3.5. коррекция статистических выводов при автокоррелированности ошибок
3.5. коррекция статистических выводов при автокоррелированности ошибок
Пусть мы имеем дело с наблюдениями, производимыми последовательно через равные промежутки времени (ежедневные, еженедельные, ежеквартальные, ежегодные статистические данные) и выявляем по графику зависимости стандартизованных остатков c: e i /S от i тенденцию сохранения знака соседних наблюдений. В таком случае мы можем подозревать нарушение условия независимости случайных ошибок є 1,..., є n в принятой нами модели наблюдений
yi = &1 xt 1+•••+#pxtp +£і , i = n
в форме положительной автокоррелированности ряда ошибок.
Простейшей моделью автокоррелированности ошибок является модель авторегрессии первого порядка:
где р | < 1, а 8 i , i = 2,...,п, — независимые в совокупности случайные величины, имеющие одинаковое нормальное распределение n(o,а2). Тогда гипотеза
Ho: р= 0
соответствует (при нашем предположении о нормальности распределения случайных ошибок) независимости в совокупности случайных величин є 1,...,єп. В качестве альтернативной используем гипотезу
Ha : Р>0,
соответствующую положительной автокоррелированности случайных величин є 1,..., єп (т. е. тенденции преимущественного сохранения знака случайной ошибки при переходе от i го наблюдения к i + 1-му). Если гипотеза H0 : р 0 отклоняется критерием Дарбина-Уотсона в пользу альтернативной гипотезы HA : р > 0, то для получения правильных статистических выводов относительно коэффициентов модели необходима соответствующая коррекция.
Итерационная процедура Кохрейна-Оркатта
(Cochrane-Orcutt).
Умножим обе части выражения для (i -1) -го наблюдения
на р, так что
Pyi-1 = ®1Pxi-1,1 +■■■+&pPxi _1, p +pst _1 , і = І..^ ^ и вычтем обе части полученного выражения из соответствующих частей выражения для i -го наблюдения:
yi ~Pyi-1 = #1 (xu ~Pxi-1,1 )+—+0p(xi,p ~Pxi-1,p) + -P£м) .
Тем самым мы приходим к преобразованной модели наблюдений
 |
Иными словами, случайные ошибки в преобразованной модели удовлетворяют стандартным предположениям.
Следовательно, в рамках преобразованной модели никакой дополнительной коррекции обычных статистических выводов о коэффициентах модели не требуется. Проблема только в том, что используемое в процессе преобразования модели значение коэффициента р нам не известно. Поэтому реально провести
указанное преобразование невозможно. Вместо этого можно пытаться заменить указаное преобразование какой-либо его аппроксимацией с заменой неизвестного значения р на его
оценку по данным наблюдений. Конечно, при использовании такой аппроксимации мы уже не можем гарантировать, что є 2,..., є П в преобразованной модели будут независимыми в совокупности случайными величинами, однако есть некоторая надежда на то, что эти ошибки все же будут обнаруживать меньшую автокоррелированность по сравнению с ошибками в исходной модели.
Описываемая здесь процедура Кохрейна-Оркатта использует для получения аппроксимации теоретического преобразования оценку для р в виде
| п | 1 п |
| r = Z eiei-і/ | |
| 1=2 1 | i=2 |
 |
еще остается выраженная автокоррелированность, то процесс преобразования применяют уже к преобразованной модели и еще раз уточняют значения параметров и т.д., пока последовательно уточняемые значения параметров не перестанут изменяться в пределах заданной точности.
Заметим, наконец, что обычно мы предполагаем, чтоXi, = і. Соответственно, для первой объясняющей переполучаем
i і
менной
Xi ,1
Xi ,1
r X
i-1,1
так что фактически мы имеем преобразованную модель
y* = а* + 02Xi,2---+°pX*,p + £*і ,
і = 2,..., n,
с а* -вх( — г). Получив в этой модели оценку а * для
а *, мы можем оценить параметр в 1 исходной модели, просто
полагая
Пример. Проанализируем статистические данные о совокупных потребительских расходах (CONS) и денежной массе
(MONEY) в США за 1952—1956 г. г. (квартальные данные, в
млрд. долларов).
