1.2. использование метода максимального правдоподобия для оценивания моделей бинарного выбора
1.2. использование метода максимального правдоподобия для оценивания моделей бинарного выбора
Итак, пусть наша задача состоит в оценивании параметров модели бинарного выбора
y, = G(elx,l + L + epx,p )+є , , = ^--^n , где G(z) - S-образная функция распределения, имеющего плотность g (z ) = G '(z). В соответствии с введенными выше
обозначениями elxl + +epxip = xT в, так что
G(el x д + +epx p ) = G(xTe). Мы предполагаем, что при
фиксированных значениях объясняющих переменных в n наблюдениях, что соответствует фиксированным значениям векторов xi, случайные ошибки £1,,..,en статистически
независимы и E (eixi) = 0 , так что P{yi = l| xi }= E (y,xt) = G(xT в). Тогда при фиксированных xi статистически независимы и
случайные величины g{)1 xu Н +~epxjp )+et, i = 1,,..,n , т.е.
статистически независимы y1, к, yn . В силу этого (условная при фиксированных xi, i = 1, к, n ) совместная вероятность получения конкретного набора наблюдений y1,...,yn (конкретного набора нулей и единиц) равна произведению
П (ГУ, = 1 x t [Pyt = 0 x, Г* = П (1 G[xTef-yi .
i=1 i=1
Правая часть этого выражения является при фиксированных xi, i = 1, к, n , функцией от вектора неизвестных параметров в,
Ь(в) = L(ex1, к, xn) = П {GG{xTв))Уі (1 G{xTв))1-yi
i=1
и интерпретируется как функция правдоподобия параметров в1,к,вр . Дело в том, что при различных наборах значений в1,,..,вр
получаются различные L()), т.е. при фиксированных xi, i = 1, к,n , вероятность наблюдать конкретный набор значений y1, к, yn может быть более высокой или более низкой, в зависимости от значения в . Метод максимального правдоподобия предлагает в качестве оценки
вектора параметров в использовать значение в = в, максимизирующее функцию правдоподобия, так что
Lip) = max = max f[ [g{xt в))Уі {1 g{xt в)) 1~Уі
i=1
Использование свойства монотонного возрастания функции ln(z), позволяет найти то же самое значение в, максимизируя логарифмическую функцию правдоподобия lnL{0). В нашем случае
lnL(6) = Jy, lnG(xT6)+ J(1 yi )ln(1 G(xf #)).
i=1 i=1
Мы не будем углубляться в технические детали соответствующих процедур максимизации, имея в виду, что такие процедуры "встроены" во многие прикладные пакеты статистических программ для персональных компьютеров и читатель при необходимости может ими воспользоваться. Заметим только, что если не имеет место чистая мультиколлинеарность объясняющих переменных (т.е. если матрица X = (xiJ-) значений p
объясняющих переменных в n наблюдениях имеет ранг p , так что
ее столбцы линейно независимы), то тогда функция L(0) имеет
единственный локальный максимум, являющийся и глобальным максимумом, что гарантирует сходимость соответствующих итерационных процедур к оценке максимального правдоподобия.
Мы рассмотрим теперь результаты применения метода максимального правдоподобия для оценивания параметров а и 0 моделей
yi = G(a + 0xi )+єі, i =1n, по упомянутым выше смоделированным данным. При этом мы используем предусмотренную в пакете Econometric Views (EVIEWS) возможность выбора в качестве G(z) функций
1 Г -t2 /2
Ф(z) = ■ I e dt - функция стандартного нормального 42л
распределения N(0,1) (пробит-модель),
ez
Л( z) = - функция стандартного логистического
1 + ez
распределения (логит-модель),
G(z) = 1 exp(ez) функция стандартного распределения экстремальных значений (минимума) I-го типа (распределение Гомпертца, гомпит-модель).
 |
Результаты оценивания указанных трех моделей по смоделированным данным (1000 наблюдений) с использованием пакета EVIEWS таковы:1
В четвертом столбце приведены значения отношений оценок коэффициентов к стандартным ошибкам, рассчитанным по асимптотическому нормальному распределению оценок максимального правдоподобия. В связи с этим, здесь и в последующих таблицах указанное отношение называется не t -статистикой, а z -статистикой. P-значения, приводимые в пятом столбце, соответствуют стандартному нормальному распределению.
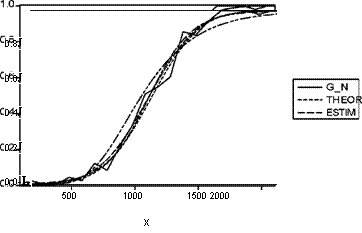
 Полученные значения оценок параметров а ив в первой модели (а = —3.503812, в = 0.003254) соответствуют оценкам ц = 1076.77 и о = 307.31 параметров функции нормального распределения, "сглаживающей" построенную ранее функцию Gn (x), график которой представляет ломаную. Заметим, что в действительности при моделировании данных мы использовали в качестве G(x) функцию нормального распределения с параметрами ц = 1100 и о = 300. Следующий график позволяет сравнить поведение
Полученные значения оценок параметров а ив в первой модели (а = —3.503812, в = 0.003254) соответствуют оценкам ц = 1076.77 и о = 307.31 параметров функции нормального распределения, "сглаживающей" построенную ранее функцию Gn (x), график которой представляет ломаную. Заметим, что в действительности при моделировании данных мы использовали в качестве G(x) функцию нормального распределения с параметрами ц = 1100 и о = 300. Следующий график позволяет сравнить поведение
кусочно-линейной функции Gn (x),
теоретической функции G(x), соответствующей нормальному распределению N(1100, 3 002),
оцененной функции G(x), соответствующей нормальному распределению N(1076.77, 307.312).
 |
| G_N THEOR PR OBIT LOGIT GOMPit
Кривые, получаемые по пробити логит-моделям, отличаются очень мало как друг от друга, так и от теоретической кривой. В то же время кривая, полученная по гомпит-модели, представляется менее удовлетворительной. Разумеется, хотелось бы иметь некоторые количественные критерии для сравнения разных моделей и для проверки адекватности каждой из рассматриваемых моделей данным наблюдений. Мы займемся теперь этой проблемой.

Обсуждение Эконометрика для начинающих (Дополнительные главы)
Комментарии, рецензии и отзывы