3.12. модели бинарного выбора
3.12. модели бинарного выбора
Мы уже рассматривали модели такого рода в Главе 1, но только для данных, относящихся к одному-единственному моменту (периоду) времени (cross-section data данные в сечениях). Если исследование затрагивало n субъектов, то мы отмечали факт наличия или отсутствия некоторого интересующего нас признака у i -го субъекта при помощи индикаторной (бинарной) переменной y, которая принимает в i -м наблюдении значение yi. При этом yi = 1 при наличии рассматриваемого признака у i -го субъекта и yi = 0 при отсутствии рассматриваемого признака у i -го субъекта.
Если пытаться объяснить наличие или отсутствие рассматриваемого признака значениями (точнее, сочетанием значений) некоторых факторов (объясняющих переменных), то, следуя идеологии классической линейной модели, мы могли бы расмотреть модель наблюдений
Уі =#Л-1 + ••• + 0pXip + ег, i = 1,...,n ,
в которой xi1, к, xip значения p объясняющих переменных в i -м
наблюдении, 01,...,0p неизвестные параметры, а е1,к,еп случайные ошибки, отражающие влияние на наличие или отсутствие рассматриваемого признака у i -го субъекта каких-то неучтенных дополнительных факторов. При обычных предположениях регрессионного анализа в такой модели получаем: ^ІУі = 1 x,]=01 + ^ + 0pxv ,
т. е. должно выполняться соотношение 0 <0Лі +— + 6pxip < i.
Это первая из трудностей, с которыми мы сталкиваемся при обращении к таким моделям.
Далее, случайная величина et имеет условную дисперсию
D(etxt) = xT9-(i-xTe) .
Таким образом, здесь возникает также проблема гетероскедастичности, осложненная еще и тем, что в выражения для дисперсий et входит и (неизвестный) вектор параметров в .
Кроме того, если, скажем,
y, = a + px, +є,, i = i, —,n ,
то
E (y,x,) = P{y, = i x,]=a + PxI, так что если значение x увеличить на единицу, то вероятность
наличия представляющего интерес признака у I -го субъекта увеличится на величину, равную (a + p(x, + i))-(a + Px, ) = P, независимо от того, сколь большим или малым является значение xI.
Более подробное рассмотрение этой ситуации привело нас к необходимости использования нелинейных моделей вероятности вида
P{yt = i xt }= G(eixfl + ^ + evxlv), где G(z) S-образная функция распределения, имеющего плотность g (z ) = G '(z), что соответствует нелинейной модели регрессии
Уі = G(ei x,i + — + epx,p )+£г , ^ i, —, n .
Предположим, что при фиксированных значениях объясняющих переменных в n наблюдениях, что соответствует фиксированным значениям векторов xI, случайные ошибки є1,...,єп статистически
независимы. Тогда при фиксированных xi статистически
независимы и случайные величины G(e1хй + + (pxip ,
i = 1,n , т.е. статистически независимы J^,...,yn . В силу этого (условная при фиксированных xi, i = 1,...,n) совместная вероятность получения конкретного набора наблюдений yl5...,yn (конкретного набора нулей и единиц) равна произведению
П И»=1 х Т Иу = 0 х, Tyi = Г1 (G[xje)Yi (i o[xT4-yi .
Правая часть этого выражения является при фиксированных xi, i = 1,. „, n , функцией от вектора неизвестных параметров в,
Ь(в) = L(ex1xn) = ПШв))Уі (1 -G(xTв))1'y
i=1
и интерпретируется как функция правдоподобия параметров в1,...,вр . Дело в том, что при различных наборах значений в1,...,вр
получаются различные L()), т.е. при фиксированных xi, i = 1,...,n , вероятность наблюдать конкретный набор значений y1,..., yn может быть более высокой или более низкой, в зависимости от значения в . Метод максимального правдоподобия предлагает в качестве оценки
] = max
в N ' в
i=1
вектора параметров в использовать значение в = в, максимизирующее функцию правдоподобия, так что
1-yi
= max = max П (Ш в))Уі (1 g(xt в))1
Использование свойства монотонного возрастания функции ln(z),
позволяет найти то же самое значение (в, максимизируя логарифмическую функцию правдоподобия lnL(0). В нашем случае
lnL(() = ±yt lnG(xTe(+ ]^(1 -y, )ln(1 -G(xTв().
i=1
i=1
Если не имеет место чистая мультиколлинеарность объясняющих переменных (т.е. если матрица X = (xiJ-) значений p объясняющих
переменных в n наблюдениях имеет ранг p, так что ее столбцы линейно независимы), то тогда функция L(6) имеет единственный локальный максимум, являющийся и глобальным максимумом, что гарантирует сходимость соответствующих итерационных процедур к оценке максимального правдоподобия.