| obs | MONEY | CONS | obs | MONEY | CONS |
| 1952:1 | 159.3 | 214.6 | 1954:3 | 173.9 | 238.7 |
| 1952:2 | 161.2 | 217.7 | 1954:4 | 176.1 | 243.2 |
| 1952:3 | 162.8 | 219.6 | 1955:1 | 178.0 | 249.4 |
| 1952:4 | 164.6 | 227.2 | 1955:2 | 179.1 | 254.3 |
| 1953:1 | 165.9 | 230.9 | 1955:3 | 180.2 | 260.9 |
| 1953:2 | 167.9 | 233.3 | 1955:4 | 181.2 | 263.3 |
| 1953:3 | 168.3 | 234.1 | 1956:1 | 181.6 | 265.6 |
| 1953:4 | 169.7 | 232.3 | 1956:2 | 182.5 | 268.2 |
| 1954:1 | 170.5 | 233.7 | 1956:3 | 183.3 | 270.4 |
| 1954:2 | 171.6 | 236.5 | 1956:4 | 184.3 | 275.6 |
Результаты оценивания линейной модели наблюдений yi = а + р xi +є i , i = 1,...,20,
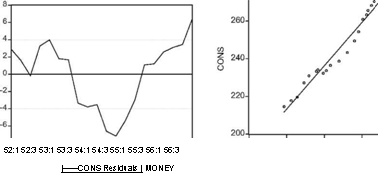
 в которой yi — значения объясняемой переменной CONS, a xi значения объясняющей переменной MONEY, приведены токоррелированности ошибок в принятой модели наблюдений. Два следующих графика дают представление о рассеянии значений переменных и о поведении остатков.
в которой yi — значения объясняемой переменной CONS, a xi значения объясняющей переменной MONEY, приведены токоррелированности ошибок в принятой модели наблюдений. Два следующих графика дают представление о рассеянии значений переменных и о поведении остатков.
 280т 1
280т 1
Здесь наблюдаются серии остатков, имеющих одинаковые знаки, что как раз и характерно для моделей, в которых имеется положительная автокоррелированность ошибок.
Для подтверждения положительной автокоррелированно-сти ошибок используем критерий Дарбина-Уотсона. По таблицам находим нижнюю границу для критического значения d005 при n = 20: dL 005 = 1.20 . Полученное при оценивании модели значение DW = 0.328 существенно меньше этой нижней границы, так что гипотеза H0: р = 0 отвергается в пользу альтернативной гипотезы HA: р > 0. Для коррекции статистических выводов используем процедуру Кохрейна-Оркатта.
Прежде всего находим оценку для неизвестного значения
n I n
коэффициента р: r = ^eiei_х j ^в2_х = 0.874 . Основываясь на
i=2 / г=2
этой оценке, переходим к преобразованной модели, оценивание которой дает следующие результаты:
| Included observations: 19 after adjusting endpoints | |||
| Variable | Coefficient Std. Error | t-Statistic | Prob. |
| 1 X' | -30.777 14.043 2.795 0.609 | -2.192 4.593 | 0.0426 0.0003 |
| R-squared | 0.554 Durbin-Watson stat | 1.667 | |
Хотя в преобразованной модели коэффициент детерминации существенно ниже, чем в непреобразованной модели, значение статистики Дарбина-Уотсона теперь превышает верхнюю границу для критического значения d005,
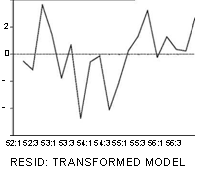
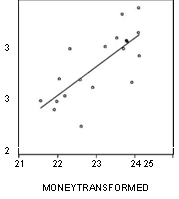 соответствующего n = 19. (В преобразованной модели наблюдений на единицу меньше, чем в исходной, так как при преобразовании используются запаздывающие значения обеих переменных). Поэтому гипотеза о независимости в совокупности ошибок в преобразованной модели не отвергается (в пользу гипотезы об их положительной автокоррелированности). Два следующих графика дают представление о рассеянии значений преобразованных переменных и о поведении остатков в преобразованной модели.
соответствующего n = 19. (В преобразованной модели наблюдений на единицу меньше, чем в исходной, так как при преобразовании используются запаздывающие значения обеих переменных). Поэтому гипотеза о независимости в совокупности ошибок в преобразованной модели не отвергается (в пользу гипотезы об их положительной автокоррелированности). Два следующих графика дают представление о рассеянии значений преобразованных переменных и о поведении остатков в преобразованной модели.
