2.12. использование оцененной модели для прогнозирования
2.12. использование оцененной модели для прогнозирования
Пусть мы имеем модель наблюдений в виде модели простой линейной регрессии
yi =а + pxt + , і = 1,..., n,
и хотим дать прогноз, каким будет значение объясняемой переменной y при некотором выбранном (фиксированном)
значении x * объясняющей переменной x , если мы будем продолжать наблюдения.
Мы умеем оценивать коэффициенты а и /3 методом наименьших квадратов, и естественно использовать для целей прогнозирования получаемую в результате такого оценивания (подобранную) модель линейной связи y = a + /?x ,|
что приводит к прогнозируемому значению объясняемой переменной, равному
y = аг + р x ,
Вопрос только в том, сколь надежным является выбор такого значения в качестве прогнозного. И здесь надо иметь в виду следующее.
Поскольку мы используем для прогноза оценки, полученные, исходя из модели наблюдений
yi = а + f5xi + єі , i = 1,...,n, то для того, чтобы этот прогноз
был осмысленным, нам по необходимости приходится предполагать, что структура модели наблюдений и ее параметры не изменятся при переходе к новому наблюдению, так что соответствующее x * значение y = y * должно описываться тем же
линейным соотношением y * = а + /3x * +є*. В таком случае,
мы по-существу имеем дело с расширенной линейной моделью с
n +1 наблюдениями, в которой дополнительное наблюдение
удовлетворяет соотношению
yn+1 = y , xn+1 = x .
При этом, случайная величина є * должна иметь то же распределение, что и случайные величины si , i = 1,^, n, и должна образовывать вместе с ними множество случайных величин, независимых в совокупности.
Итак, мы договорились, что в расширенной модели
y * = а + fix * + є* .
Выбирая в качестве прогноза для y * значение
y*=а + /3x* ,мы тем самым допускаем ошибку прогноза, равную y * y * = a + fi x *j-(a + fix * + s*^ = {a -a) + [fi fijx * є* .
Поскольку вычисленные оценки a ,fi являются (как мы уже выяснили выше) реализациями случайных величин, наблюдаемая ошибка прогноза также является реализацией случайной величины Y* Y* и включает два источника неопределенности:
неопределенность, связанную с отклонением вычисленных значений случайных величин а ,fi от истинных значений параметров a,fi ;
неопределенность, связанную со случайной ошибкой є* в (n + 1) м наблюдении.
При наших стандартных предположениях о линейной модели наблюдений ошибка прогноза является случайной величиной Y* Y*, имеющей математическое ожидание
E (У* Г) = E( а -а) + x * E (fi -fi}E [є*) = 0 .
(Мы использовали здесь справедливые при выполнении
стандартных предположений соотношения
E(a) = a, EЩ = fi, E[є*) = 0 .)
Точность прогноза характеризуется дисперсией ошибки прогноза
d[y* Г) = d(oc + fix*-a-fix*-£*) = d(« + j?x*-є*} .
Здесь использован тот факт, что сумма а + fix * неслучайна (хотя ее точное значение и не известно). Далее, из предположенной независимости случайных ошибок єі , i 1,...,n, и
є вытекает независимость случайных величин Y = а + fix (эта величина зависит от случайных ошибок si , i 1,...,n) и
є* (последняя не зависит от случайных ошибок єі , i 1,...,n ). В силу же независимости Y* = а + (5x* и є*,
(использовано правило сложения дисперсий). Остается заметить, что
o-J, = D(f *) = da + fi x * = cr
1 (x* x I
— + — n
n
где, как обычно, x = I ^xA In . (Мы не будем выводить
i=1
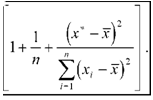 эту формулу.) Таким образом,
эту формулу.) Таким образом,
)(#Y*)
Если случайные ошибки єі , i = 1,..., n, имеют нормальное распределение, то тогда случайные величины 7* =а + J3 x * и У* Y*
также имеют нормальные распределения. При этом, ошибка прогноза У* Y* имеет нормальное распределение с нулевым математическим ожиданием и дисперсией, вычисляемой по последней формуле.
