну реализацию из всех потенциально возможных выборок объема 7V, которые могли бы быть извлечены из одной той же генеральной совокупности. Таким образом, мы можем рассматривать переменные у і и Єї (и часто вектор переменных Хі ) как случайные переменные. Каждое наблюдение соответствует реализации этих случайных переменных. Опять мы можем использовать матричную систему обозначений и объединить все наблюдения, чтобы написать
у = Х/3 + є, (2.26)
где у и є — TV-мерные векторы, а матрица X, как и прежде, имеет размерность N х К. Отметим разницу между последним уравнением и уравнением (2.20).
В отличие от уравнения (2.20) уравнения (2.25) и (2.26) являются соотношениями генеральной совокупности, где /3 — вектор неизвестных параметров, характеризующих генеральную совокупность. Выборочный процесс описывает, как выборка извлекается из генеральной совокупности, и в результате выборочный процесс определяет случайность выборки. В первом представлении вектор переменных Хі рассматривается как фиксированный, а не стохастический вектор, предполагая, что каждая новая выборка будет иметь одну и ту же матрицу X. В этом случае к вектору переменных Хі относятся как к детерминированному вектору. Новая выборка подразумевает новые значения только для регрессионного остатка є і или, эквивалентно, для переменной уі. Единственный реальный случай, когда
По существу, здесь речь идет о стохастических регрессионных остатках модели. Широко используемый для их обозначения в англоязычной литературе термин «ошибка» ("error") слишком узко, а чаще — неадекватно передает их смысл. В действительности, ненаблюдаемый член є і в регрессионных соотношениях (2.24) и (2.25) отражает, в основном, остаточное влияние на у і факторов, не представленных в наборе переменных Хц, Жг2, • • • > ХіК> и лишь в малой степени — возможность ошибки в измерении самого уі (об этом упоминает и сам автор в дальнейшем). Поэтому во всем дальнейшем тексте мы будем при переводе придерживаться этой позиции, т. е. называть є і — остатком, а разность = у і — х'ф, где /3 — МНК-оценка параметра /3, — МНК-оцененным остатком (примеч. научн. ред. перевода).
вектор переменных Хі действительно детерминированный, соответствует проведению экспериментов в лаборатории, когда исследователь может назначать условия эксперимента (например, температуру, давление воздуха). В экономике, как правило, приходится работать не с экспериментальными данными. Несмотря на это, удобно, и в конкретных случаях в экономическом контексте уместно, рассматривать вектор переменных Хі как детерминированный вектор. В этом случае мы должны сделать некоторые предположения о выборочном распределении регрессионного остатка Є{. Подходящее распределение соответствует случайному выбору, когда каждый регрессионный остаток Єї является случайным извлечением из генеральной совокупности с некоторым распределением и не зависит от других регрессионных остатков. Мы возвратимся к этой проблеме ниже.
Во втором представлении новая выборка подразумевает новые значения, как для вектора х^, так и для регрессионного остатка є і , и таким образом каждый раз из генеральной совокупности извлекается новое множество из N наблюдений по вектору (у*, х[). Тогда случайная выборка означает, что каждый вектор (х^ є і), или (у;, х^), случайно извлекается из генеральной совокупности с соответствующим распределением. В этом контексте важно сделать предположение о совместном распределении вектора Х{ и регрессионного остатка є^, в особенности относительно независимости регрессионного остатка s{ от вектора переменных Хі. Идея (случайной) выборки наиболее понятна в пространственном ("cross-sectional") контексте, когда нас интересует большая и фиксированная совокупность, например, все британские домашние хозяйства в январе 1999 г. или все акции, зарегистрированные на Нью-Йоркской фондовой бирже на конкретную дату. В контексте временных рядов различные наблюдения относятся к разным периодам времени, и бессмысленно предполагать, что мы имеем случайную выборку из временных периодов. Вместо этого мы придерживаемся мнения, что выборка, которая у нас есть, является только одной реализацией того, что могло бы случится в данном временном периоде и случайность относится к альтернативным состояниям мира. В таком случае мы должны сделать некоторые предположения о способе порождения данных (а не о способе, которым эти данные выбираются).
Важно понять, что без дополнительных ограничений статистическая модель (2.25) не имеет смысла: для любого значения вектора коэффициентов регрессии (3 всегда можно определить множество регрессионных остатков Є{ такое, что модель (2.25) в точности будет справедлива для каждого наблюдения. Таким образом, мы должны принять некоторые предположения, чтобы придать модели смысл. Общее предположение состоит в том, что математическое ожидание регрессионного остатка Єі, при заданном векторе объясняющих переменных хі, равно нулю, то есть Е{єіхі} = 0. Обычно на это предположение ссылаются как на предположение, говорящее, что переменные х являются экзогенными. Согласно этому предположению справедливо
Е{Уіхг} = х'г(3, (2.27)
так что линия регрессии хР описывает условное математическое ожидание случайной переменной уі при заданном векторе Хі. Коэффициенты регрессии /3k измеряют, насколько изменится математическое ожидание у і при изменении значения Xik, если остальные х-переменные остаются постоянными (условие ceteris paribus (при прочих равных условиях))*). Однако экономическая теория часто предполагает, что модель (2.25) описывает причинное соотношение, в котором коэффициенты регрессии Р измеряют приращения уі, вызванные приращением х^ при прочих равных условиях. В таких случаях регрессионный остаток є і имеет экономическую (а не только статистическую) интерпретацию и предположение его некоррелированности с вектором переменных Хі , которое мы вводим с помощью наложения условия Е{єіхі} = 0, возможно не обосновано. Так как во многих случаях можно утверждать, что ненаблюдаемые значения члена регрессионного остатка связаны с наблюдаемыми значениями вектора переменных Хі , то мы должны быть осторожными при интерпретации наших коэффициентов регрессии как измерителей причинных эффектов. Мы вернемся обратно к этим проблемам в главе 5.
Теперь, когда наш вектор коэффициентов Р имеет смысл, мы можем попробовать использовать выборку (у^? x^),i = l,...,iV, чтобы сказать кое-что о векторе р. Правило преобразования, которое говорит, каким образом данная выборка преобразуется в аппроксимирующее значение для вектора коэффициентов регрессии /?, называется функцией оценивания ("estimator") (см. прим. научи, ред. перевода в начале этой главы). Результат, полученный для данной выборки, называют оценкой ("estimate"). Функция оценивания является вектором случайных переменных, поскольку
Часто употребляемое латинское выражение (примеч. переводчика).
выборки из одной и той же генеральной совокупности могут меняться. Оценка является вектором чисел. Наиболее широко применяемой функцией оценивания в эконометрике является функция оценивания обычного метода наименьших квадратов (МНК). Это просто обычное правило наименьших квадратов, описанное в разделе 2.1, применяемое к имеющейся выборке. МНК-функция оценивания для вектора коэффициентов f3 таким образом задается в виде

(2.28)
Поскольку мы предположили лежащую в основе «истинную» модель (2.25) в комбинации с выборочной схемой, то теперь Ъ является вектором случайных переменных. Нас интересует вектор истинных неизвестных параметров /?, а случайный вектор Ъ рассматривается как его аппроксимация. Несмотря на то, что данная выборка предоставляет только одну оценку, мы определяем качество этой оценки через свойства лежащей в основе функции оценивания. Функция оценивания b имеет выборочное распределение, поскольку ее значение зависит от выборки, которая (случайно) извлекается из генеральной совокупности.

Обсуждение Путеводитель по современной эконометрике
Комментарии, рецензии и отзывы