 40
40
-6
4
Обратим внимание на существенно более нерегулярное поведение остатков по сравнению с исходной моделью.
Обращаясь к результатам оценивания коэффициентов в преобразованной модели, отметим значительное (более, чем в 5 раз!) возрастание оценки стандартной ошибки , что подтверждает сделанное ранее замечание о занижении стандартных ошибок при неучете имеющейся в действительности положительной автокорреляции случайных ошибок в модели наблюдений. Столь существенное возрастание значения
приводит к возрастанию более, чем в 5 раз, и ширины доверительного интервала для мультипликатора /3. Если при оценивании исходной линейной модели 95\%-доверительный интервал для этого параметра имел вид 2.058 < /3 < 2.542 , то при оценивании преобразованной модели мы получаем интервал 1.516 <(3 < 4.074.
Рассмотренный пример ясно демонстрирует опасность пренебрежения возможной неадекватностью построенной модели в отношении стандартных предположений об ошибках и необходимость обязательного проведения в процессе подбора подходящей модели связи между теми или иными экономическими факторами анализа остатков, полученных при оценивании выбранной модели.
Более того, используя преобразованную модель, можно получить улучшенную модель для прогнозирования объемов расходов на потребление при планируемых объемах денежной массы. Поясним это на примере простой линейной модели
yi =а + р xi +st , i = 1,...,n.
Предполагая, что є i p є i_1 = 8 i , i 2,...,n, и используя оценку r для коэффициента р, переходим к преобразованной модели у* = а* + fi х' + є'і , і = 2,...,п,
с у*= уі rу_и х*= (хі r xt_x), і = 2,п и
a* =a(l r),
и получаем в рамках этой модели оценки а * и /3 параметров а* и fi, так что оцененная модель линейной связи между преобразованными переменными имеет вид
у* = а * + (3 х* , і = 2,...,п.
В исходных переменных последние соотношения принимают вид
уі r уі= а (1 г) + fi (x,. r хі_х ) , / = 2,..., n, где а a Y(l r), откуда получаем:
уі =а + /З хі + r(y,._i-а-р хі_іУ і = 2,...,п.
Если мы собираемся теперь прогнозировать будущее значение уп+1 , соответствующее плановому значению хп+1 объясняющей переменной, то естественно воспользоваться полученным соотношением и предложить в качестве прогнозного для уп+1 значение
уп+і = « + Р xn+i + r[yn-а-Ь хп)
При таком способе вычисления прогнозного значения для уп+1 учитывается тенденция сохранения знака остатков: если в последнем наблюдении наблюдавшееся значение уп превышало значение а + Р хп , предсказываемое линейной моделью связи у = а + (3 x , то и последующее значение уп+1
прогнозируется с превышением значения а + Р хі+1 , предсказываемого этой линейной моделью связи при r > 0 . Если же значение yn меньше, чем а + /? xn , то тогда будущее значение yn+1 прогнозируется меньшим значения а + /? xi+1 .
Пример. Продолжим рассмотрение предыдущего примера.
В этом примере
r = 0.874, а = а 7(1 r) = -30.777/(1 0.874) = -244.262 ,
/3 = 2.795. Наблюдавшимся значениям x2,...,x20 можно сопоставить:
наблюдавшиеся значения y2,..., y20;
значения
yi =-154.700 + 2.300x,. ,
получаемые по модели, построенной без учета автокорре-лированности ошибок;
значения
у, =-244.262 + 2.795x,. ,
получаемые по модели, параметры которой скорректированы с учетом автокоррелированности ошибок;
значения
yt =-244.262 + 2.795 xi + 0.874(ум + 244.262-2.795 xM) ,
отличающиеся от значений, указанных в предыдущем пункте, учетом значения остатка в предшествующем наблюдении.
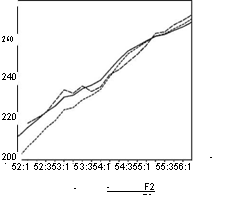
Ниже приведены графики значений , получаемых указанными тремя методами, и графики соответствующих им расхождений yyi — yt. Индексы 1, 2, 3 указывают на один из трех способов получения значений уі , в том порядке, в котором они были перечислены выше).