Модель бинарного выбора обычно связывается с наличием
некоторой ненаблюдаемой (латентной) переменной у*, часто трактуемой как "полезность" интересующего нас признака для i -го субъекта, и такой, что
У = j1, если у* > у,
[0 — в противном случае. Если эта "полезность" определяется соотношением
у] = Pix,i + •" + Ppxip +£і , i = 1 -,n , и случайные ошибки имеют нормальное распределение, то
Р[у, = 1 x, }= G(xT р) = Ф(ві + ^ + JBpXip). В стандартной модели полагается у = 0 .
Нарушение предположения об одинаковой распределенности случайных ошибок et в процессе порождения данных приводит к
гетероскедастичной модели и к несостоятельности оценок максимального правдоподобия, получаемых на основании стандартной модели.
Перейдем теперь к панельным данным. И здесь модель бинарного выбора обычно связывается с наличием некоторой ненаблюдаемой (латентной) переменной у*и и наблюдаемой индикаторной переменной уи такой, что
 |
= x,
it '
где xTt вектор-строка значений объясняющих переменных для i -го субъекта в период t .
Предположим, что случайные ошибки ей независимы и
одинаково распределены в обоих направлениях и имеют симметричное распределение с функцией распределения G и что
объясняющие переменные строго экзогенны.
Если трактовать ц как фиксированные неизвестные параметры,
то это соответствует включению в модель N дамми-переменных.
Логарифмическая функция правдоподобия принимает тогда вид: ln L(fi,(Xi, k,«n ) =
= X У и ln G(a + xjt в) + X (1 — У и )ln(l — G(a, + xjt в)).
И здесь возникает ситуация, когда оценка максимального правдоподобия для J3 и а{ даже при выполнении стандартных предположений состоятельна только если T —> °°, а при конечном Т и N — °° она несостоятельна. Мы встречались уже с такой ситуацией в рамках OLS-оценивания линейной модели с фиксированными эффектами. Только там при несостоятельности оценок для ц. оценка для J3 оставалась все же состоятельной, тогда
как здесь несостоятельность оценок для ц в общем случае переносится и на оценку для J3 . Одним из исключений является линейная модель вероятности, в которой вероятность P{yit = l| xjt} моделируется как линейная функция от объясняющих переменных.
Конечно, по подобию проделанного раньше, возникает желание
вымести аі непосредственно из уравнения
у * = xTt в + а t + є it . Однако это не дает практической пользы, поскольку, например, если выметание производится путем перехода в этом уравнении к разностям у * — у *t—1, то не удается указать
переход к наблюдаемым переменным типа yit — yi t—1.
Альтернативный подход состоит в использовании условного максимального правдоподобия (conditional FE).
В этом случае рассматривается функция правдоподобия, условная относительно некоторого множества статистик ti , которое
достаточно для а. Это означает, что при заданных значениях этих статистик вклад i -го субъекта в правдоподобие уже не зависит от а. Таким образом, если f (уй,...,yjTat,в) совместная
вероятность значений индикаторной переменной для -го субъекта, то
Соответственно, мы можем получить состоятельную оценку для в , максимизируя условную функцию правдоподобия, основанную на
f {yi1,к, угтг,в).
Наличие указанных достаточных статистик зависит от вида распределения єй. В линейной модели вероятности с нормальными ошибками такой достаточной статистикой является у. Максимизация соответствующей условной функции
правдоподобия приводит к FE-оценке для а. Однако, например, в
случае пробит-модели, в которой нормальными являются ошибки в уравнении
уи = xT в + а + є, достаточной статистики для а{ просто не существует. А это
означает, что мы не можем состоятельно оценить пробит-модель с фиксированными эффектами при конечном Т.
3.12.1. Логит-модель с фиксированными эффектами
Такой модели соответствует латентное уравнение Уі = xlв + а, + єи , в котором ей имеют логистическое распределение
^ z
G( z) = A(z ) = . При этом
1 + ez
nj її із exPix« в+а}
1+exp{xlt в+а}
nj пі /Л і expFTв+а} і
Р{уи = 0 хй ,а,в}=1 - + FLjTe+ І = Т+ 1 т в+ }.
