Глава 2. инструментальные переменные. системы одновременных уравнений 2.1. проблема коррелированности случайных ошибок с объясняющими переменными
Глава 2. инструментальные переменные. системы одновременных уравнений 2.1. проблема коррелированности случайных ошибок с объясняющими переменными
В главе 1 мы встретили модели наблюдений, в которых естественным образом возникла необходимость использования вместо метода наименьших квадратов другого метода оценивания -метода максимального правдоподобия. (В классической линейной модели с независимыми, нормальными, одинаково распределенными ошибками эти методы совпадают.)
Теперь мы рассмотрим некоторые ситуации, приводящие к еще одному популярному методу оценивания методу инструментальных переменных. Общим для такого рода ситуаций является наличие коррелированности одной или нескольких объясняющих переменных со случайной ошибкой, входящей в правую часть уравнения. Поскольку случайные ошибки отражают наличие неучтенных факторов, не включенных в уравнение в качестве объясняющих переменных, указанная коррелированность фактически означает наличие корреляции между некоторыми учтенными и неучтенными факторами.
В матрично-векторной форме классическая нормальная линейная модель наблюдений имеет вид
y = хе + є,
где
У = (y1, У 2, к, yn ) вектор-столбец значений объясняемой переменной в n наблюдениях,
X (пхр)-матрица значений объясняющих переменных в n наблюдениях, n > p,
Є = (Є1, Є2, ■■■ ,ЄР)Т вектор-столбец коэффициентов,
є = (є1,є2 ...,£„ )T - вектор-столбец случайных ошибок
(возмущений) в п наблюдениях, причем случайный вектор є имеет n-мерное нормальное распределение с нулевым вектором математических ожиданий
Е(Є) = (Е(є{), Е(є2), Е(єп))т = (0, 0, 0)T (в краткой записи: Е(є) = 0)
и ковариационной матрицей
Усіг(є) = (Єоу(є , є)) = ° In, где Іп единичная матрица (размера п х п). Здесь
Єоу(є , є) = Е(є Е(є))(єЕ(є)) -ковариация случайных величин є и є .
Предположение о фиксированности значений объясняющих переменных в совокупности со стандартными предположениями об ошибках удобно с чисто математической точки зрения: при таких предположениях оценки параметров, получаемые методом наименьших квадратов, имеют нормальное распределение, что, в свою очередь, дает возможность:
строить доверительные интервалы для коэффициентов линейной модели, используя квантили t -распределения Стьюдента;
проверять гипотезы о значениях отдельных коэффициентов, используя квантили t-распределения Стьюдента;
проверять гипотезы о выполнении тех или иных линейных ограничений на коэффициенты модели, используя квантили ^-распределения Фишера;
строить интервальные прогнозы для "будущих" значений объясняемой переменной, соответствующих заданным будущим значениям объясняющих переменных.
Вместе с тем используемое в классической модели предположение о фиксированности значений объясняющих переменных в n наблюдениях фактически означает, что мы можем повторить наблюдения значений объясняемой переменной при том же наборе значений объясняющих переменных xn,...,хір ,
i = 1,..., п ; при этом мы получим другую реализацию (другой набор значений) случайных составляющих є , i = 1,. • •, п , что приведет к значениям объясняемой переменной, отличающимся от значений у1,...,уп , наблюдавшихся ранее.
С точки зрения моделирования реальных экономических явлений, предположение о фиксированности значений объясняющих пременных можно считать реалистическим лишь в отдельных ситуациях, связанных с проведением контролируемого эксперимента. Между тем в реальных ситуациях по большей части нет возможности сохранять неизменными значения объясняющих переменных. Более того, и сами наблюдаемые значения объясняющих переменных (как и "ошибки") часто интерпретируются как реализации некоторых случайных величин. В таких ситуациях становится проблематичным использование техники статистических выводов, разработанной для классической нормальной линейной модели.
Поясним последнее, обратившись к матрично-векторной форме классической линейной модели с p объясняющими переменными
у = Хв + є
и не требуя нормальности распределения вектора є.
