Тема 4.2 формальные статистические критерии
Тема 4.2 формальные статистические критерии
Помимо графических существует довольно много процедур, предназначенных для проверки выполнения стандартных предположений о линейной модели наблюдений, использующих статистические критерии проверки гипотез. Остановимся только на нескольких таких процедурах. В каждой из них в качестве нулевой фактически берется гипотеза
H0:el9...9sn~U.d.N(0, а2).
Однако соответствующие критерии приспособлены для выявления специфических нарушений стандартных предположений, что делает каждый из критериев особо чувствительным именно к тем нарушениям, на которые он «настроен».
Критерий Голдфелда — Квандта (Goldfeld-Quandt test). Если графический анализ остатков указывает на возможную неоднородность дисперсий ошибок D(st)9 т.е. на наличие гетероскедастичности, то:
сначала наблюдения, насколько это возможно, упорядочивают по предполагаемому возрастанию дисперсий случайных ошибок;
затем отбрасывают г центральных наблюдений (для более надежного разделения групп с малыми и большими дисперсиями случайных ошибок), так что для дальнейшего анализа остается (п г) наблюдений;
производят оценивание выбранной модели раздельно по первым (п г)/2 и по последним (п г)/2 наблюдениям;
вычисляют отношение F = RSS2/RSSX остаточных сумм квадратов, полученных при подборе модели по последним (п г)/2 (остаточная сумма квадратов RSS2) и по первым (п г)/2 (остаточная сумма квадратов RSS{) наблюдениям.
При принятии решения учитывают, что если все же D(£t) <729 і = 1, п9 (дисперсии однородны) и выполнены остальные стандартные предположения о модели наблюдений, включая предположение о нормальности ошибок, то отношение F = RSS2/RSS{ имеет F-pacnpe-
деление Фишера F степенями свободы;
^ п-г п-г Л (п-г Л (п-г л
— р, — Р с — р и ——-р
п-г п-г
-р9 р |, соответствующий вы• гипотеза Я0 : D(st) = <т2, і = 1, п9 (гомоскедастичность, однородность дисперсий ошибок — homoscedasticity) отвергается, если вычисленное значение F-отношения «слишком велико», т.е. превышает
критический уровень Fx_a бранному уровню значимости а.
Критерий Дарбина — Уотсона (Durbin-Watson test) применяется, когда наблюдения производятся последовательно во времени, с равными интервалами, и график изменения остатков во времени указывает на наличие авто-коррелированности (зависимости во времени) случайных составляющих є( модели наблюдений. Предполагается, что структура автокоррелированности определяется соотношением
є^рє^ + 8І9 / = 1,...,и,
где р < 1, a Si9 і = 1, п, — независимые в совокупности случайные величины, имеющие одинаковое нормальное распределение N(0, сг|), причем St не зависит статистически от st_s для s > 0.
Статистика Дарбина — Уотсона (Durbin-Watson statistic) определяется соотношением
І(*,-«м)2
DW = — ,
г2 i =
где el9еп— остатки, получаемые при оценивании линейной модели наблюдений.
В качестве нулевой здесь берется гипотеза
Я0:/7=0,
соответствующая (при нашем предположении о нормальности распределения случайных ошибок) независимости в совокупности случайных величин єІ9 єп. В качестве альтернативной при анализе экономических данных чаще всего используют гипотезу
#0 :р>0,
соответствующую положительной автокоррелированности случайных величин єІ9єп (т.е. тенденции преимущественного сохранения знака случайной ошибки при переходе от /-го к (і + 1)-му наблюдению).
Статистика DW принимает значения в интервале от 0 до 4. Рассматриваемая как случайная величина, она имеет при гипотезе Н0 : р = 0 (т.е. если эта гипотеза верна) функцию плотности р(х)9 симметричную относительно точки х = 2 — середины этого интервала. Если в действительности р = р* > О, то значения статистики DОтяготеют к левой границе интервала. Поэтому в соответствии с общим подходом к построению односторонних статистических критериев необходимо было бы для выбранного нами уровня значимости а найти соответствующее ему критическое значение da (О < da < 2) и отвергать гипотезу Н0 : р=0в пользу Н0 : р> О при выполнении неравенстваDW<da.