Рассмотрим для иллюстрации логит-модель с Т = 2. Заметим, что в этом случае сумма У 1 + У 2 есть просто общее количество периодов безработицы (суммарная продолжительность пребывания в состоянии безработицы) для i -го субъекта, и что для каждого субъекта есть 4 возможных последовательности состояний (ул, у{2): (0,0), (0,1), (1,0), (1,1). Соответственно, сумма yi1 + yi2 может принимать только 3 возможных значения: 0,1,2 (у i -го субъекта не было периодов безработицы, был один период безработицы, был безработным в течение обоих периодов).
Вычислим условные вероятности указанных четырех последовательностей при различных значениях суммы yi1 + yi2.
Если yi1 + yi2 = 0, то возможна только последовательность (0,0) , так что p{(0,0)| ул + у, 2 = о,а ,/}= і,
а условные вероятности трех других последовательностей при
у,1 + у,2 = 0 равны 0.
Если уі1 + уі2 = 2 , то возможна только последовательность (1,1), так что
р{(1,1)| у,1 + у, 2 = 1,а ,/}= 1,
а условные вероятности трех других последовательностей при у,1 + у, 2 = 1 равны 0.
Если же уі1 + уі 2 = 1, то возможны две последовательности (0,1) и (1,0) , и они имеют условные вероятности, отличные от 0 и 1, тогда как условные вероятности последовательностей (0,0) и (1,1) равны 0. При этом
Р{(01)| + 1 /} Р{(0,1)|x, ,аі , в}
Р{(0,1) у,1 + уі2 = 1 Xit, аі , в}= Р + 1 в} =
Р{у1 + у 2 = 1 Xit,а , в}
= р{у,1 = 0 хй, а, в}рк = 1 x и, а, в}
р{у,1 = 0 х„ ,а ,в}р{уг2 = 1 ,а ,в}+ р{ул = 1x, ,а ,в}р{уг 2 = 0|х, ,а, в
1 _ ЄХР{х{2 в + а-}
1 . exp{x{2 в + а} exp{x{1в + а, } . 1
1 + exp{xje + a,} 1 + exp^Z + aJ 1 + exp{x{e + a} 1 + exp^Z + aJ
= exp{x{2e + a} exp{x,{2e}
exp{x{ в + а }+ exp{x{2 в + ^ } exp{x{e}+ exp{xf2e}'
так что индивидуальные эффекты выметаются, и
p{(0,1)|у.+ у,, = 1,x,,a,,/}= 1exp{(f(' ~Xi ^,.
1 + expj(x,2 — xи ) /З]
Соответственно,
p{(1,0)| y л + y ,2 = 1, x lt, а ,д}= 1 _ p{(0,1)| y л + ya = 1, x й, а, д}=
= 1
Таким образом, все условные вероятности
-KG^ y,2 ) = (r, s)|y,1 + y,2 = h XU ,а ,Д},
где r, s = 0,1, / = 0,1,2 , не зависят от индивидуальных эффектов, так что продолжительность периодов безработицы является достаточной статистикой для а, и использование условного правдоподобия приводит к состоятельной оценке для д .
Полученные результаты означают, что при T = 2 мы можем оценивать логит-модель с фиксированными эффектами, используя стандартную логит модель, в которой в качестве объясняющей переменной выступает xi2 _ xi1, а в качестве наблюдаемой бинарной переменной переменная, отражающая изменение значения переменной yit при переходе от первого ко второму наблюдению (1 при возрастании yit , 0 при убывании yit ). Соответственно, функцию правдоподобия можно записать в виде:
L = ПФ, 0) -М(0,1) -М(1,0) -MCI 1) •}=
i=1
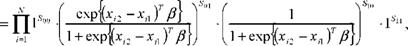
где Srs = 1, если yi1 = r, yi2 = s, и Srs = 0 в противном случае. Мы видим, что субъекты, для которых yi1 = yi2 = 0 или yi1 = yi 2 = 1, не вносят дополнительный вклад в функцию правдоподобия и фактически игнорируются при оценивании. Для оценивания д существенны только те субъекты, которые хотя бы однажды изменяют свой статус в отношении yit .
Параметр / идентифицируется здесь по одному только
^шіт"-измерению данных. Вклад в оценивание вносят только те субъекты, которые изменили свой статус. При значениях T > 2 вычисление условных вероятностей более хлопотно, но также возможно.
