Раздел 4 модели с дискретными и ограниченными объясняемыми переменными тема 4.1 модели, в которых объясняемая переменная принимает только два различных значения
Раздел 4 модели с дискретными и ограниченными объясняемыми переменными тема 4.1 модели, в которых объясняемая переменная принимает только два различных значения
Ситуации, когда в модели объясняемая переменная принимает только два различных значения, возникают при исследовании влияния тех или иных субъективных и объективных факторов на наличие или отсутствие некоторого признака у отдельных домашних хозяйств (наличие или отсутствие в семье автомобиля), у отдельных индивидуумов (занятый — безработный), у отдельных фирм (обанкротилась или нет в течение определенного периода) и т.п. Если исследование затрагивает п субъектов, т.е. если имеем п наблюдений, то факт наличия или отсутствия такого признака в і-м наблюдении удобно индексировать числами 1 (наличие признака) и 0 (отсутствие признака). Тем самым определяется индикаторная (дихотомическая, бинарная — indicator, dichotomic, binary variable) переменная у, которая принимает в /-м наблюдении значение^. При этом^ = 1 при наличии рассматриваемого признака у /-го субъекта и у1, = О — при отсутствии рассматриваемого признака у /-го субъекта.
Если пытаться объяснить наличие или отсутствие рассматриваемого признака значениями (точнее, сочетанием значений) некоторых факторов (объясняющих переменных), то, следуя идеологии классической линейной модели, можно рассмотреть модель наблюдений
У і = вХі +••* + врХір + 1 = І Л,
где хп, хір — значенияр объясняющих переменных в /*-м наблюдении; вх, вр — неизвестные параметры;
єІ9...9є„ —случайные ошибки, отражающие влияние на наличие или отсутствие рассматриваемого признака у /-го субъекта каких-то неучтенных дополнительных факторов.
Однако попытка оценить такую модель методом наименьших квадратов наталкивается на определенные трудности.
При обычном предположении E(Sj Xj) = О, і = 1, ..., п получаем
Е(уіхі) = Є1хІІ+-. + врхір=х]в9
где в=(вІ9 Opf—вектор-столбец (неизвестных) коэффициентов (верхний индекс Т указывает на транспонирование вектора или матрицы);
xj = (xil9 xip) — вектор-строка (известных) значений объясняющих переменных в /-м наблюдении.
В то же время, поскольку у; — случайная величина, принимающая только два значения — 0 и 1, ее условное математическое ожидание (при заданном значении jc.) равно:
Е(у х,) = 1 • P{yt = 1| х,} + 0 • Р{у, = 0| х,.} = Р{у. = 1| х;}. Таким образом,
в1хя++ врхІр=Р{уі=\хі},
т.е. вххп + ... + врхір — вероятность, а значит, должно выполняться соотношение
0<віХп+-. + врхір<9
Это первая из трудностей, с которыми сталкиваемся при обращении к таким моделям.
Далее, при у-г = 1 получаем е{-х] в9 а при у( = 0 имеем є{ = -xf в9 так что (при фиксированном xz) et может принимать в /-м наблюдении только два значения. Тогда (условные) вероятности этих значений равны:
Р{єі=-хі;вхі} = Р{уі=\хі} = х]в,
P{£i = -xj0X,} = Р{у, = 0| = 1 х]в,
Соответственно случайная величина f, имеет условное математическое ожидание:
Е{є х,.) = (1 -хІв)Р{є, -1 -х]вX,} + (-xfв)Р{є, = -х]вxj = = (1 х,г^)х,^ х]в{ х]в) = 0
и условную дисперсию:
D(e х,) = E(sf х.) {Е(є xt)f = Е(є?x,) = = (1 xT в)2 х]в + (-xjff)2 (1 x] в) = = xf0(l xfe)[xje + (1 хТв)] = xf в (Ixj в).
Таким образом, здесь возникает также проблема гетероскедастичности, осложненная еще и тем, что в выражения для дисперсий et входит и (неизвестный) вектор параметров в.
Предположим, что у і индексирует наличие или отсутствие собственного автомобиля у /-й семьи, a xt — средний ежемесячный доход, приходящийся на каждого члена этой семьи (в условных единицах). Естественно предполагать, что вероятность наличия автомобиля увеличивается с ростом х,. Если использовать линейную модель
yi =a + j3xi +єі9 / = 1,...,и,
то
E(ytxl) = P{yl=lxl} = a + 0xl.
Таким образом, если значение jcz увеличить на 1, вероятность наличия автомобиля увеличится на величину, равную
(а + Д(х/+1))-(а + Дх/) = Д
независимо от того, сколь большим или малым является среднедушевой доход xt.
Между тем такое положение вряд ли можно считать оправданным. Скорее, можно предположить, что для семей с малыми доходами наличие автомобиля — большая редкость, и некоторое увеличение среднедушевого дохода лишь ненамного увеличит вероятность приобретения автомобиля такой семьей. Для семей с весьма высокими доходами возрастание вероятности наличия автомобиля также не может быть существенным, поскольку такие семьи, как правило, уже имеют автомобиль. Большее влияние увеличения дохода на возрастание вероятности наличия автомобиля должно наблюдаться для семей со средними доходами, т.е. в «переходной зоне» от доходов, еще не позволяющих обзавестись собственным автомобилем, к доходам, уже обеспечившим возможность приобретения собственного автомобиля.