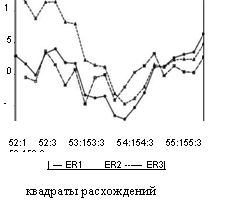 |
15
Сравним
средние
20
(l/19)^ (jX yi) при использовании указанных трех методов
і=2
вычисления значений yi. Эти средние квадраты равны, соответственно,
MSE1 = 14.583, MSE2 = 37.025, MSE3 = 4.533,
что говорит о большей гибкости прогноза, построенного по последнему (третьему) методу.
Рассмотрим еще одно важное следствие автокоррелиро-ванности ошибок в линейной модели
yt = а + р xt +st , і = 1,...,n,
с єі -рєі_1 -8і , і = 2,...,п. Преобразование
y = yi -pyixl = xi -рхі-1
приводит к модели наблюдений
у =а' + р xl+S;,і = 1,...,п,
на основании которой получаем соотношение
y = а(1 -p) + Pyi-1 +Р(хі ~Рхі-1 ) +8t, і = ^--мn.
Вспомним теперь о нашем предположении, что 0 < р < 1, и преобразуем последнее соотношение следующим образом:
У і = Я I1 -Р) + Уг-1 " I1 -Р )Уг-1 + Р (Хг Xi-1 +(l P)Xi-1 ) +#i
= yi-1 +11 РІрс + p xt_1 y_1) + p (xt x_1 ) + Si,
или
Ay = p Axi +(p- _1 -a-p x,_1 ) + St . Здесь Ayi = yt -yi_l, Axt = xi -xt_1 и -1 <(p1)< 0.
Второе слагаемое в правой части по-существу поддерживает «долговременную» линейную связь (тенденцию) y = а + Р x.
Если в момент і 1 отклонение yi_1 от {а + Р xi_1) положительно [yi_1 > а + Р xi_1), то второе слагаемое будет отрицательным, действуя в сторону уменьшения приращения Л Уі ~ Уі ~ Уі-1. Если же отклонение yi_1 от {а + Р xi_1) отрицательно {yi_1 < а + Р xi_1), то второе слагаемое будет положительным, действуя в сторону увеличения приращения
Указанная модель коррекции приращений переменной y использует «истинные» значения параметров а,Р,р. Поскольку эти значения нам не известны, мы в состоянии построить только аппроксимацию такой модели, использующую оценки параметров. При этом естественно воспользоваться
оценкой r и уточненными оценками а ,Р, полученными на базе преобразованной модели.
В рассмотренном примере аппроксимирующая модель
коррекции приращений принимает вид
I Ayt = 2.795 A xt 0.126 (yt_1 + 244.262 2.795 xt_1 ).|
3.6. КОРРЕКЦИЯ СТАТИСТИЧЕСКИХ ВЫВОДОВ ПРИ НАЛИЧИИ СЕЗОННОСТИ. ФИКТИВНЫЕ ПЕРЕМЕННЫЕ
Приведенный ниже график показывает динамику изменения совокупного располагаемого дохода DPI и объемов продаж SALES лыжного инвентаря в США (квартальные данные; DPI — в млрд долларов, SALES — в млн долларов, в ценах 1972 г.).
200 -, 1
160 "
1208064 65 66 67 68 69 70 71 72 73
| SALES DP7|
Оценивание линейной модели связи указанных переменных дает следующие результаты. Dependent Variable: SALES Method: Least Squares Sample: 1964:1 1973:4 Included observations: 40
| Variable | Coefficient | Std. Error t-Statistic | Prob. |
| C | 29.97613 | 6.463626 4.637665 | 0.0000 |
| DPI | 0.108402 | 0.036799 2.945768 | 0.0055 |
| R-squared | 0.185904 | Mean dependent var | 48.94571 |
| Adjusted R-squared | 0.164481 | S. D. dependent var | 3.852032 |
| S. E. of regression | 3.521017 | Akaike info criterion | 5.404084 |
| Sum squared resid | 471.1074 | Schwarz criterion | 5.488528 |
| Log likelihood | -106.0817 | F-statistic | 8.677546 |
| Durbin-Watson stat | 1.874403 | Prob (F-statistic) | 0.005475 |
Коэффициент при переменной DPI статистически значим. Однако график стандартизованных остатков (приведенный для удобства в двух формах)
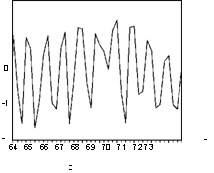
 |
2
обнаруживает явную неадекватность построенной модели имеющимся наблюдениям. Однако характер этой неадекватности таков, что он не улавливается критерием Дарбина-Уотсона: значение 1.874 статистики Дарбина-Уотсона близко к 2. И это не удивительно: за положительными остатками с равным успехом следуют как положительные, так и отрицательные остатки, что соответствует практическому отсутствию корреляции между соседними ошибками и подтверждается диаграммой рассеяния
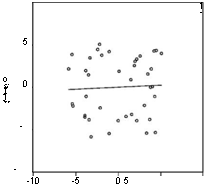 |
(Здесь RES01 — переменная, образованная остатками от подобранной модели линейной связи, a RES01(-1)— переменная, образованная запаздывающими на один квартал значениями переменной RES01.)