Если матрица X имеет полный ранг p , то матрица ХтХ является невырожденной, для нее существует обратная матрица (Х'Х1, и оценка наименьших квадратов для вектора в неизвестных коэффициентов имеет вид
в) = (ХтХ) 1Хту.
Математическое ожидание вектора оценок коэффициентов равно
Е(в) = E ((XTX) 1Хт(Хв + є)) = E ((XTX) 1ХтХв) + E ((XTX) lXTe) =
=в + E ((XTX) lXT^). Если матрица X фиксирована, то тогда E ((XTX) lXTє) = (XTX) lXT E (є) = 0,
так что E(e) = в, т.е. в несмещенная оценка для в.
Если же мы имеем дело со стохастическими (случайными, недетерминированными) объясняющими переменными, то в общем случае E ((XTX)Xє) Ф 0, так что
E(e) Ф в,
и в смещенная оценка для в. Кроме того, эта оценка уже не имеет нормального распределения даже если вектор є имеет нормальное распределение.
Если объясняющие переменные стохастические, то в некоторых случаях все же остается возможным использовать стандартную технику статистических выводов, предназначенную для классической нормальной линейной модели, по крайней мере, в асимптотическом плане (при большом количестве наблюдений).
В этом отношении наиболее благоприятной является
Ситуация A
случайная величина єі не зависит (статистически) от
xk 1,к , xkp при всех i и k ;
є1, є2, ... , єп являются независимыми случайными величинами, имеющими одинаковое нормальное распределение с нулевым математическим ожиданием и конечной дисперсией а > 0. (Как и ранее, мы кратко обозначаем это как єі ~ i.i. d. N(0, а2). Здесь independent identically distributed.)
При выполнении таких условий имеем:
E ((XTX) - ) = E ((XTX)lXT) -E(^) = 0 (если, конечно, математическое ожидание E ((XTX) 1XT) существует и конечно), так что оценка наименьших квадратов для является несмещенной. Распределение статистик критериев (тестовых
статистик) можно найти с помощью двухшаговой процедуры. На первом шаге находим условное распределение при фиксированном значении матрицы X ; при этом значения объясняющих переменных рассматриваются как детерминированные (как в классической модели). На втором шаге мы получаем безусловное распределение соответствующей статистики, умножая условное распределение на плотность X и интегрируя по всем возможным значениям X .
Если применить такую процедуру для получения безусловного распределения оценки наименьших квадратов в, то на первом шаге находим:
в | X ~ и[в, о1 (xtX)-1 j .
Интегрирование на втором этапе приводит к распределению,
являющемуся смесью нормальных распределений
NVj^e, о1 (xtX) j по X . Это распределение, в отличие от
классического случая, не является нормальным.
В то же время для оценки j'-го коэффициента имеем:
в; 1 X ~ , о1 (xTxXi ),
где (xtXj-й диагональный элемент матрицы (xtX) , так что
вві 'в, , — 1 1 | X ~ N (0, 1) .
0 (xTx) 'j
Условным распределением для (n p)S2la2, где S1 = RSS/(n p), RSS остаточная сумма квадратов, является распределение хи-квадрат с (n p) степенями свободы, (n p)S2la2 | X ~ x p) .
Заметим теперь, что ґ-статистика для проверки гипотезы H0:
в j = в** определяется соотношением
Из предыдущего вытекает, что если гипотеза H0 верна, то условное распределение этой t-статистики имеет t-распределение Стьюдента с (n p) степенями свободы,
t | X ~ t(n p) .
Это условное распределение одно и то же для всех X. Поэтому вне зависимости от того, какое именно распределение имеет X,
безусловным распределением t-статистики для H0 : 6j = 0** при
выполнении этой гипотезы будет все то же распределение t(n p) .
Аналогичное рассмотрение показывает возможность использования стандартных ^-критериев для проверки линейных гипотез о значениях коэффициентов.
Те же самые выводы остаются в силе при замене предположений ситуации A следующим предположением.