Возьмем прямоугольную систему координат, в которой по оси абсцисс будем откладывать размеры среднедушевых семейных доходов. Пусть
х(1) =min{x1,...,xw}, х(п) = max {*!,...,*„},
так что х(1) < х < x(w) — интервал значений среднедушевых доходов рассматриваемых семей. Разобьем этот интервал на некоторое количество т подынтервалов одинаковой длины / = —^ —. Над каждым таким подынтервалом
т
построим прямоугольник, нижнее основание которого совпадает с этим подынтервалом. Пусть в пределыу'-го подынтервала (/ = 1, т) попадают среднедушевые доходы rij семей, и при этом лишь у rij ! из этих семей имеется автомобиль. (Для определенности значения х/5 лежащие на границе двух соседних подынтервалов, будем относить к подынтервалу, расположенному левее.) Тогда высоту прямоугольника, построенного наду-м подынтервалом, положим равной
При этом предполагаем, что общее количество рассматриваемых семей п достаточно велико, так что можно взять не слишком малое количество подынтервалов т и при этом все еще иметь достаточное количество значений xzв каждом подынтервале.
Построим теперь ломаную с концами в точках (х(1), 0) и (x(w), 1), узлы которой совпадают с серединами верхних сторон построенных прямоугольников. Эта ломаная является графиком некоторой кусочно-линейной функции Gn(x).
И если Р{у. = 1 |xzг = х} G(x), то функция Gw(x) в какой-то мере «оценивает» функцию G(x). Правда, если функцию G(x) естественно считать неубывающей (возрастающей) по х, то в силу случайных причин функция G„(x) вполне может иметь и участки убывания. Тем не менее при большом количестве наблюдений и достаточном количестве подынтервалов график функции Gn(x) отражает в общих чертах форму «истинной» функции G(x), так что по поведению функции G„(x) можно судить о совместимости или о несовместимости линейной модели с данными наблюдений.
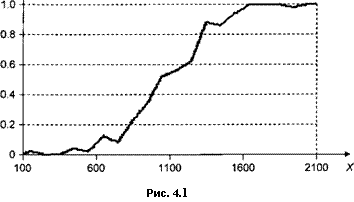
Рассмотрим (искусственно смоделированную) выборку, состоящую из 1000 семей со среднедушевыми месячными доходами от 100 до 2100 условных единиц, среди которых 510 семей имеют собственный автомобиль.
Построенная по этим данным ломаная (график функции Gn(x)) (рис. 4.1) указывает на то, что «истинная» функция G(x) имеет, скорее, не линейную, а ^-образную форму.
Если тем не менее исходить из линейной модели наблюдений, то метод наименьших квадратов дает для параметров такой модели следующие оценки: а = -0.237628, /? = 0.000680, так что условная вероятность P{yi = 1 |xz} оценивается как
Р{у. = l| = -0.237628 + 0.000680xz..
При xz < 349 правая часть принимает отрицательные значения, а при х/ > 1821 — значения, превышающие 1, что выходит за пределы интервала возможных значений вероятности.
 |
Если использовать функцию нормального распределения N(/u, <т2), имеющего математическое ожидание /л и дисперсию <т2, то
1
G(x) =
}exp-fe^^z.
2ol
Замена переменной -—— = t приводит это соотношение к виду:
1 (*-М)/° 2/
уі27г
G(jc) = ^= j е~і,2Л = Ф
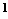 ГДЄ O(z) :
ГДЄ O(z) :
-Ґ/2
I— Je ' "dt — функция стандартного нормального распредел/2/г ления N(0, 1), математическое ожидание кото-
рого равно 0, а дисперсия равна 1.
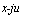 Соотношение G(jc) = 0
Соотношение G(jc) = 0
можно записать также в виде:
о)
G(x) = 0(a + fix),
где а = -—, р= — . а о
Таким образом, используя для аппроксимации G(x) функцию нормального распределения, приходим к модели
yt = Ф(а+ + / =
Оценив параметры а и Р этой модели, получим также оценки параметров функции нормального распределения, аппроксимирующего функцию G(x):
а Л 1 Р Р
Проблема, однако, в том, каким образом производить оценивание.
Заметим, что функция G(x) = Ф(а + Рх) нелинейна по параметрам, так что здесь имеем дело с нелинейной моделью регрессии. Следуя принципу наименьших квадратов, для получения оценок а и J3 надо минимизировать по а и р сумму квадратов
^/о=Еи--ф(«+м))2.
Однако, в отличие от линейной модели, здесь нормальные уравнения нелинейны, не имеют решения в явном виде, и для получения приближенных
значений оценок а и Р приходится использовать итерационные процедуры. Как и в рассмотренном ранее случае линейной модели, здесь возникает также проблема гетероскедастичности: условные дисперсии ошибок равны:
D(e, х.) = Ф(а + fix, )(1 Ф(а + fix,)).
Соответственно для учета различия этих дисперсий при разных / следует использовать взвешенный метод наименьших квадратов, т.е. минимизировать по а и Р сумму квадратов
Q{a,fi) = fjwi{yi-<b{a + fixi))2,
1=1
где веса wt определяются соотношением D(^.|xz.)
К сожалению, эти веса зависят не только от xi9 но и от значений параметров а и Д которые нам не известны и которые как раз и подлежат оцениванию. Поэтому для реализации итерационной процедуры оценивания необходимы некоторые начальные оценки_весов >v?, / = 1, а для этого, в свою
очередь, необходимы начальные оценки значений G, = G(xz) = Ф(а + /?хг), которые дали бы оценки весов в виде
wf=[Gf(l-Gf)r.
Поскольку у нас yt 0 или у= 1, то единственная разумная возможность — положить G? = 1, если у. = 1, и G? = 0, если yi = 0. Однако в обоих случаях вес wf не определен (знаменатель равен нулю).
Ввиду отмеченных выше трудностей применения метода наименьших квадратов к рассмотренным моделям используем альтернативный метод оценивания, широко распространенный в прикладных исследованиях, а именно — метод максимального правдоподобия.
Однако, прежде чем перейти к этому методу, следует заметить, что в качестве объясняющих факторов в моделях рассмотренного типа могут выступать несколько переменных, и тогда получим модель вида:
y,=G(elxn+ — + epxip) + ei9 / = 1,...,и, которую обычно называют моделью бинарного выбора (binary choice model).