Однако распределение статистики Дарбина — Уотсона зависит не только от п и/?, но и от конкретных значений xij9j = 1,р9 і = 1,п9 объясняющих переменных, что делает неосуществимым построение таблиц критических значений этого распределения. Дарбин и Уотсон преодолели это затруднение следующим образом. Предполагая, что в правой части модели наблюдений присутствует постоянная составляющая и отсутствуют запаздывающие значения объясняемой переменной, они нашли (при различных значениях пир) нижнюю dLa и верхнюю dUa границы интервала, в котором только и могут находиться критические значения da статистики Дарбина — Уотсона, независимо от того, каковы конкретные значения xij9j = 1, р9 і = 1, п. Иными словами,
0<dLa<da<dUa<2,
где dLa и dUa не зависят от конкретных значений xij9j = 1, р9 і = 1, п9 а определяются только количеством наблюдений, количеством объясняющих переменных и установленным уровнем значимости критерия. Гипотеза #0 : р= 0:
отвергается в пользу гипотезы НА : р > 0, если DW< dLa
не отвергается, если D W > dUa.
Если же dLa <DW< dUa9 то никакого вывода относительно справедливости или несправедливости гипотезы Н0 : р0 не делается.
При соблюдении этих правил вероятность ошибочного отвержения гипотезы #0 : р 0 не превосходит заданного уровня значимости а.
Критерий Харке — Бера (Jarque-Bera test) используется в ряде пакетов статистического анализа данных (например, в ЕViews) для проверки гипотезы #0 нормальности ошибок в модели наблюдений, точнее,
Я0: ех,...,£„ ~ U.d. N(09 а2)
(значение а2 не конкретизируется). Если эта гипотеза верна, то при большом количестве наблюдений п статистика
JB = n
(sample skewness) + (sample kurtosis 3)
имеет распределение, близкое к распределению хи-квадрат с 2 степенями свободы ^2(2), функция плотности которого имеет вид:
1 -р(х) = — е 2,х>0.
Здесь:
• sample skewness — выборочный коэффициент асимметрии
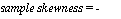
(т2У
з
■ч
sample kurtosis =—j;
sample kurtosis — выборочный куртозис
т4 ml
«,-=i
• el9 en — остатки, полученные при оценивании модели методом наименьших квадратов.
Если распределение ошибок действительно является нормальным, то значения выборочного коэффициента асимметрии близки к 0, а значения выборочного куртозиса — к 3. Существенное отличие выборочного коэффициента асимметрии от 0 указывает на несимметричность (относительно 0) графика функции плотности распределения ошибок («скошенность» распределения).
При нарушении условия нормальности распределения ошибок значения статистики JB имеют тенденцию к возрастанию. Поэтому гипотеза нормальности ошибок отвергается, если значения этой статистики «слишком велики», а именно если
JB >XL(2),
где х-аО)— квантиль распределения ^2(2), соответствующая уровню 1-а.
J Замечание 4.2.1. Критерии Дарбина — Уотсона и Голдфелда — Квандта являются точными (неасимптотическими — non-asymptotic tests) в том смысле, что они непосредственно учитывают количество наблюдений я. В противоположность этому, критерий Харке — Бера является асимптотическим (asymptotic test): распределение статистики JB хорошо приближается распределением \%2(2) только при большом количестве наблюдений. Поэтому вполне полагаться на результаты применения критерия Харке — Бера можно только в таких ситуациях. Помимо критерия Харке — Бера, в специализированные пакеты программ статистического анализа данных часто встраиваются и другие асимптотические критерии (например, критерии Уайта и Бройша — Годфри, которые рассматриваются ниже).
Критерий Бройша — Годфри (Breusch-Godfrey test) используется в ряде пакетов статистического анализа данных (например, в Е Views) для проверки гипотезы некоррелированности ошибок в модели наблюдений
у і = в хі і + • • • + 0Р xiP + є і , і = 1,..., л.
При наших предположениях (включающих нормальность распределения ошибок) это соответствует гипотезе независимости в совокупности случайных величин єі9 і = 1,п. Напомним, что критерий Дарбина — Уотсона основан на рассмотрении модели наблюдений, в которой случайные составляющие et связаны соотношением
є{ = ре{_х +<5), 1 = 1,..., л,
где р < 1, a Si9 і = 1, л, — независимые в совокупности случайные величины, имеющие одинаковое нормальное распределение уУ(0, <j2s), причем st не зависит статистически от st_s для s > 0.
В такой модели наблюдений случайные составляющие єі9 разделенные двумя или более периодами времени и очищенные от влияния промежуточных оказываются независимыми.