Ситуация Л'
ЄІ X ~N(0, a2In), где In единичная матрица (размера n х n) .
Ситуация C
В рассмотренных выше ситуациях, как и в классической модели, предполагалось, что Єг|Х ~ i.i.d. Теперь мы откажемся от этого предположения и предположим, что
условное распределение случайного вектора є относительно матрицы X является n-мерным нормальным распределением N(0, о V) ;
V известная положительно определенная симметричная матрица размера n*n.
Поскольку матрица V симметрична и положительно определена, таковой же будет и обратная к ней матрица V 1. Но тогда существует такая невырожденная (ихи)-матрица P, что V-1 = PTP. Используя матрицу P, преобразуем вектор є к вектору
є = P є .
При этом Е(є) = 0 и условная (относительно X) ковариационная матрица вектора є
Єоу(є* X) = Е(єєт X) = Е(P є (P є)т X) = = P Е (є єт X) PT = P а2 V PT. Но V = (V-1) -1 = (PTP) -1, так что
Єоу(є* X) = P а2 VPT = а2 P(PTP) lPT = a2In. Преобразуя с помощью матрицы P обе части основного уравнения
y = Xe+є ,
получаем:
Py = PXв+Pє ,
или
* * * У =Xв+є ,
где
y* = Py , X* = PX, є*= Pє . В преобразованном уравнении
є* X ~ N(0, а21п), так что преобразованная модель удовлетворяет условиям, характеризующим ситуацию Л'. Это означает, что все результаты, полученные в ситуации Л, применимы к модели y = X в+є .
В частности, оценка наименьших квадратов
в* = (X*TX*)1X*Ty* = (XTPTPX)-1 XTPTPy = (XT V-X)1XT V1y является несмещенной, т.е. Е(в ) = в, ее условное распределение (относительно X) нормально и имеет ковариационную матрицу
Cov(e* X) = a2(X*TX*)-1 = a2(XT V~ 1X)-1. Получение этой оценки равносильно минимизации по в суммы
ZZW* Уг -в1 Xi1 ~ ■■■ ~врХ,р )Vk -в1 Xk1 ~ -epxkp ), i=1 к=1
где wik = v(k^ элементы матрицы V
Отсюда название метода обобщенный метод наименьших квадратов. Сама оценка в называется обобщенной оценкой наименьших квадратов (GLS gemralized least squares).
В рамках модели y = X в+ є можно использовать обычные статистические процедуры, основанные на tи ^-статистиках.
Заметим теперь, что во всех трех ситуациях A, Л' и С общим является условие
E^,X)= 0, i = 1,...,п , так что
ЕІєЛ^кі)= 0 для j = 1,...,p при всех i и k .
Но тогда
)=0
и
Cov^, Xj. ) = EE\%Xkj E(xkj )) = Exj E{Xj )) = = Е{єіХк,)= 0
(конечно, при этом мы предполагаем, что математические ожидания E {xkj-) существуют и конечны).
Таким образом, если ошибка в i -м уравнении коррелирована хотя бы с одной из случайных величин xkj-, то ни одно из условий Л,
A', C не выполняется. Например, эти условия не выполняются, если в i -м уравнении какая-нибудь из объясняющих переменных коррелирована с ошибкой в этом уравнении. Последнее характерно для моделей с ошибками в измерении объясняющих переменных и для моделей "одновременных уравнений", о которых мы будем говорить ниже. Пока же приведем пример, показывающий, к каким последствиям приводит нарушение условия некоррелированности объясняющих переменных с ошибками.
П р и м е р
Смоделированные данные следуют процессу порождения данных (DGP data generating process)
DGP: y, = a+pxt + є,, є,~ i.i.d. N(0,1), i = 1,... ,100 , a = 10, в= 2,
х, =є, -0.9Єіч, i = 2,... ,100 ; при этом Corr (xi, єі ) = 0.743.