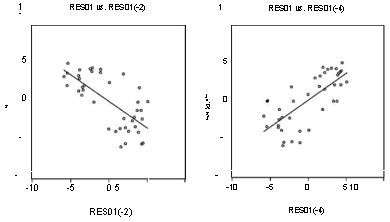 |
10
В то же время, налицо отрицательная коррелированность остатков для наблюдений, отстоящих на два квартала, и положительная — для наблюдений, отстоящих на четыре квартала:
В отличие от критерия Дарбина-Уотсона, критерий Брой-ша-Годфри «замечает» такую коррелированность: допуская коррелированность ошибок для наблюдений, разделенных двумя кварталами, получаем P — value 0.000037 , что ведет к безусловному отклонению гипотезы о независимости ошибок.
Обратим теперь внимание на весьма специфическое поведение остатков. Все остатки, соответствующие первому и четвертому кварталам, положительны, авсе (за исключением двух) остатки, соответствующие второму и третьему кварталам, отрицательны. Такое положение, конечно, просто отражает тот факт, что спрос на зимний спортивный инвентарь возрастает в осенне-зимний период и снижается в весенне-летний период года, т. е. имеет сезонный характер.
Построенная нами модель не учитывает фактор сезонности спроса и потому оказывается неадекватной. Вследствие этого, такая модель не может, в частности, использоваться для прогнозирования объема спроса в зависимости от величины совокупного располагаемого дохода.
Для коррекции моделей связи в подобных ситуациях часто привлекают искусственно построенные переменные — «фиктивные переменные» («dummy» variables). В нашем случае в качестве такой дополнительной переменной можно взять, например, переменную DUMMY, значение которой равно 1 для первого и четвертого кварталов и равно 0 для второго и третьего кварталов. Добавление такой переменной в качестве объясняющей позволяет учесть сезонные колебания спроса. Оценивание расширенной модели дает следующие результаты.
 Оцененное значение 6.029 коэффициента при переменной DUMMY фактически означает, что спрос на лыжный инвентарь в течение первого и четвертого кварталов возрастает по сравнению со спросом в течение второго и четвертого кварталов в среднем примерно на 6 млн долларов (в ценах 1972 г.). Следующий график иллюстрирует качество подобранной расширенной модели.
Оцененное значение 6.029 коэффициента при переменной DUMMY фактически означает, что спрос на лыжный инвентарь в течение первого и четвертого кварталов возрастает по сравнению со спросом в течение второго и четвертого кварталов в среднем примерно на 6 млн долларов (в ценах 1972 г.). Следующий график иллюстрирует качество подобранной расширенной модели.
г60
-55
-45 -40
64" '65' б6" б7" бУ ' '69'' '7(0' У1" У2'' V3''
[——Residual Actual Fitted
На сей раз значение P value для статистики критерия Бройша-Годфри равно 0.157197 против прежнего значения 0.000037, так что этот критерий теперь не отвергает гипотезу независимости случайных ошибок є 1,..., є n.
По-существу, мы подобрали две различные модели линейной связи между DPI и SALES:
модель
SALES = 26.21787 + 0.112653DPI
для весенне-летнего периода; модель
SALES = (26.21787 + 6.028524) + 0.112653DPI
для осенне-зимнего периода.
При этом, предельная склонность к закупке лыжного инвентаря в обеих моделях остается одинаковой и оценивается величиной 0.112653.