Использование метода максимального правдоподобия для оценивания моделей бинарного выбора
Итак, пусть наша задача состоит в оценивании параметров модели бинарного выбора:
yi = G(exxn + ••• + врхір) + єі9 і = 1,/і,
где G(z)— S-образная функция распределения, имеющего плотность g(z) = G'(z).
В соответствии с введенными выше обозначениями вххп + ... + врхір = х[в9 так что G(dxxtX + ... + врхір) = G(xj0). Предположим, что при фиксированных значениях объясняющих переменных в п наблюдениях, что соответствует фиксированным значениям векторов xi9 случайные ошибки єХ9 еп статистически независимы и Е(е{х{) О, так что P{yt = 1|х,} = Е(у(х{) = G(x[0). Тогда при фиксированных xt статистически независимы и случайные величины G(OxxtX + ... + врхір) + єі9 і = 1, п9 т.е. статистически независимы yl9 yn. В силу этого (условная при фиксированных хі9 і = 1, п) совместная вероятность получения конкретного набора наблюдений уХ9 уп (конкретного набора нулей и единиц) равна произведению:
П№ =1|*<})Л№ =0|дс,})1"Л =fl(.G(x!0)y<(l-G(xl0))l-».
і= /=1
Правая часть этого выражения при фиксированных хі9 і = 1, п является функцией от вектора неизвестных параметров в:
Цв) = Цвхи...,х„) = \{0{х]в)Г (1 GtfO))1-"
/=1
и интерпретируется как функция правдоподобия параметров вХ9 вр. При различных наборах значений 9Х9 вр получаются различные L(6)9 т.е. при фиксированных хі9 і = 1, п9 вероятность наблюдать конкретный набор зна
чений ух, уп может быть более высокой или более низкой в зависимости от значения в. Метод максимального правдоподобия предлагает в качестве
оценки вектора параметров в использовать значение в = в, максимизирующее функцию правдоподобия, так что
Цв) = max 1(0) = maxfl(G(xJe))yi (1 G(xj0))l'yi.
9 9 /=і
Опираясь на свойство монотонного возрастания функции ln(z), то же значение в можно найти, максимизируя логарифмическую функцию правдоподобия L(Q). В нашем случае
ЫЦв) = X У і In С(х]в) + 2(1 Л)1п(1 С(х]в)).
Не будем углубляться в технические детали соответствующих процедур максимизации — такие процедуры «встроены» во многие прикладные пакеты статистических программ для персональных компьютеров, и читатель при необходимости может ими воспользоваться. Заметим только: если не имеет место чистая мультиколлинеарность объясняющих переменных (т.е. если матрица Х (xtj) значенийр объясняющих переменных в п наблюдениях имеет ранг р, так что ее столбцы линейно независимы), то функция Ь(в) имеет единственный локальный максимум, являющийся и глобальным максимумом, что гарантирует сходимость соответствующих итерационных процедур к оценке максимального правдоподобия.
Рассмотрим результаты применения метода максимального правдоподобия для оценивания параметров а и /? моделей
yt =G(a + 0xi) + ei, / = 1,...,и,
по упомянутым выше смоделированным данным. При этом используем предусмотренную в пакете Econometric Views (Е Views) возможность выбора в качестве G(z) следующих функций:
dt
Ф(2) =
функция стандартного нормального распределения N(0, 1) (пробит-модель — probit model);
l + ez
G(z) = l-Qxp(-ez) —
функция стандартного логистического распределения (логит-модель — logit model);
функция стандартного распределения экстремальных значений (минимума) I типа (распределение Гомпертца, гомпит-модель — gompit model).
Заметим, что функции плотности первых двух распределений являются четными (графики этих плотностей симметричны относительно оси ординат),
 |
Оценка моделей по смоделированным данным (1000 наблюдений)
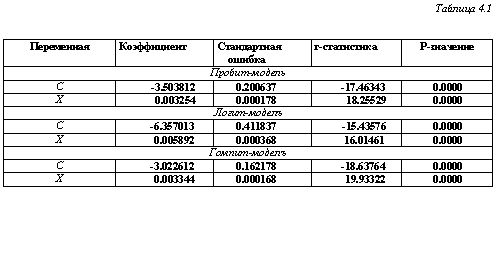 Результаты оценивания указанных трех моделей по смоделированным данным (1000 наблюдений) с использованием пакета EViews приведены в табл. 4.1
Результаты оценивания указанных трех моделей по смоделированным данным (1000 наблюдений) с использованием пакета EViews приведены в табл. 4.1
Полученные значения оценок параметров а и J3 в первой модели (а = -3.503812,
1 В четвертой графе приведены значения отношений оценок коэффициентов к стандартным ошибкам, рассчитанным по асимптотическому нормальному распределению оценок максимального правдоподобия. В связи с этим здесь и в последующих таблицах указанное отношение называется не f-статистикой, а z-статистикой. Р-значения, приводимые в пятой графе, соответствуют стандартному нормальному распределению.
р = 0.003254) соответствуют оценкам /и = 1076.77 и <т= 307.31 параметров функции нормального распределения, сглаживающей построенную ранее
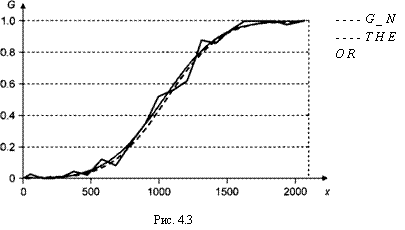 |
функцию Gn(x\% график которой представляет собой ломаную. Заметим, что в действительности при моделировании данных использовалась в качестве G(x) функция нормального распределения с параметрами /л = 1100 и а = 300. Рисунок 4.3 позволяет сравнить поведение:
кусочно-линейной функции Gn(x);
теоретической функции G(x), соответствующей нормальному распределению^! 100, 3002);
оцененной функции соответствующей нормальному распределению #(1076.77, 307.312).
 |
Показатели качества модели, критерии согласия, сравнение альтернативных моделей
Прежде всего обратим внимание на следующее обстоятельство. Пусть методом наименьших квадратов оценивается обычная линейная модель
у. = вх хп + • • • + вр xip + є t, і = 1 л,
с хп = 1 (модель с константой), в которой объясняемая переменная у может принимать непрерывный ряд значений. В таком случае простейшим показателем качества оцененной модели является коэффициент детерминации R2:
/ = 1
ГДЄ у, = вхХп + ... + врХір, у = У1+-'+ У« ;
п
TSS — «полная» сумма квадратов; RSS — «остаточная» сумма квадратов.
