Тема 4.3 цензурирование модели регрессии (тобит-модели)
Тема 4.3 цензурирование модели регрессии (тобит-модели)
Модель тобит-1
Развивая пример с наличием или отсутствием у семьи собственного автомобиля, представим, что имеются следующие данные: для семей, обладающих автомобилем, известна стоимость этого автомобиля ^ (если в семье несколько автомобилей, то st — суммарная стоимость этих автомобилей). Таким образом, здесь наблюдаются пары (xi9 price observedt)9 где xt — среднедушевой месячный доход і-й семьи:
si9 если і-я семья имеет автомобиль, price _observedi = <
[О, если і-я семья не имеет автомобиля.
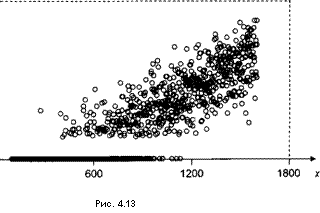
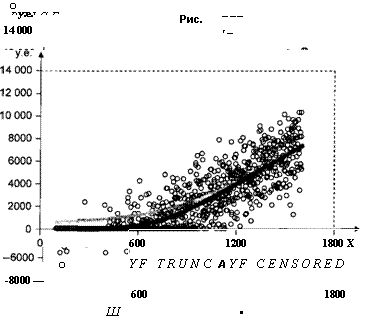
Обратимся к смоделированной выборке, состоящей из 1000 семей со среднедушевым месячным доходом от 100 до 1600 у.е. Для удобства наблюдения упорядочены в соответствии с возрастанием xi9 так что х{ < х2 < ... ^ *юооДиаграмма рассеяния для этих данных имеет весьма специфический вид (рис. 4.13).
Большое количество точек (их 418), расположенных на оси абсцисс, показывает, что 418 семей из 1000 рассматриваемых не имеют собственного автомобиля. В то же время у семей, владеющих автомобилем, минимальная цена автомобиля равна 2002 у.е., и это может означать, что на рынке, в том числе на вторичном, просто нет автомобилей с ценой менее 2000 у.е.
Как проводить статистический анализ подобных данных? Можно попытаться, например, использовать все 1000 наблюдений и по этим наблюдениям методом наименьших квадратов оценить линейную статистическую модель
price _observedi =а + J3x{ + єг
Результаты такого оценивания приведены в табл. 4.22.
 Pricejobserved ж у.е
Pricejobserved ж у.е
14 ООО--12 ООО -10 000 80006000400020000 -0
Оценка линейной статистической модели (582 наблюдения)
 В то же время можно проигнорировать наблюдения с price_observedt = 0 и произвести оценивание той же линейной модели только по остальным наблюдениям (в количестве 582). При таком подходе получим результаты, представленные в табл. 4.23.
В то же время можно проигнорировать наблюдения с price_observedt = 0 и произвести оценивание той же линейной модели только по остальным наблюдениям (в количестве 582). При таком подходе получим результаты, представленные в табл. 4.23.
Рисунок 4.14 позволяет сравнить значения price_observedi9 прогнозные значения, полученные по первой модели (по 1000 наблюдениям), т.е.
рпсе/_Ш( =a + J3xt =-2427.821 + 6.915595*,.,
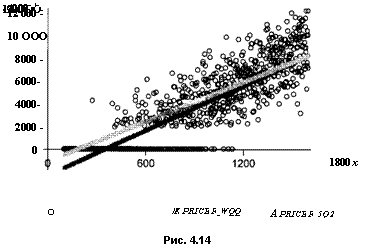 |
pricef_ 5 82,= а + JBxt = -1037.189-f 6.119677*,..
Конечно, по такой картине вряд ли можно говорить об адекватном представлении данных этими двумя моделями. Желательно построить модель процесса, который мог породить такого рода данные. Для этой цели можно опять использовать идею латентной переменной, но в данной ситуации, скорее, следовало бы говорить о частично наблюдаемой переменной.
Обращаясь к той же выборке, состоящей из 1000 семей, рассмотрим линейную модель наблюдений
price* = а + J3x{ +&єі9 / = !,...,«,
где price* — цена, которую уплатила за покупку автомобиля (автомобилей)
і-я семья, имеющая автомобиль, или цена, которую уплатила бы за покупку автомобиля і-я семья, не имеющая автомобиля, если бы эта семья решила приобрести его.