Критерий Бройша — Годфри допускает зависимость случайных составляющих єі9 разделенных К периодами времени и очищенных от влияния промежуточных Соответствующая модель зависимости имеет вид процесса авторегрессии порядка К:
єі=ахєі_х+... + акєі_к +8І9 ї = 1,..., л,
где опять 8І9 і = 1,л, — независимые в совокупности случайные величины, имеющие одинаковое нормальное распределение ;V(0, cr2s)9 причем St не зависит статистически от st_s для s > 0, а условие р < 1 заменяется следующим условием:
все корни многочлена 1 atz ... aKzK = 0, в том числе и комплексные, по модулю больше 1.
Статистика этого критерия равна л/?2, где R2 — коэффициент детерминации, получаемый при оценивании вспомогательной модели
Єі=Ухі+--+ УРхір+аЄі-+~+ акеі-к+Уі> / = 1,...,л,
где еХ9еп — остатки, полученные при оценивании основной модели наблюдений
уі=вхха+... + врх1р+єі9 1 = 1,..., л.
Недостающие значения е09ех_к заменяются нулями. В рамках вспомогательной модели проверяется гипотеза
Я0 : ах = ... = ак = 0.
Если эта гипотеза верна, то при большом количестве наблюдений п статистика критерия имеет распределение, близкое к распределению хи-квадрат с К степенями свободы. Гипотеза Н0 отвергается при заданном уровне значимости а, если вычисленное значение nR2 превышает критическое значение, равное квантили уровня (1-а) указанного распределения, т.е. если
nR2>(nR2)crit=xla(K).
Конечно, при интерпретации результатов применения критерия Бройша — Годфри следует помнить, что этот критерий асимптотический, тогда как критерий Дарбина — Уотсона точный. Однако, в свою очередь, возможность применения критерия Дарбина — Уотсона ограничивается тем, что он
допускает зависимость «очищенных» случайных ошибок только на один шаг, т.е. К = 1;
неприменим в ситуациях, когда в число объясняющих переменных включаются запаздывающие значения объясняемой переменной.
Критерий Бройша — Годфри свободен от этих ограничений.
Критерий Уайта (White test) используется в ряде пакетов статистического анализа данных (например, в Е Views) для проверки однородности дисперсий ошибок в модели наблюдений
у, = вх хп +... + вр xip + ei, і = 1,..., п.
Критерий имеет два варианта.
Вариант I. В рамках вспомогательной модели
р р
ef =а+ Ха;Л + Х#*/У + V" ' = Ъ • • •> и,
j = 2 j=2
где еХ9еп — остатки, полученные при оценивании основной модели наблюдений,
проверяется гипотеза
HQ:aj =0, у = 2,.
Статистика критерия равна nR2, где R2 — коэффициент детерминации, получаемый при оценивании последней модели. Если указанная гипотеза верна, то при большом количестве наблюдений п статистика критерия имеет распределение, близкое к распределению хи-квадрат с (2р -2) степенями свободы. Гипотеза #0 отвергается при заданном уровне значимости а, если вычисленное значение nR2 превышает критическое значение, равное квантили уровня (1 -а) указанного распределения, т.е. если
nR2>(nR2)crit=X2_a(2p-2).
Вариант И. В рамках вспомогательной модели
р р р
е] = <*1 + z°7 ху + s ILPjk Xijxik +vi> / = і,..W,
j=2 j=2 k=j
где een — остатки, полученные при оценивании основной модели наблюдений,
проверяется гипотеза
к=0, У = 2
°'[^=0, 2<j<k<p.
Статистика критерия равна nR2, где R2 — коэффициент детерминации, получаемый при оценивании последней модели. Если указанная гипотеза верна, то при большом количестве наблюдений п статистика критерия имеет расР2+Р~2
пределение, близкое к распределению хи-квадрат с -—^ степенями
свободы. Гипотеза Н0 отвергается при заданном уровне значимости а, если вычисленное значение nR2 превышает критическое значение, равное квантили уровня (1-а) указанного распределения, т.е. если
nR2>(nR2)crit=zL
р +р-2
Как и в случае критерия Бройша — Годфри, при интерпретации результатов применения обоих вариантов критерия Уайта следует помнить, что этот критерий асимптотический.
J Замечание 4.2.2. При описании критерия Уайта неявно предполагалось, что хп = 1. Если постоянная не включена в исходную модель наблюдений, то в моделях, оцениваемых на втором шаге обоих вариантов критерия Уайта, суммирование в первой сумме следует начинать с 7=1.