Проверку гипотезы H0 об отсутствии индивидуальных эффектов можно осуществить с помощью критерия типа Хаусмана, основанного на разности между оценкой J3CML для /, полученной с использованием условного правдоподобия и обычной логит ML-оценкой /ъль, игнорирующей индивидуальные эффекты (при вычислении последней константа исключается). Логит MLE состоятельна и эффективна только при гипотезе H0 и несостоятельна при альтернативе. Условная же MLE состоятельна и при гипотезе H0 и при альтернативе, но не эффективна, так как использует не все данные. Таким образом, положение здесь соответствует тому, при котором реализуется схема Хаусмана (см. Главу 2, разд. 2.6.5.). Статистика критерия
H = (ficML вШ. j )CoV{eCML )^(Рш. } ' [ftCML )
имеет при гипотезе H0 асимптотическое распределение хи-квадрат с числом степеней свободы, равным размерности вектора в .
З а м е ч а н и е
Существенным недостатком метода условного правдоподобия является то, что он предполагает (условную) независимость yi1,K,yT при фиксированных xjt,atМетод неприменим к моделям с запаздывающими значениями объясняющей переменной в правой части.
3.12.2. Пробит-модель со случайными эффектами
Если а статистически независимы от объясняющих
переменных, то модель со случайными эффектами представляется более подходящей, и в этом случае проще рассматривать не логит, а пробит-модель. (Хотя можно использовать и логит-модель, что и делается в приводимом далее примере.)
Здесь мы отправляемся от спецификации
y = J1, если УІІ > 0 " [о — в противном случае,
УI = xl в + u,t,
u,t = а,+є«:
где
а случайные индивидуальные эффекты, а ~ i.i.d. N(о,а^),
єи случайные ошибки, еи ~ i.i.d. N(о,ст2), причем индивидуальные эффекты и ошибки статистически независимы. В этих условиях совместное распределение случайных величин un,...,ujT нормально, причем E(пи) = 0 , D(uit) = ст2а + &Є , Cov(uit,uis ) = Cov(a + єи, а + 2is) = о2а для s Ф t, так что значение
л. л. Cov(uit, uis) o2a
коэффициента корреляции p = , , у, s s = —2 а 2 между
J^JDuT) a2a + аЄ
ошибками uit и uis внутри одной группы (субъекта) одинаково для
любых s Ф t. В "стандартной" спецификации D(ujt ) = 1 и р = о2а.
Это соответствует предположению о том, что стЄ = 1 — (52а.
Совместная вероятность получения набора УЛ,.--, y T при
заданных xл,..., xT определяется как
■, У,тХП,к' XiT' p)f(al )dal =
-co l t =1 _
В рассматриваемой пробит-модели
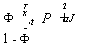
если y,t =1
, если yit = 0,
/2
Итоговый интеграл вычисляется численными методами. Соответствующие программы имеются в некоторых пакетах (например, в Stata).
При гипотезе H0 об отсутствии индивидуальных эффектов
так что проверка отсутствия индивидуальных эффектов сводится к проверке гипотезы Р= 0 .
З а м е ч а н и е
В контексте панельных данных построение порядковых пробит моделей с несколькими категориями отклика довольно затруднительно.
3.12.3. Пример
Рассмотрим результаты исследования панельных данных по Германии (German Socio-Economic Panel) за 5-летний период с 1985 по 1989 гг., проводившихся с целью выяснения влияния состояния безработицы на степень удовлетворенности жизнью ("well-being"). Исходные данные были представлены в порядковой шкале и индексировались числами от 0 до 10. Ввиду сложности построения порядковых логити пробит-моделей для панельных данных, данные были затем сжаты до бинарных. Индивиды, у которых удовлетворенность жизнью индексировалась числами от 0 до 4, считались неудовлетворенными жизнью, тогда как индивиды с индексами 5 и выше считались более или менее удовлетворенными жизнью.
В качестве объясняющих переменных первоначально были привлечены следующие характеристики индивидов: Непрерывная переменная:
LOGINCOME логарифм (располагаемого) дохода см. ниже. Дамми-переменные:
UNEMP (безработный), NOPARTIC (не включен в рынок труда), SELFEMP (самозанятый), PARTTIME (частично занятый) -указывают текущий сатус на рынке труда (категория "полностью занятый" не снабжается дамми-переменнной), MALE индивид мужского пола, OKHEALTH хорошее состояние здоровья, AGE возраст и AGESQUARED квадрат возраста, VOCATIONAL D. наличие профессиональной степени, UNIVERSITY D. наличие университетской степени, MARRIED состояние в браке.