Если оценивать тривиальную модель, в правую часть которой включается единственная объясняющая переменная xn = 1, т.е. модель
Уі =&і +£і9 і = 1,..., л,
то для такой модели вх =у, у( = вх -у, так что RSS = 0 и R2 = 0. При добавлении в правую часть модели дополнительных объясняющих переменных коэффициент R2 возрастает, и этот коэффициент будет тем больше, чем более выраженной является линейная связь объясняемой переменной с совокупностью объясняющих переменных, включенных в правую часть. Своего максимального значения (R2 = 1) коэффициент детерминации достигает в предельном случае, когда для всех / = 1,п выполняются точные соотношения
Поскольку теперь имеем дело с нелинейными моделями у{ = G(6xxiX +••• + 6pxip) + і = 1,..., л,
не можем пользоваться обычным коэффициентом детерминации R2. В этом случае желательно определить какую-то другую меру качества подобранной модели.
Одна из имеющихся возможностей в этом отношении — сравнение количеств неправильных предсказаний, получаемых по выбранной модели и по модели, в которой в качестве единственной объясняющей переменной выступает константа (тривиальная модель).
Естественным представляется при G(xj6) > l/i предсказывать значение
yt1. Для симметричных распределений это равносильно условию х[в > О, так что прогнозные значения равны:
А _ J1, если х]в>0, Уі (О, еслих/#<0.
Количество неправильных предсказаний по выбранной модели равно:
п
= Ї1Уі-Уі = Ї1(Уі-Уі)2^
wrong, 1
1=1 /=1
доля неправильных предсказаний по выбранной модели равна:
wrong, 1
В то же время, если рассмотреть тривиальную модель, то для нее значение у і = 1 предсказывается для всех і = 1, п, когда G(0X) > 1/2, т.е. когда у > у 2 (значения у{ = 1 наблюдаются более чем в половине наблюдений). Соответственно значение^ = 0 предсказывается для всех і = 1, п, когда G(6{) < у2, т.е. когда у < ХІ2 (значения yt = 1 наблюдаются не более чем в половине наблюдений). При этом доля неправильных предсказаний по тривиальной модели равна:
{1-у, если у>1/2, *Wo=j - если -<1/2
За показатель качества модели можно было бы взять коэффициент
2>,-л)2
г) 2 _ -, v wrong, 1 _ ч #=1
К predict 1 ~ 1
^ wrong, 0 ^wrong, О
Проблема, однако, в том, что выбранная модель может дать предсказание хуже, чем тривиальная, так что vwrongX > vwrong0, и тогда R2predict < 0. Отметим также, что вообще vwrong0 < 0.5, так что тривиальная модель может неправильно предсказать не более половины наблюдений. А если оказывается, что в выборке значения у{ равны 1 для 90\% наблюдений, тогда vwrong0 = 0.1, и, чтобы получить R2predict > 0, необходимо, чтобы альтернативная модель давала более 90\% правильных предсказаний. Это означает, что большая доля правильных предсказаний 1 vwmngt х сама по себе не говорит еще о качестве модели. Эта доля может быть большой и для плохой модели.
Рассмотрим теперь альтернативный подход к построению аналога коэффициента R2 для моделей бинарного выбора. Поскольку для оценивания таких моделей мы использовали метод максимального правдоподобия, то естественным представляется сравнение максимумов функций правдоподобия (или максимумов логарифмических функций правдоподобия) для выбранной и тривиальной моделей.
Пусть Ьх — максимум функции правдоподобия для выбранной модели, a L0 — максимум функции правдоподобия для тривиальной модели. Заметим, что при этом L0 < Lx < 1, так что и 1пЬ0 < ЫЬХ < 0. В рамках этого подхода среди множества других были предложены следующие показатели качества моделей бинарного выбора:
pseudoR2 = 1 ——у—г~ТТ'
х | 2( Lx-lnL0)
п
McFaddenR2 =1-^^.
lnL0
Последний показатель часто обозначают как LRI — индекс отношения правдоподобий (likelihood ratio index).
Оба показателя изменяются в пределах от 0 до 1. Если для выбранной модели вх = ... = вр = 0, то L0 = Lx, и оба показателя равны 0. Второй показатель
может оказаться равным 1, если Lx = 0, т.е. Lx = I. Такая модель дает точное
предсказание, так чтоу( =yt для всех і = 1, Но при этом для рассмотренных выше моделей (пробит, логит и гомпит) оказывается невозможным доведение до конца итерационной процедуры оценивания вектора параметров в из-за взрывного возрастания абсолютной величины х[в в процессе итераций. Это связано с тем, что у таких моделей при конечных значениях xjO выполняются строгие неравенства 0 < G(xf6) < 1, поэтому функция правдоподобия не может достигать значения 1.
ПРИМЕР 4.1.1
Продолжая начатый выше статистический анализ смоделированного множества данных, вычислим значения альтернативных вариантов коэффициента R2 для трех оцененных моделей бинарного выбора. Величины, необходимые для вычисления этих значений, приведены в табл. 4.2. (Напомним: в смоделирован
 |
ной выборке количество семей, имеющих собственный автомобиль, равно 510, что составляет более половины семей. Поэтому тривиальная модель дает для всех 1000 наблюдений прогнозу = 1, что приводит к 49\% ошибок.)