Критерий Рэмси RESET (Ramsey's Regression Specification Error Test) используется для проверки в рамках нормальной линейной модели
У і = вхп + — + вр*ір + et9 i = l,..., п.
предположения
E(st) = 0, i = l,...,w, из-за невыполнения которого возникает смещение оценок коэффициентов.
При помощи этого критерия можно выявить:
наличие «пропущенных» переменных (т.е. невключение в правую часть уравнения некоторых существенных переменных);
неправильную функциональную форму представления некоторых (или всех) переменных (например, неправильное использование логарифмов переменных вместо уровней этих переменных);
наличие корреляции между объясняющими переменными и ошибкой в уравнении регрессии (которая может быть вызвана, например, наличием ошибок измерения объясняющей переменной — об этом см. разд. 6).
Есть несколько вариантов критерия Рэмси. Рассмотрим вариант, используемый в пакете EViews. В этом варианте сначала оценивается заявленная модель наблюдений, и по результатам ее оценивания вычисляются значения
Л=^Лі+ —+ ^pV / = 1,...,л. Затем оценивается вспомогательная модель
Уі=0Ч+-" + Орхір+УІЇ +»+ Yr-9ri> i = l,...,я,
и в рамках этой модели проверяется гипотеза
HQyx=... = yr_x=0.
Если эта гипотеза верна, то при большом количестве наблюдений п статистика критерия имеет распределение, близкое к распределению хи-квадрат с (г 1) степенями свободы. Гипотеза Н0 отвергается при заданном уровне значимости а, если вычисленное значение nR2 превышает критическое значение, равное квантили уровня (1-а) указанного распределения, т.е. если
nR2>(nR2)crit=zL(r-VПо поводу выбора значения г нет общих рекомендаций. Рэмси рассматривал возможность включения в правую часть вспомогательного уравнения второй, третьей и четвертой степеней у.. Однако в более поздних работах другие авторы рекомендуют использовать только вторую степень j),..
Критерии Чоу (Chow tests). Чоу предложил два критерия для проверки стабильности модели на всем периоде наблюдений. Один из них — Chow breakpoint test — основан на проверке гипотезы о сохранении значений всех коэффициентов при переходе от одного подпериода полного периода наблюдений к другому и будет рассматриваться в рамках приводимого ниже примера. Другой — критерий Чоу на качество прогноза (Chow forecast test) — сравнивает качество прогнозов, сделанных на основе оценивания модели на одной части периода для значений объясняемой переменной на другой части периода, с качеством «прогнозов», сделанных на основе оценивания модели на всем периоде наблюдений. Более точно, возьмем на периоде наблюдений два отрезка:
/=1,..., п0 и / = п0 + 1,п.
Оценив коэффициенты модели
у і = в хі і + • • • + вр хіР + єі > ? = 1,
по всем п наблюдениям, получим прогнозные значения
yt(n i = n0 +l,...,w.
Наряду с этим оценим коэффициенты модели только по первым п0 наблюдениям. При этом получим прогнозные значения будущих значений объясняемой переменной
Уі(щ 1 = л0+1,...,л.
Если модель стабильна, то значения у£п0) не должны слишком сильно отличаться от значенийyt{n i = n0 + 1,п. Степень различия измеряет статистика
г (RSSn-RSSno)/(n-n0) RSSnJ(n0-p) '
где RSSn — остаточная сумма квадратов при оценивании модели на всем периоде наблюдений; RSS„Q— остаточная сумма квадратов при оценивании модели по первым
л о наблюдениям.
Если модель стабильна (и выполнены другие стандартные предположения), то указанная статистика имеет F-распределение, F(n л0, п0 р). Гипотеза о стабильности модели отвергается, если вычисленное значение этой статистики превышает значение Fx_a(n п0, п0 -р).
ПРИМЕР 4.2.1
Рассмотрим статистические данные по США за период с 1960 по 1985 г. о следующих макроэкономических показателях:
DPI — годовой совокупный располагаемый личный доход;
CONS — годовые совокупные потребительские расходы;
ASSETS — финансовые активы населения на начало календарного года.
(все показатели в млрд долл., в ценах 1982 г.). Данные приведены в табл. 4.2.
Характер изменения этих макроэкономических показателей демонстрирует график на рис. 4.19.