Разделив разность У* Y* на квадратный корень из ее дисперсии, получаем случайную величину
Y * Y *
имеющую стандартное нормальное распределение N(0,l). Заменяя в правой части выражения для <72^,_г неизвестное значение а1 его несмещенной оценкой S2 = RSS/(n 2), получаем оценку дисперсии d(y* Y*) в виде
| о 2 _ S 2 | 1 (x * x) l + + 1 ; | |
Заменяв наконец в знаменателе отношение, имеющего стандартное нормальное распределение, неизвестное значение сг~,_г его оценкой s~,_r , приходим к t -статистике (t отношению)
Y * _ y *
t = ,
S Y'-Г
имеющей при выполнении сделанных предположений о модели наблюдений t -распределение Стьюдента t(п 2) с
(п 2) степенями свободы.
Последний факт дает возможность построения 100(1 — а)-процентного доверительного интервала для значения(#*Y*)/S Y,_Y, ,
а именно,
t ? (П-2)<(І> Y t)/st_Y. < Ц (Пна основании которого получаем 100(1 а) -процентный
доверительный интервал для Y*:
— здесь мы использовали то, что в силу симметрии распределения Стьюдента, tJyK) = -t (K).
2 2
Заметим, что при заданных значениях {yt,xi), i = 1,...,n, (по которым строится прогноз) доверительный интервал для Y* будет тем длинее, чем больше значение sf,_Y,. Последнее же равно S2 [і + n)] при x* = x и возрастает с ростом [х * x j . Это означает, что длина доверительного
интервала возрастает при удалении значения х*, при котором строится прогноз, от среднего арифметического значений
Таким образом, прогнозы для значений x *, далеко отстоящих от x, становятся менее определенными, поскольку длина соответствующих доверительных интервалов для значений объясняемой переменной возрастает.
Пример. Для данных о размерах совокупного располагаемого дохода и совокупных расходах на личное потребление в США в период с 1970 по 1979 год (в млрд. долларов, в ценах 1972 года), оцененная модель линейной связи имеет вид C = -66.595 + 0.978 • DPI.
Представим себе, что мы находимся в 1979 году и ожидаем увеличения в 1980 году совокупного располагаемого дохода (в тех же ценах) до DPI * = 1030 млрд. долларов. Тогда прогнозируемый по подобранной модели объем совокупных расходов на личное потребление в 1980 году равен
Г - 2) • Sf._r < Y*< Г + tx_^n 2) • st_r
C1980 =-66.595 + 0.978 *1030 = 940.75 ,
так что если выбрать уровень доверия 0.95, то
tcrit = t,_005 (n " 2) = 10.975(8) = 2.306
2
и доверительный интервал для соответствующего DPI * = 1030 значения C1980 имеет вид
940.75 2.306 * 9.8228 < C1980 < 940.75 + 2.306 * 9.8228 ,
т. е.
940.75 22.651 < C1980 < 940.75 + 22.651 ,
или
918.099 < C1980 < 963.401
Заметим, что интервал достаточно широк и его нижняя граница допускает даже возможность некоторого снижения уровня потребления по сравнению с предыдущим годом.
В действительности, в 1980 г. совокупный располагаемый доход достиг 1021 млрд. долларов, а совокупное потребление — 931.8 млрд. долларов. Тем самым, ошибка прогноза составила
І940.75 931.8
1- 1■ 100 = 0.96\%.
931.8
Если бы мы исходили при прогнозе из действительного значения DPI1980 = 1021, анеиз DPI * = 1030, то прогнозируемое значение для C1980 равнялось бы 931.94 и ошибка прогноза составила всего лишь
І931.94 931.8
1- 1■ 100 = 0.015\%.
931.8
Проиллюстрируем, наконец, как изменяется в этом примере длина 95\%-доверительных интервалов в интервале наблюдавшихся значений объясняющей переменной DPI. На гра
В случае модели множественной линейной регрессии
 |
И
точечный прогноз значения у * = x * + є" , соответствующего фиксированному набору x* = (x^x*р) значений объясняющих переменных, дается формулой
j=i
где в 1,---,0 р — оценки наименьших квадратов параметров в 1,..., в р . Интервальный прогноз имеет вид
Г*1_Jn р)srr < Г< Г + tx_^(n р). sr_Y,
где
S2 {l + x *(XTX )_1 (x *)Г)
— оценка дисперсии ошибки прогноза, а S2 = RSS/{n p)- несмещенная оценка дисперсии
сг2 случайных ошибок.

Обсуждение Институт экономики переходного периода
Комментарии, рецензии и отзывы