Соответственно для различных вариантов коэффициента R2 получаем: пробит-модель
Rledic, =1--^22LL = 1-— = 0.745, Wo °-490
pSeUd°Rl =1" 1|2(lnL,-lnL0) = 1" x ^(-275.7686 + 692.94727 = °'4548'
+ n + 1000
McFaddenR2 =i_J£A =1_-275.7686 = lnl0 -692.9472
логит-модель
Кгешс, = 1 = 1-H2£ = 0.7470,
Wo °-490
pseudoR2 = 1 ——г—;—7-r = 1 .—тх^ітт^г = 0.4550,
y t | 2(1пД -lnL0) 1 | 2(-275.4592 +692.9472)
+ « + 1000
..r.jj „г , InL, , -275.4592
McFaddenR2 = 1 L = 1 = 0.6025;
InZ-o -692.9472
гомпит-модель
Кгелс, = 1-^^ = 1—= 0.7531, W.o °-490
2 '1 1
pseudoR =1- 2(111/4-InL0) =1~t ( 2(-292.6808 + 692.9472) =
+ n + 1000
гж r.2 Л In А і -275.4592
McFaddenR1 = 1 != 1 = 0.5776.
lnL0 -692.9472
 |
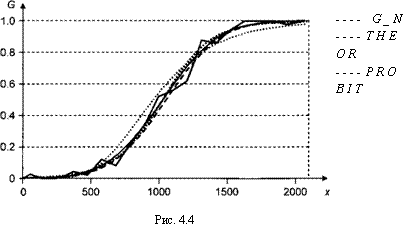
Отметим близость всех вариантов коэффициента R2 для пробити логит-моделей. Гомпит-модель дает несколько лучшее предсказание, в то время как логит-модель несколько лучше двух других с точки зрения коэффициентов pseudoR2 и McFaddenR2.
Представим теперь, что в нашем примере вместо смоделированных значений^, наблюдались бы следующие значения:
Уі = 0 для Xj < 1100, Уі = 1 для xt > 1100.
Тогда 100\%-е точное предсказание этих значений дала бы модель
ГО, если х < 1100, Р{у =1} = } ^' [1, если х;> 1100.
Вместе с тем в рамках пробит-, логити гомпит-моделей оценки максимального правдоподобия в такой ситуации не определены, так как максимум функции правдоподобия не достигается при конечных значениях параметров. ■
Как и в случае обычных линейных моделей, сравнивать качество нескольких альтернативных моделей бинарного выбора с разным количеством объясняющих переменных можно, опираясь на значения информационных критериев Акаике (AIC) и Шварца (SC):
А1С = -™±+*Р, SC = -^L + ^,
п п п п
а также информационного критерия Хеннана — Куинна:
ТТ„ 2 Lk 2рп(пгі)
HQ = + ——
п п
где Lk — максимальное значение функции правдоподобия для к-и из альтернативных моделей; р — количество объясняющих переменных в этой модели.
При этом среди нескольких альтернативных моделей выбирается та, которая минимизирует значение статистики критерия. Заметим, что эти три критерия различаются размерами «штрафа», который приходится платить за включение в модель большего количества объясняющих переменных.
 |
По всем трем критериям наилучшей признается логит-модель. Она имеет наибольший среди трех моделей максимум функции правдоподобия. Вместе с тем отметим, что преимущество логит-модели над пробит-моделью весьма мало.
Для проверки адекватности подобранной модели имеющимся данным существует ряд статистических критериев согласия, одним из них является критерий Хосмера — Лемешоу (Hosmer-Lemeshow test)1. Не будем описывать его детально, воспользуемся тем, что этот критерий реализован в некоторых пакетах статистического анализа, в том числе в пакете ЕViews. Отметим только, что этот критерий основан на сравнении количеств предсказываемых моделью и действительно наблюдаемых случаев с угf = 1 в нескольких группах, на которые разбивается множество наблюдений.
Сопоставим результаты применения критерия Хосмера — Лемешоу к подобранным выше моделям бинарного выбора. В табл. 4.5 приведены Р-значения, соответствующие статистике Хосмера — Лемешоу (рассчитанные по асим
Подробнее об этом критерии см., например, в (Hosmer, Lemeshow, 1989).
 |
В заключение рассмотрим пример подбора модели бинарного выбора с несколькими объясняющими переменными. В этом примере фигурируют следующие финансовые показатели 66 фирм на конец одного и того же года:
х,=
Оборотный капитал Общая сумма активов'
Нераспределенная прибыль Общая сумма активов
_ Доходы до вычета процентов и налогов
л.3 —
Общая сумма активов
х4 =
х5 =
Рыночная стоимость активов за вычетом задолженности Балансовая стоимость общей суммы обязательств
Объем продаж
Общая сумма активов
В течение последующих двух лет половина из этих фирм обанкротилась. Фирмы занумерованы от 1 до 66 так, что первые 33 фирмы в этом списке обанкротились. Введем индикаторную переменную^, полагая
Уі
[О для / = 1, ...,33, [1 для / = 34,...,66,
т.е. Уі=і9 если фирма выжила в течение двух лет.
Попробуем сначала подобрать к указанным данным пробит-модель
ух: = Ф(а + Дхл+ —+ Дх/5) + ^, / = 1,...,66.
При попытке оценить параметры такой модели наталкиваемся на указанное ранее затруднение, которое связано с расходимостью итерационного процесса. Поэтому приходится отказаться от желания включить в правую часть модели сразу все имеющиеся в распоряжении показатели и перейти к рассмотрению редуцированных моделей.
При оценивании большинства моделей, в которых используются только 4 из 5 финансовых показателей, опять наталкиваемся на ту же проблему. Итерационный процесс сходится только для двух моделей, включающих в качестве объясняющих переменных (помимо константы) наборы показателей (Xl9 Х2, Х4, Х5) и (Х{9 Х39 ХЛ9 Х5) соответственно. Однако каждый из оцененных коэффициентов этих моделей имеет Р-значение, превышающее 0.10, что указывает на необходимость дальнейшей редукции моделей.