 Рассмотрим модель наблюдений
Рассмотрим модель наблюдений
CONSt = вх + 62DPIt + въ ASSETSt +єп / = 1 26,
где индексу t соответствует (1959 + ґ)-й год. Это модель с 3 объясняющими переменными:
Хх =1, Х2= DPI, Х3 = ASSETS. Оценивание этой модели дает следующие результаты: R2 = 0.9981,
в2 = 0.672, Р-значение = 0.0000;
#з = 0.174, Р-значение = 0.0069;
так что оценки коэффициентов при объясняющих переменных Х2 = DPI, Хъ ASSETS имеют высокую статистическую значимость.
Ниже представлены диаграмма рассеяния для предсказанных (CONSF) и наблюдаемых (CONS) значений переменной CONS (рис. 4.20), а также график зависимости стандартизованных остатков ct = — (RESJSTAND) от предS
сказанных (CONSF) значений переменной СОЛ/Б (рис. 4.21).
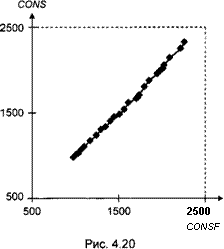 |  | ||
Поскольку первый из приведенных в этом примере графиков указывает на возрастание годовых потребительских расходов с течением времени, для реализации процедуры Голдфелда — Квандта естественно воспользоваться уже имеющимся упорядочением наблюдений во времени (это и будет направлением ожидаемого возрастания дисперсий случайных ошибок). Выделим из 26 наблюдений две группы, состоящие из первых 10 и последних 10 наборов значений (хп, xt2, хв), соответствующие периодам с 1960 по 1969 г. и с 1976 по 1985 г. (так что отброшены г = 6 центральных наблюдений). При раздельном подборе линейных моделей по этим группам наблюдений получаем остаточные суммы квадратов RSSX = 208.68 и RSS2 = 1299.66 соответственно, так что наблюдаемое значение F-статистики критерия Голдфелда — Квандта равно: ^ = !^ = 6.228. RSSl 208.68
Если стандартные предположения о случайных ошибках в модели наблюдений выполнены, то тогда отношение указанных остаточных сумм квадратов как случайных величин имеет F-распределение Фишера
26 6 26 6 ^
3, 3 = F(7,7). Если, как обычно, зададим уровень значи,2 '2
мости а = 0.05, то соответствующее этому уровню значимости критическое значение F-статистики равно F0 95 (7, 7) = 3.79.
Наблюдаемое значение этой статистики 6.228 превышает критическое, поэтому гипотеза о выполнении стандартных предположений об ошибках отклоняется в пользу гипотезы о возрастании дисперсий D(st) с ростом значений вх + 02DPI + QASSETS. Заметим, наконец, что вероятность превышения случайной величиной с распределением F(7, 7) значения 6.228 (Р-значение) равна 0.0138.
Сравним результаты применения критерия Голдфелда — Квандта с результатами, полученными при использовании двух вариантов критерия Уайта.
Для первого варианта наблюдаемое значение статистики критерия равно nR2 = 8.884. Поскольку /7 = 3, число степеней свободы соответствующего распределения хи-квадрат равно 2р 2 = 4. Вероятность того, что случайная величина, имеющая такое распределение, превысит значение 8.884, равна 0.0641, так что значение nR2 = 8.884 меньше критического, а значит, гипотеза об однородности дисперсий этим вариантом критерия Уайта не отвергается.
При использовании второго варианта наблюдаемое значение статистики критерия равно nR2 = 9.699. Число степеней свободы соответствующего раср2+р-2
пределения хи-квадрат равно ——^ = 5. Вероятность того, что случайная
величина, имеющая такое распределение, превысит 9.699, равна 0.0842, так что значение nR2 = 9.699 меньше критического, а значит, гипотеза об однородности дисперсий не отвергается и этим вариантом критерия Уайта.
Таким образом, статистические выводы относительно однородности дисперсий случайных составляющих в рассматриваемой модели наблюдений оказались противоречивыми: гипотеза об однородности дисперсий отвергается критерием Голдфелда — Квандта, но не отвергается обоими вариантами критерия Уайта. Как можно объяснить такое противоречие?
Оба варианта критерия Уайта асимптотические, тогда как критерий Голдфелда — Квандта учитывает реально имеющееся количество наблюдений.