Естественно предполагать, что при этом Р > 0, так что возрастание х( приводит в среднем к возрастанию price*. Однако существенное влияние других ненаблюдаемых факторов, объединяемых в случайную составляющую, может приводить к значительным отклонениям переменной price* от «средней линии» price* = а + /Зх. Возможные отрицательные значения price* свидетельствуют о наличии факторов, в той или иной степени препятствующих планированию каких бы то ни было расходов на покупку автомобиля.
Предположим, что і-я семья покупает автомобиль по цене price*, если последняя превышает минимально возможную стоимость ;г автомобиля на рынке (первичном и вторичном), т.е. если price* > у.
В такой модели значения переменной price* доступны лишь для части наблюдений — только для семей, имеющих автомобиль. Для остальных семей известно только, что price* < у. Такие данные называют цензурированными (censored data). В данном случае данные цензурированы слева на уровне у, а модель получения этих данных называют цензурированной линейной моделью (censored linear model). При этом наблюдается цензурированная переменная
I price* если price] > у, price_censoredi ъ
[у если pricet < у.
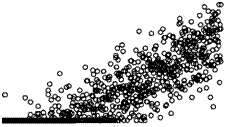
Диаграмма рассеяния переменных xi9 price_censoredi в нашем примере представлена на рис. 4.15.
 |
14 000-12 000-10 000-8000 6000 Н 4000 2000 0
600
1200
1 *
1800 х
Рис. 4.15
Если значение ^известно, то вместо переменной price* можно рассмотреть переменную у і = price* у. Значения последней также наблюдаются только для семей, имеющих автомобиль. Для остальных семей положим yt = 0, так что
| price у, если price) > у,
о,
если price( < у.
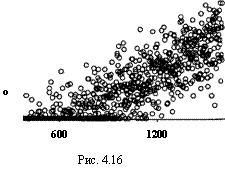
Диаграмма рассеяния переменных xi9 у{ в нашем примере изображена на рис. 4.16.
Теперь можно поставить вопрос о подходящем методе оценивания параметров цензурированных линейных моделей.
У, У.е.
14 00012 000-
 |
0
1800 х
Обычно при рассмотрении подобных ситуаций опираются на предположение о нормальности распределения ошибок е{. (Впрочем, имеющиеся пакеты статистических программ позволяют проводить статистический анализ и для других распределений ошибок. Например, в пакете Е Views допускается вместо нормального распределения ошибок использовать логистическое распределение и распределение экстремальных значений первого типа.)
Предположим, что имеем дело с некоторым показателем у*9 значения которого наблюдаются только при условии у] > 0 (в нашем примере в качестве такого показателя выступала переменная (price* 2000)). Пусть в правую часть модели для этого показателя включаются р объясняющих переменных (показателей, характеризующих і-й субъект), т.е.
где el9 єп — ошибки, независимые в совокупности (и независимые от xij9 j 1, ...,/?) случайные величины, имеющие одинаковое нормальное распределение е-г ~ N(0, <т2).
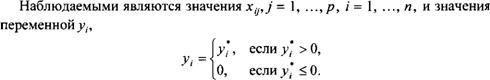
О такой цензурированной модели регрессии говорят как о стандартной тобит-модели (tobit model).
В стандартной тобит-модели для фиксированных значений xij9j = 1, имеем
У]~Ы{вхХп++ врХ1р,<72),
E(yix!!J = U—,P) = Охха +■■■ + врхір,
т.е.
Е(уіхі) = х]в9
где, как и ранее, обозначено xt = (хП9 хір)Т9 в = (вІ9 вр)т. В нашем примере значение коэффициента в} определяет изменение ожидаемой суммы расходов на (возможную) покупку автомобиля для семьи с вектором показателей х, = (хц9 ..., xipf при увеличении на единицу значенияу-го показателя.
Если для оценивания коэффициентов 6j использовать только наблюдения с у і > О, получим усеченную модель регрессии (truncated regression):
Уі=вхі+'+ врхіР+єі> ' = 1 «і.
где пх — количество семей, имеющих автомобиль (среди всех п рассматриваемых семей).