Среди моделей, использующих только 3 финансовых показателя, лучшей по McFaddenR2 (LRI) является модель с набором объясняющих переменных (1, Х29 ХЛ9 Х5), но и в ней все оцененные коэффициенты имеют Р-значения, превышающие 0.184.
Вообще множество моделей, в которых оценки коэффициентов при всех включенных в их правые части финансовых показателях статистически значимы (при 5\%-м пороге), исчерпывается 6 моделями, которые в качестве объясняющих переменных имеют наборы
(I, Х{, Х4), (I,Х3,Х4),
(i,x,x (i,x2), (i,x3), (i,x4).
 В табл. 4.6 приведены результаты, характеризующие сравнительное качество этих моделей. В первой графе указаны финансовые показатели, включенные в модель.
В табл. 4.6 приведены результаты, характеризующие сравнительное качество этих моделей. В первой графе указаны финансовые показатели, включенные в модель.
Критерий Хосмера — Лемешоу признает неадекватной последнюю модель и близкой к неадекватной предпоследнюю модель. Среди остальных 4 моделей по всем показателям лучшей оказывается модель, использующая единственный финансовый показатель^. Она дает следующую оценку вероятности выживания фирмы:
Р{у. = 1| х.} = ф(-0.6625 + 0.0987х/2).
Оцененная модель правильно предсказывает банкротство 31 из 33 обанкротившихся и выживание 32 из 33 выживших фирм. Это соответствует 95.45\% правильных предсказаний, тогда как тривиальная модель дает в данном случае только 50\% правильных предсказаний.
Таким образом, согласно полученным результатам вероятность выживания фирмы определяется в основном отношением размера нераспределенной прибыли к общей сумме активов фирмы и возрастает с ростом этого отношения.
Интерпретация коэффициентов
Поскольку модели логит, пробит и гомпит являются нелинейными, оцененные коэффициенты в этих моделях имеют интерпретацию, отличающуюся от интерпретации коэффициентов в линейной модели. Все эти модели имеют вид:
у, = в(вххп + • • • + 0pxip) + et = G(xf в) + є„ / = 1 л,
при этом
p{yl=\x,} = e(ylxl) = g(xJff).
Пусть к~я объясняющая переменная является непрерывной переменной. Тогда предельный эффект (marginal effect) этой переменной определяется как производная
дР{Уі=іХі} = dG(xfe) дхік дхік
и в отличие от линейной модели этот эффект зависит от значений объясняющих переменных для /-го субъекта х, = (хп, хір)Т. Малое изменение Ахік к~и объясняющей переменной приводит (при неизменных значениях остальных объясняющих переменных) к изменению вероятности P{yt = 11 xt) на величину, приближенно равную
дхік дхік
Заметим, что, поскольку модель нелинейна, при интерпретации значений предельного эффекта надо иметь в виду отклик интересующей нас вероятности именно на малые приращения объясняющей переменной.
В случае когда сама объясняющая переменная принимает только два значения — 0 и 1 (дамми-переменная), указывающие на наличие (1) или отсутствие (0) у субъекта определенного признака, малые изменения переменной, о которых говорилось выше, попросту невозможны. В этом случае предельный эффект определяют просто как разность p{j,.=i|x;,^.=i}-p{j,.=i|x;,«f,.=o},
где dt — рассматриваемая дамми-переменная;
х* — вектор значений остальных объясняющих переменных.
В пробит-модели P{yt = 11 х,} = Ф(х[в) = Ф{вххп + ... + врХір) малое изменение Ахік к-и объясняющей переменной приводит (при неизменных значениях остальных объясняющих переменных) к изменению вероятности Р(У/ = 11 х,} на величину, приближенно равную:
АР/ 1І ,„дФ(вХП++ вРХір) д
АР{у, = = • Axik =
axik
= <р(хІв)ЄкАхік,
1 =L
где <p(t) = —f=e 2 — функция плотности стандартного нормального распре^п деления N(0, 1), математическое ожидание которого
равно 0, а дисперсия равна 1.
Предельный эффект к-и объясняющей переменной равен (р(х]6)6к (а не вк — как в линейной модели).
В логит-модели Ру. = 11 jcf} = Mxj6) = К(вххІХ + ... + 0рХір) малое изменение Ахік к-и объясняющей переменной приводит (при неизменных значениях остальных объясняющих переменных) к изменению вероятности Р{у( = 11 х,} на величину, приближенно равную:
дхік дхік
Учитывая явный вид функции A(z), найдем отсюда:
АР{у, = {A(xj0)(\{х]в))вк}Ьхік.
Выражение, заключенное в фигурные скобки, представляет собой предельный эффект для к-и объясняющей переменной в логит-модели.
Заметим теперь следующее. Пусть р = Р(А) — вероятность некоторого
события А, О <р < 1. Отношение ^ часто называют шансами {odds) этого
-р
2
события. Например, если р = —, то —^— = ^= 2, и шансы на то, что собы3 -р j_
2
тие А произойдет, равны 2:1 («два к одному», или «в 2 раза выше»). Лога( v
рифм отношения называют логитом (logit), logit(/>) = In . Если
l-р к1~р)
logit(p) = 0, то р = 1 -р = 0.5, т.е. шансы для события А равны «50 на 50». Если logit(/?) > 0, то больше шансов, что событие А произойдет. Если logit(p) < 0, то больше шансов, что событие А не произойдет.
gw( х^ 0}
Пусть теперь р = P{yt = 11 *.}. В логит-модели р = A(xj0) = —' ,
1 + ехр(х/ в)
1-р = —=—, так что logit(p) = х[в9 т.е. логит-модель линейна в отно1 + ехр(дс/ в)
шении логита. Отсюда вытекает, что изменение значения k-й объясняющей переменной на величину Axik приводит (при неизменных значениях осталь-
ных объясняющих переменных) к изменению значения In
}-р.