Оба варианта критерия Уайта являются критериями согласия, не настроенными на какой-то специфический класс альтернатив гипотезе об однородности дисперсий, тогда как использование критерия Голдфелда — Квандта непосредственно связано с альтернативой, выраженной в форме возрастания дисперсий ошибок для соответствующего упорядочения наблюдений. И здесь проявляется общее положение: критерии, построенные с расчетом на некоторый узкий класс альтернатив, оказываются более мощными в отношении этих альтернатив по сравнению с критериями, рассчитанными на более широкий класс альтернатив (т.е. они чаще отвергают нулевую гипотезу, когда верна не она, а гипотеза из указанного узкого класса альтернатив).
et
Рассмотрим график зависимости стандартизованных остатков ct = — от
S
 номера наблюдений (рис. 4.22) и его вариант в виде зависимости от года наблюдения (рис. 4.23).
номера наблюдений (рис. 4.22) и его вариант в виде зависимости от года наблюдения (рис. 4.23).
В данном случае обращает на себя внимание наличие серий остатков одинакового знака, что сигнализирует о том, что ошибки в модели наблюдений, скорее всего, имеют положительную автокорреляцию. Для 26 наблюдений и р = 3 объясняющих переменных границы для критического значения статистики Дарбина — Уотсона при а 0.05 (односторонний критерий) равны:
^l,o.o5 = 1-22, dU 0 05 = 1.55.
В то же время вычисленное по остаткам от оцененной модели значение статистики Дарбина — Уотсона равно DW 1.01, что меньше нижней границы = 1-22. Следовательно, нулевая гипотеза о выполнении стандартных предположений отклоняется в пользу гипотезы о положительной автокоррелированности ошибок.
Сравним результаты применения критерия Дарбина — Уотсона с полученными при использовании критерия Бройша — Годфри.
Если исходить из допущения зависимости очищенных случайных ошибок только на один шаг (К= 1), как это делается при использовании критерия
 Дарбина — Уотсона, то в этом случае вычисленное значение статистики критерия Бройша — Годфри равно nR2 = 6.068, что соответствует Р-значе-нию, равному 0.014. Гипотеза независимости ошибок отвергается, что согласуется с результатом, полученным при использовании критерия Дарбина — Уотсона.
Дарбина — Уотсона, то в этом случае вычисленное значение статистики критерия Бройша — Годфри равно nR2 = 6.068, что соответствует Р-значе-нию, равному 0.014. Гипотеза независимости ошибок отвергается, что согласуется с результатом, полученным при использовании критерия Дарбина — Уотсона.
В то же время если взять К = 5, то nR2 = 10.331, что соответствует Р-зна-чению, равному 0.066. Гипотеза о независимости ошибок в этом случае не отвергается при установленном уровне значимости а = 0.05, что расходится с результатом, полученным при использовании критерия Дарбина — Уотсона. Эта гипотеза не отвергается также при выборе К = 6 (nR2 = 0.095), К = 7 (nR2 = 0.127) и т.д. Это вполне объяснимо: выбор К=5,К=6,К=7 соответствует выбору все более широкого
 класса альтернатив по сравнению с К = 1, что приводит к уменьшению вероятности отвергнуть гипотезу независимости ошибок в случае, когда она неверна.
класса альтернатив по сравнению с К = 1, что приводит к уменьшению вероятности отвергнуть гипотезу независимости ошибок в случае, когда она неверна.
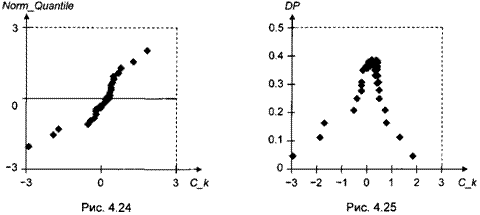
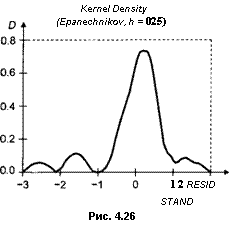
Проверим, наконец, предположение о нормальном распределении ошибок. Для этого сначала рассмотрим диаграмму «квантиль-квантиль» (Q-Q plot) (рис. 4.24), диаграмму плотности (DP-plot) (рис. 4.25) и ядерную оценку плотности (рис. 4.26).
Первая диаграмма не выглядит удовлетворительной, вторая обнаруживает определенную асимметрию, как и ядерная оценка плотности. Выборочный коэффициент асимметрии здесь равен -1.285, выборочный куртозис
 |
Они говорят о нарушении предположения
E(st) = 0, f = l,...,W.
Что касается критерия Чоу, сравнивающего прогнозные значения (Chow Forecast Test), полагая в нем л0 = 13, получим значение F-статистики F = 11.037, что соответствует Р-значению 0.0003 и говорит о нестабильности модели.