 Предположим, что мы имеем в распоряжении значения yi, xi, i = 2,к ,100 , но ничего не знаем о процессе порождения данных. Оценим на основании этих данных статистическую модель yt = a + px{ + єі методом наименьших квадратов. При этом получаем следующие результаты:
Предположим, что мы имеем в распоряжении значения yi, xi, i = 2,к ,100 , но ничего не знаем о процессе порождения данных. Оценим на основании этих данных статистическую модель yt = a + px{ + єі методом наименьших квадратов. При этом получаем следующие результаты:
сильное смещение.
Зафиксировав полученную реализацию x2,..., x100, смоделируем
еще 499 последовательностей {є1(і),...,}, k = 2,... ,500, имитирующих реализации независимых случайных величин, имеющих стандартное нормальное распределение, и для каждой такой последовательности построим последовательность
{y2k V-yS} по формуле:
y(k) = a + pxt + є<4, i = 2,k ,100. Для каждого k = 2,... ,500 по "данным" y(k),xi, i = 2,... ,100, оцениваем статистическую модель y(k) = a + fixi + єк) и получаем
оценки коэффициентов а(к), (5(к). В результате получаем
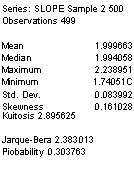
последовательности оценок а(2), . ..,a(500) и (5(-т>,j3(500 Приведем статистические характеристики последовательности
((2) /3(500)
 |
 k = 2,k ,500, сначала построим последовательность {x2k),...,x((00}, а
k = 2,k ,500, сначала построим последовательность {x2k),...,x((00}, а затем построим последовательность {y2k } по формуле:
y(k) =a + [3x<(k) +єєс), i = 2,k ,100. В отличие от предыдущего способа здесь для различных значений k используются различные последовательности {x2k}, определяемые последовательностью {ef ),к,є1(ko|}. После получения последовательностей {x22k...,} и {y2ky100}, при каждом k = 2,k ,500 производим оценивание статистической модели y(k) = а + в x(k) + єк) и получаем оценки коэффициентов a*(k), в *(k). Обозначая оценки, полученные в самом начале, как aи втак что a*(1) = 10.13984, в= 2.553515, получаем
Л*П) Л*(500) о о *(500)
последовательности оценок a,...,av 'и в , •, в . Приведем сводку статистических характеристик последовательности
в в *(500)
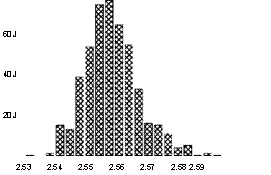
Series: SLOPERANDOM Sample 2 500 Observations 499
Mean 2.552114
Median 2.551333
Maximum 2.588107
Minimum 2.530200
Std. Dev. 0.007346
Skewness 0.754039 Kuitosis 4.608878
Jarque-Bera 101.1054
Piobability 0.000000
На этот раз среднее значение полученных значений в*(k), равное 2.552114, весьма сильно отличается от истинного значения параметра в = 2 , а наблюдаемое значение статистики Харке-Бера говорит о том, что распределение оценки наименьших квадратов параметра в= 2 не является нормальным.
Заметим еще, что положительная коррелированность xt и єі означает, что значениям xi , превышающим их среднее значение в выборке, по большей части соответствуют и значения остатков, превышающие их среднее значение в выборке. Но последнее равно нулю при использовании метода наименьших квадратов, так что значения остатков, превышающие их среднее значение в выборке, суть просто положительные значения остатков. В итоге для
первоначально смоделированных данных yi, xi, приводит к следующей картине:
:2,...,100, это

Y
Y_THEOR
Linear (Y)
-4
4
Здесь Linear(Y) прямая, подобранная по этим данным методом наименьших квадратов, т.е. прямая y = 10.13984 + 2.553515x, а YTHEOR "теоретическая" прямая y = 10 + 2 x . Как видно из
графика, первая прямая "повернута" относительно второй прямой в направлении против часовой стрелки, так что для больших значений xi наблюдаемые значения yi смещены вверх по отношению к прямой y=10 +2 x.

Обсуждение Эконометрика для начинающих (Дополнительные главы)
Комментарии, рецензии и отзывы