на вкАхік,
что при малых значениях Axik означает изменение значения отношения ^
-р
приблизительно на №0к&хік\%.
Иначе говоря, шансы на то, что у{ = 1, изменяются приблизительно на 100ЄкЬхік\%.
Проверка выполнения стандартных предположений
При анализе обычных линейных моделей регрессии проверка выполнения стандартных предположений осуществляется посредством графического анализа и различных статистических критериев, призванных выявить наличие таких особенностей статистических данных, которые могут говорить не в пользу гипотезы о выполнении стандартных предположений.
Проанализируем, однако, график остатков для пробит-модели, оцененной по рассмотренному выше множеству данных о наличии (отсутствии) собственных автомобилей у 1000 семей (рис. 4.5). Этот график по форме разительно отличается от тех, с которыми приходится сталкиваться при анализе обычных моделей регрессии с непрерывной объясняемой переменной. И это неудивительно, так как, если вспомнить свойства случайных ошибок в моделях бинарного выбора, при заданных значениях объясняющих переменных случайная величина et может принимать в і-м наблюдении только два значения. Следовательно, привычный графический анализ остатков не дает здесь полной информации, и более полезным является непосредственное использование подходящих статистических критериев.
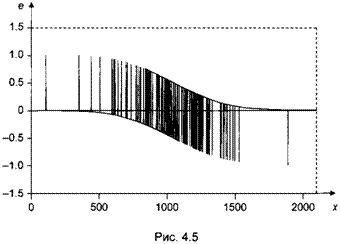 |
Здесь следует отметить, что сравнение максимумов правдоподобий в двух гнездовых моделях фактически уже использовалось выше. Действительно, на таком сравнении основаны определения коэффициентов:
pseudoR2 = 1
1 +
1
2(lnL1-lnL0)
McFaddenR2 =Ь ІПІ*
ІП In
В этом случае в качестве гнездовых рассматриваются основная модель (с одной или несколькими объясняющими переменными, помимо константы) и вложенная в нее тривиальная модель (в правой части объясняющей переменной является только константа).
Сосредоточимся на некоторых статистических критериях проверки гипотез о выполнении стандартных предположений, но, прежде чем перейти к рассмотрению и применению подобных критериев, изучим процесс порождения данных, приводящий к пробит-модели.
Предположим, что переменная у] характеризует «полезность» наличия некоторого предмета длительного пользования для /-й семьи, и эта полезность определяется соотношением
У і = А хі і + • • • + Рр хіР + єі > *' = !,...,«,
где хп, ..., хір — значения р объясняющих переменных для /-и семьи;
єХ9 ...9єп — случайные ошибки, отражающие влияние на полезность наличия указанного предмета для /-й семьи каких-то неучтенных дополнительных факторов.
Пусть і-я семья приобретает этот предмет длительного пользования, если у і > уі9 где Yi — пороговое значение (threshold value), и индикаторная переменная ^г отмечает наличие (у,= 1) или отсутствие (у, = 0) данного предмета у /-й семьи. Тогда
Р{Уі = 11*,} = Р{у* > ГіХі) = P{frxn + • + Ppxip + et > Yixi) =
= p{£i>Yi-Pxn fipX^Xth
и если xn = 1, то
Р{Уі = 1 I*,} = P{€t > (Yt A ) (Р2*і2 + • • • + PPXip ) I Хг } •
Если предположить, что ошибки єІ9 ...9 €„ — независимые в совокупности (и независимые отxij9j = 1, ...,/>) случайные величины, имеющие одинаковое нормальное распределение et ~ N(09 сг2)9 тогда
Р{у, = iXi}=i-Jr^A&*п+"+Р*) _
= Ф
-Г/+А , P2Xi2+-~ + PpXiP
V У
(Здесь использовали вытекающее из симметрии стандартного нормального распределения соотношение 1 Ф(х) = Ф(-х).) Обозначив
*|=ZZl±A в l j = 2,...,p, а а
получим:
Р{уі=іхі} = Ф(вІхп + + врхір) = Ф{х]в).
Но именно таким образом и определяется пробит-модель.
Пусть имеются в наличии только значения уі9 хП9 хір9 а значения у не доступны наблюдению. В таком случае переменную у называют латентной (скрытой) (latent variable). Применив метод максимального правдоподобия, получим оценки параметров пробит-модели вХ9 в , но по ним нельзя однозначно восстановить значения параметров Д, J3p9 если неизвестны
значения а и у]9 уп. Действительно, если оценки <т, уХ9 уп9 Д, (Зр таковы, что
4=4. j.2,....p.
(7 <7
то к тем же значениям вх, ..., 0^ приводят оценки ка9 куХ9 ..., £Д, ..., где А: — произвольное число, -оо < к < оо.
Таким образом, в рассмотренной ситуации для однозначной идентификации коэффициентов Д, Рр необходима некая нормализация функции полезности. В стандартной модели предполагается, что а = 1 и ух = ... = уп = О, так что
рх=вХ9...9 рр = ёр9
и именно такую модель будем теперь рассматривать.
Прежде всего заметим, что получение оценок параметров Д, Др в такой модели методом максимального правдоподобия принципиально опирается на предположение о нормальности ошибок єХ9 є1, ~ N(09 1). Поэтому важной является задача проверки этого предположения, т.е. проверка гипотезы
Н0:єХ9...9 e„~U.d9 £,-N(0,1).
Наряду со стандартной моделью (модель 1) рассмотрим модель 2, отличающуюся от стандартной тем, что в ней
P{st <t} = <t)(t + (oxt2 +co2t3)9
так что
Р{у, = 1|х,} = Ф{х]в + сох{х]в)2 + а>2{х]в)г).