Замечание. Вместо подбора отдельных моделей для осенне-зимнего и весенне-летнего периодов можно было бы заняться подбором отдельных моделей для каждого из четырех кварталов года. С этой целью в качестве дополнительных объясняющих переменных можно взять, например, переменные DUMMY4, DUMMY1, DUMMY2 , принимающие значение 1, соответственно, в четвертом, первом и втором кварталах, и равные нулю в остальных кварталах. При оценивании такой расширенной модели для наших данных оказывается незначимым коэффициент при DUMMY2, что означает близость в среднем уровней продаж во втором и в третьем кварталах. Более того, оказываются близкими оценки коэффициентов при переменных DUMMY4 и DUMMY1. Гипотеза о совпадении двух последних коэффициентов не отвергается, и в итоге мы возвращаемся к модели с одной фиктивной переменной DUMMY, которую мы уже оценили ранее.
Использование фиктивных переменных полезно при анализе агрегированных (объединенных) данных, полученных при объединении наблюдений, относящихся к различным полам (мужчины и женщины), к различным возрастным, языковым и социальным группам, к различным периодам времени. В таких ситуациях модели, построенные по отдельным группам, могут существенно различаться, и тогда модель, построенная по объединенным данным, не учитывает этого различия. Привлечение фиктивных переменных позволяет оценить значимость такого различия и по результатам этой оценки остановиться на модели с агрегированными данными или на модели, в которой учитывается различие параметров связи для различных групп (периодов времени).
В качестве примера, попробуем построить модель связи
между переменными Z и X, которые в 15 наблюдениях имели следующие значения:
| X | Z | X | Z | X | Z |
| 1 | 1.257 | 6 | 0.865 | 11 | 1.804 |
| 2 | 1.812 | 7 | 1.930 | 12 | 1.956 |
| 3 | 3.641 | 8 | 2.944 | 13 | 3.134 |
| 4 | 4.401 | 9 | 4.316 | 14 | 4.649 |
| 5 | 5.561 | 10 | 5.323 | 15 | 4.559 |
Этим данным соответствует приведенная ниже диаграмма рассеяния;
Прямая на диаграмме соответствует подобранной модели связи
Z = 2.414 + 0.099X;
t статистика для коэффициента при X принимает значение 1.087, что дает P value 0.297 и ведет к неотвержению гипотезы о равенстве этого коэффициента нулю. Регрессия переменной Z на переменную X признается незначимой.
Z vs. X
6
54N 3210-, , , , ,
0 5 10 15 20
X
График указывает на наличие трех режимов линейной связи между переменными Z и X, соответствующим 5 первым, 5 центральным и 5 последним наблюдениям. Коэффициент при X кажется одинаковым для всех трех режимов, тогда как постоянные различаются.

В то же время, график остатков от подобранной модели связи явно указывает на неправильную спецификацию модели:
3
2
1
0 -1 -2
-3.,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
| RESID01 |
Чтобы учесть обнаруженное по графику остатков наличие трех режимов, привлечем в качестве дополнительных объясняющих переменных две фиктивные переменные: переменную D2, равную 1 впяти центральных наблюдениях и равную 0 в остальных наблюдениях, а также переменную D3, равную 1 в пяти последних наблюдениях и равную 0 в остальных наблюдениях. Оценивание расширенной модели с участием этих дополнительных объясняющих переменных дает следующий результат:
| Variable | Coefficient | Std. Error | t-Statistic | Prob. |
| C | 0.264368 | 0.274073 | 0.964591 | 0.3555 |
| X | 1.023398 | 0.070765 | 14.46185 | 0.0000 |
| D2 | -5.375960 | 0.430449 | -12.48920 | 0.0000 |
| D3 | -10.34806 | 0.748910 |

Обсуждение Институт экономики переходного периодаКомментарии, рецензии и отзывы 3.5. коррекция статистических выводов при автокоррелированности ошибок: Институт экономики переходного периода, Носко Владимир Петрович, 2000 читать онлайн, скачать pdf, djvu, fb2 скачать на телефон Предлагаемое учебное пособие имеет своей целью обеспечить базу для изучения вводного полугодового курса эконометрики, когда в распоряжении преподавателя имеется всего порядка 12 лекций и некоторое количество часов практических занятий.
|