Для правильной интерпретации влияния безработицы на удовлетворенность жизнью надо учитывать целый ряд обстоятельств.
Например, безработица обычно ведет к сокращению дохода, что, в свою очередь, может уменьшить удовлетворенность. Однако, если доход включается в число объясняющих переменных, то коэффициент при безработице фактически измеряет влияние безработицы при прочих равных, т.е. при сохранении дохода постоянным. Это могло быть в реальности, если бы страховое возмещение при безработице достигало 100\%. При высоком (отрицательном) коэффициенте корреляции между безработицей и доходом оценки остаются несмещенными, но их точность может значительно уменьшаться.
Удовлетворенность индивида может уменьшаться вследствие безработицы также и потому, что доля его вклада в общий семейный бюджет уменьшается. Поскольку, в отличие от доходов домохозяйства, имеющиеся в панели данные в отношении индивидуального дохода ограничены прошлыми доходами, в уравнение включается не индивидуальный доход, а доход домохозяйства.
Включение в модель взаимодействий факторов позволяет выделять дифференциальные эффекты влияния безработицы в группах, имеющих разные атрибуты, например, в разных возрастных группах. В связи с этим в модель включены помимо собственно UNEMP также и переменные
UNEMP*AGE<29
UNEMP*AGE30-49.
Другим важным взаимодействием является взаимодействие между безработицей и продолжительностью текущего периода пребывания в состоянии безработного. Влияние продолжительности безработицы на психическое состояние индивида достаточно хорошо документировано в литературе по психологии. В соответствии с этим, в уравнение включается переменная
UNEMPDUR (продолжительность периода безработицы, продолжающегося в настоящее время) и, для учета возможной нелинейности, переменная
UNEMPDURSQ *10-2.
К сожалению, в данных полностью отсутствовал региональный аспект, так что не удалось выяснить влияние локального уровня безработицы.
Следует отметить очень существенное взаимодействие безработицы и пола индивида. По этой причине обработка данных производилась также раздельно по мужчинам и женщинам.
Наличие протяженных наблюдений позволяет, в принципе, включать в модель элементы динамики. Мы, однако, уже говорили о проблемах с оцениванием динамических моделей бинарного выбора, в частности, с включением в правую часть запаздывающих значений объясняемой переменной. В данном анализе предполагается устойчивость индивидуальных откликов во времени, и она как раз учитывается введением в модель индивидуальных эффектов. Для проверки этого свойства в модель помимо переменной UNEMPDUR включается также переменная PREVDUR, указывающая на суммарную продолжительность периодов безработицы за 10 лет, предшествующих анализируемому периоду.
Кроме того в модели используется в качестве объясняющей еще и переменная CHANGEINC относительное изменение дохода домохозяйства по сравнению с предыдущим годом. Это связано с некоторой неясностью в отношении того, что именно влияет на удовлетворенность собственно уровень доходов или его изменение.
Наконец, нельзя исключать возможного наличия и обратной причинной связи между безработицей и уровнем удовлетворенности, т.е. того, что внутренне менее удовлетворенные индивиды скорее и оказываются безработными. Если это так, то переменная UNEMP коррелирует со случайным эффектом в модели случайных эффектов и оценка максимального правдоподобия, не учитывающая этого, оказывается несостоятельной. Поскольку далее приводятся результаты статистического анализа и по модели с фиксированными эффектами и по модели со случайными эффектами, имеется возможность оценить устойчивость результатов к этой возможной эндогенности.
Основная задача состоит в проверке гипотезы о негативном влиянии безработицы на удовлетворенность при очистке от влияния прочих факторов, включая влияние уменьшения доходов.
В приводимых ниже табл. А1 и А2 указаны результаты оценивания порядковой пробит-модели, не учитывающей панельной структуры данных (данные усреднены по времени), но включающей временные дамми. В рассмотренной порядковой пробит-модели предполагается, что уравнение полезности имеет вид
S* = xT в + єи,
и наблюдаемое значение индекса удовлетворенности определяется соотношениями

Обсуждение Эконометрика для начинающих (Дополнительные главы)
Комментарии, рецензии и отзывы