При этом модель 1 является частным случаем модели 2 (при сох со20), таким образом модели 1 и 2 — гнездовые, и в рамках более общей модели 2 гипотеза #0 принимает вид
Я0: сох со2 = 0.
Класс распределений вида P{£t< t) = Ф(/ + coxt2 + co2t3) допускает асимметрию и положительный эксцесс (островершинность) распределения. График на рис. 4.6 позволяет сравнить поведение функции стандартного нормального распределения Ф(/) (серая линия) и функции Ф(/ + 0.5/2 + 0.5/3) (черная линия).
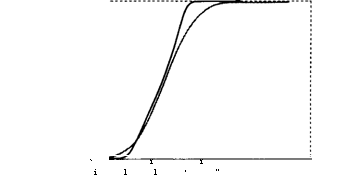 Ф А
Ф А
1.0"
0.8-0.6-0.4-0.2-
РИС. 4.6
Пусть Lj — максимум функции правдоподобия в модели j (j = 1, 2) и LR = -2ln^= 2(lnL2 ІпІ!).
Критерий отношения правдоподобий (likelihood ratio test — LR test) отвергает гипотезу #0, если наблюдаемое значение статистики LR превышает критическое значение LRcrin соответствующее выбранному уровню значимости а. Этот критерий асимптотический: критическое значение LRcrit вычисляется на основе распределения, к которому стремится при п —> оо распределение статистики LR, если гипотеза Я0 верна. Этим предельным распределением является распределение хи-квадрат с двумя степенями свободы. Итак, в соответствии с критерием отношения правдоподобий гипотеза Н0 отвергается, если
LR> xla{2),
где z2-a(2)— квантиль уровня (1-а) распределения хи-квадрат с двумя степенями свободы.
Обратимся опять к смоделированным данным о наличии или об отсутствии собственных автомобилей у 1000 домохозяйств.
Оценив пробит-модель (модель 1) по этим данным, получим результаты, приведенные в табл. 4.7.
Оценивание модели 2 дает результаты, представленные в табл. 4.8.
Соответственно здесь:
LR = 2(lnl2 InI,) = 2(275.7686 274.6286) = 2.28.
Поскольку ^q95(2) = 5.99, критерий отношения правдоподобий не отвергает гипотезу #0 при уровне значимости 0.05. Заметим еще, что значению LR = 2.28
 соответствует (вычисляемое по асимптотическому распределению хгЩ) ^-значение 0.6802. Таким образом, критерий отношения правдоподобий не отвергает гипотезу Н0 при любом разумном уровне значимости.
соответствует (вычисляемое по асимптотическому распределению хгЩ) ^-значение 0.6802. Таким образом, критерий отношения правдоподобий не отвергает гипотезу Н0 при любом разумном уровне значимости.
Еще одним «стандартным предположением» является предположение об одинаковом распределении случайных ошибок е{ в процессе порождения данных. В сочетании с предположением нормальности этих ошибок данное условие сводится к совпадению дисперсий всех этих ошибок. Нарушение этого условия приводит к гетероскедастичной модели и к несостоятельности оценок максимального правдоподобия, получаемых на основании стандартной модели. Для проверки гипотезы совпадения дисперсий можно опять рассмотреть какую-нибудь более общую модель с наличием гетероскедастичности, частным случаем которой является стандартная пробит-модель.
В примере с автомобилями можно допустить, что дисперсии случайных ошибок в процессе порождения данных возрастают с увеличением значений дс,-, например, как
Die^Xf) = ехр(/гхг), к > 0,
так что (модель 3)
Р{у, =іХі} = Ф
а + /?х, д/ехр^х,)
Здесь имеем две гнездовые модели — модель 3, допускающую гетероске-дастичность в указанной форме, и модель 1 (стандартную пробит-модель) как ее частный случай. В рамках модели 3 выполнение стандартных предположений соответствует гипотезе Н0: к = 0. Оценивание модели 3 по смоделированным данным дает результаты, приведенные в табл. 4.9.
 Таблица 4.9
Таблица 4.9
При сравнении с моделью 1 получаем:
LR = 2 (lnL3 lnL{) = 2 (275.7686 275.2619) = 1.013.
Это значение меньше критического значения 3.84, соответствующего уровню значимости 0.05 и вычисленного как квантиль уровня 0.95 асимптотического распределения хи-квадрат с одной степенью свободы. Следовательно, гипотеза Н0: к = 0 не отвергается.
 Отметим, что решения, принятые на основании критерия отношения правдоподобий, согласуются с решениями, принимаемыми в рассмотренном примере на основании информационных критериев (табл. 4.10).
Отметим, что решения, принятые на основании критерия отношения правдоподобий, согласуются с решениями, принимаемыми в рассмотренном примере на основании информационных критериев (табл. 4.10).
По всем трем критериям стандартная пробит-модель предпочтительнее альтернативных моделей.
КОНТРОЛЬНЫЕ ВОПРОСЫ
Когда приходится использовать модели, в которых объясняемая переменная принимает только два различных значения? Почему в подобных ситуациях линейные модели оказываются непригодными?
Как используется метод максимального правдоподобия для оценивания параметров модели бинарного выбора?
Чем различаются модели пробит, логит и гомпит? В каких ситуациях оценки максимального правдоподобия параметров этих моделей не определены?
Как интерпретируются оцененные коэффициенты в моделях пробит, логит и гомпит?
Какие варианты коэффициента детерминации используются при подборе моделей бинарного выбора?
Как можно сравнить качество нескольких альтернативных моделей бинарного выбора с разным количеством объясняющих переменных?
Для какой цели используется критерий Хосмера — Лемешоу?
Каким образом линейная модель с латентной объясняющей переменной приводит к пробит-модели? Как проверяется выполнение стандартных предположений об ошибках в латентной модели?

Обсуждение Эконометрика Книга вторая Часть 3
Комментарии, рецензии и отзывы