Итак, обнаружили, что модель линейной связи
CONSt =вх+ 62DPIt + въ ASSETS, +єп Г = 1 26,
оказалась неудовлетворительной, поскольку анализ остатков от оцененной модели выявил гетероскедастичность и автокоррелированность ошибок, отличие распределения ошибок от нормального, нарушение условия E(st) = 0, t = 1,п, и нестабильность модели.
График зависимости стандартизованных остатков ct = — от номера наS
блюдений и его вариант в виде зависимости от года наблюдения указывают на заметную разницу в поведении остатков в первой части периода наблюдений (до 1972 г.) и во второй его части (1973—1985 гг.). Такое различие в поведении остатков объясняется тем, что в 1973 г. произошел структурный сдвиг в экономике, связанный с мировым топливно-энергетическим кризисом, который изменил характер связи между рассматриваемыми макроэкономическими факторами. Последнее могло, например, выразиться в изменении значений параметров вх, в2, въ при переходе ко второй части периода наблюдений. Возможность такого изменения учитывает расширенная модель
CONS, = yx(D\ + y2(D2), + y3(DPI), + yA(DPI2), +
+y5(ASSETS),+y6(ASSETS2),+s„ г = 1 26,
где (Dl), — фиктивная переменная, равная 1 для t = 1, 13 (что соответствует периоду с 1960 по 1972 г.) и равная 0 для t = 14, 26 (что соответствует периоду с 1973 по 1985 г.);
(D2)t = 1 (D)t — фиктивная переменная, равная 0 для t = 1,13 и равная 1 для t = 14,26;
{DPI)t = DPI, • (Dl), — переменная, равная (DPI), для t = 1, 13 и равная 0 для t14,26;
{DPI2)t = DPI, • (D2), — переменная, равная 0 для t = 1, 13 и равная (DPI), дляґ=14,26;
(ASSETSl), = ASSETS, • (Dl), — переменная, равная ASSETS, для t = 1,13 и равная 0 для t = 14,26;
(ASSETS!), = ASSETS, • (D2), — переменная, равная 0 для t = 1, 13 и равная ASSETS, для t = 14,26.
Заметим, что при этом
(DPIX), + (DPI 2), = DPI,, t = ,...,26, (ASSETSl)t + (ASSETS!)t = ASSETS,, t = 1,..., 26. В рамках расширенной модели проверим гипотезу
Н0:у,=У2, Уз=Га> Г5=ГбЭто линейная гипотеза с q = 3 линейными ограничениями, которые можно записать в виде
яо: У~Уг=Ъ, Гз-у4=0, у5-у6=0.
Будем проверять эту гипотезу, используя F-критерий. В такой постановке F-критерий известен как критерий Чоу на структурный сдвиг (Chow breakpoint test). Значению і^-статистики 10.490 соответствует Р-значение 0.0002, так что гипотеза Н0 отвергается, и это говорит об изменении хотя бы одного из параметров вх, в2, въ при переходе ко второй части периода наблюдений. Поскольку оценки параметров у5 и у6 статистически незначимы (им соответствуют Р-значения 0.1157 и 0.5599), проверим линейную гипотезу о равенстве нулю обоих этих параметров (q = 2), используя F-критерий. Получаемое Р-значение 0.2412 свидетельствует о том, что последняя гипотеза не отвергается, так что, допуская изменение параметров модели при переходе ко второй части периода наблюдений, можно вообще отказаться от включения в модель переменной ASSETS и ограничиться моделью
CONS,=yx(D),+y2(D2),+y,(DPI),+y4(DPI2),+s„ ґ = 1 26.
Оценивание этой модели дает следующие результаты: R2 = 0.9992, ух = 58.786, Р-значение = 0.0119; у2 = -234.836, Р-значение = 0.0000; у3 = 0.864, Р-значение = 0.0000; Я = 1.012, Р-значение = 0.0000.
Гипотеза Я0 : у3 = у4 (q 1) здесь отвергается (Р-значение = 0.0000), как и гипотеза #0 : ух = у2, так что структурный сдвиг затрагивает и постоянную, и коэффициент при DPI.
Значение статистики Дарбина — Уотсона равно DW 2.06 и не выявляет автокоррелированности ошибок. К тому же результату приводит и применение критерия Бройша — Годфри с Я" = 1, К = 2, К = 3. Критерий Уайта дает Р-значение = 0.508, не выявляя гетероскедастичности, а критерий Харке — Бера дает Р-значение = 0.469, не выявляя существенных отклонений распределения ошибок от нормального.
Вспомним, однако, про критерий Голдфелда — Квандта. Опять выделив периоды с 1960 по 1969 г. и с 1976 по 1985 г., получим значение F-статистики 3.354, соответствующее Р-значению = 0.0832, так что на сей раз и этот критерий не обнаруживает существенной гетероскедастичности.
 |
В данном случае не обнаруживается и нарушения предположения
= 0, t = ,...,n.
В связи с этим есть основания принять в качестве возможной модели наблюдений, объясняющей изменение объема совокупного потребления на периоде с 1960 по 1985 г., оцененную модель
CONS, = 58.786(D1), 234.836(£>2), +
+ 0.864(DP/1), +1.012(£>/72), +є,, / = 1,..., 26.
Эту модель можно также записать в виде
Г58.786 + 0.m(DPI). +є,, t = 1,..., 13
CONS. = ' '
' [-234.836 + 1.012(^7),+^, / = 14,...,26.
Исходя из последней формы записи такая модель называется двухфазной линейной регрессией (two-phase linear regression model) или линейной моделью с переключением (switching regression model). Заметим, наконец, что, допустив возможность изменения постоянной и коэффициента при DPI при переходе ко второй части периода наблюдений, можно допустить при этом и изменение дисперсии ошибок, т.е. полагать, что D(st) = а для t 1, 13 и D(st) = <j для t = 14, 26. Оценки для ах и <т2 в этом случае равны соответственно 8.887 и 14.886.
Замечание 4.2.3. Следуя идеологии «тест, тест, тест», останавливаемся на модели, которая успешно проходит целый ряд тестов, проверяющих гипотезу о выполнении всех стандартных предположений и направленных на выявление специфических нарушений основных предположений. Между тем при таком подходе возникает проблема, связанная с потерей контроля над уровнем значимости используемой процедуры.
Предположим, что для проверки нулевой гипотезы (в данном случае — гипотезы о выполнении всех стандартных предположений) используются К тестов (статистических критериев), основанных на К различных статистиках ТІ9 Г2, Тк и имеющих критические множества Rl9RK9 соответствующие одинаковому для всех к уровню значимости а, так что Р{ТК є RK) = а9 k1, К. Обычно при использовании совокупности К тестов нулевая гипотеза отвергается, если ТК є RK хотя бы для одного к9 к = 1, К. При использовании такого правила результирующая ошибка 1-го рода а*9 т.е. вероятность отвергнуть в итоге нулевую гипотезу, когда она верна, не совпадает с уровнем значимости а каждого отдельного критерия. Значение а* больше, чем а9 но его невозможно вычислить, если неизвестно совместное распределение вероятностей указанных К статистик. В связи с этим возникает необходимость в получении верхней границы для а*. Наиболее простым способом является использование для этой цели неравенства Бонферрони:
а* = Р{ТК е RK хотя бы для одного k9k= 1,К} < <^Р{ТкеЯк} = Ка.
к=
Отсюда вытекает, что если мы хотим обеспечить для процедуры в целом уровень значимости а9 то для каждого отдельного критерия достаточно взять уровень значимости а/К. При этом результирующая ошибка 1-го рода не превысит а. Такая процедура весьма проста, но в случае сильной коррелированности статистик Tl9 Т29 ТК реальная ошибка 1-го рода этой процедуры может оказаться существенно меньше заявленного уровня значимости а. Исследование этого вопроса проведено в работе (Godfrey, 2005).
Замечание 4.2.4. Вообще говоря, при построении моделей регрессии для переменных, значения которых развернуты во времени, т.е. являются временными рядами, возникает целый ряд проблем, которые рассматриваются в соответствующем разделе эконометрики — анализе временных рядов (time series analysis). Эти проблемы будут изучены во второй части данного учебника.
КОНТРОЛЬНЫЕ ВОПРОСЫ
Какие статистические критерии используются для выявления гетероскедастично-сти? Чем принципиально различаются критерии Голдфелда — Квандта и Уайта?
Какие критерии используются для выявления автокоррелированности ошибок? Чем принципиально различаются критерии Дарбина — Уотсона и Бройша — Годфри?
Какие критерии используются для выявления нарушения предположения о нормальном распределении ошибок?
Какие критерии используются для выявления неправильной спецификации модели (неправильная функциональная форма, нестабильность коэффициентов модели)?

Обсуждение Эконометрика Книга первая Часть 1
Комментарии, рецензии и отзывы