Конечно, при переходе к усеченной модели придется заново нумеровать используемые пх наблюдений. В такой модели для значений w > О имеем
Р{Уі<п} = Р{Уі <м?Уі >0}
Р{0 < у. < w} Р{Уі>0}
 |
 |
Р{Уі >0}
„ dP{yi < w} ,
Ьсли взять производную ■ -, получим функцию плотности расdw
пределения случайной величины у{ (условного при заданном *,):
w — х, О
Ру,(™) =
1
V ° J
ф
Отсюда получаем выражение для условного математического ожидания:
00 ( Е(Уіхі)= wPyi (w)dw = х]в + а Л
V а J
где обозначено A(z) =
Ф(г)
Таким образом, £(y(.|jc,-) — нелинейная функция отдг, и в, причем
Е(уіхі)>хТіЄ.
Рассмотрим теперь другой подход к оцениванию коэффициентов исходной модели
у]=вхха +--+ врхір+єі9 1 = 1,..„и,
при котором неполные наблюдения не отбрасываются, а учитываются при оценивании. В рамках этого подхода в качестве объясняемой берем переменную
Уі
I О,
х] 6 + єt, если х]в + єt > О,
если xf в + є,< 0.
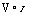 |
Р{Уі=0хі} = Р{єі<-хІв} = Ф
а для w > 0
v а J
= 1-ф
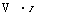 |
[a a J
Ф
W-X: в 1
Это приводит к следующему выражению для условного математического ожидания у(:
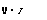 |
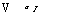 Е(Уіхі) = 0
Е(Уіхі) = 0 1-Ф
w<p
W — X: О
dw-Ф
V а J
(х]в^
xfO + crA
х!вл
Ф —-
Оно отличается от выражения для Еіу^Хі) в усеченной модели умножени-
ем последнего на Ф
, т.е. на величину, меньшую 1. Раскрыв скобки
в правой части, получим
Е(<Уіхі) = х,івФ = х!вФ
v G )
+ <j<p
v а J (х]в^
Ф
v G j
V ° J
Предельный эффект изменения переменной дг(у равен:
дЕЫх,)
■ = 0уФ
ЭХ::
т.е. меньше значения коэффициента 6j в исходной модели: он получается умножением этого коэффициента на вероятность того, что у* > 0.
Заметим в связи с этим, что если Е(у(х() — условное математическое ожидание значения у. в усеченной модели, то для него
• = 0j[l-zA(z)-A (z)],
дх;1
где A(z) =
х]в
z — -
Продолжим рассмотрение смоделированной выборки, состоящей из 1000 семей, 582 из которых имеют автомобиль. Подберем к тем же данным усеченную и цензурированную модели.
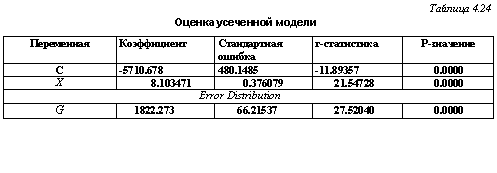 Заметим, что если переменная у* = price* 2000 порождается моделью у* = а + jBx{ + єі9 і = 1, 1000, то сама переменная price* порождается моделью price* = (а + 2000) + /3xt + et. Поэтому достаточно произвести оценивание коэффициентов модели^* = а + J3x( + єі9 опираясь на данные (xi9yt). Такое оценивание дает результаты, представленные в табл. 4.24 (для усеченной модели) и табл. 4.25 (для цензурированной модели).
Заметим, что если переменная у* = price* 2000 порождается моделью у* = а + jBx{ + єі9 і = 1, 1000, то сама переменная price* порождается моделью price* = (а + 2000) + /3xt + et. Поэтому достаточно произвести оценивание коэффициентов модели^* = а + J3x( + єі9 опираясь на данные (xi9yt). Такое оценивание дает результаты, представленные в табл. 4.24 (для усеченной модели) и табл. 4.25 (для цензурированной модели).
 Получаем следующие оцененные модели для прогноза значений переменной price]:
Получаем следующие оцененные модели для прогноза значений переменной price]:
price] =-3710.678 + 8.103471 xi (усеченная модель),
price] = -4041.883 + 8.363125 xt (цензурированная модель).
Дисперсии случайных составляющих оцениваются соответственно как 1822.2732 и 1823.5652. Заметим, что «теоретическая» модель, по которой генерировались данные, имела вид:
price] = -3600 + 8 xt +1800 и t,
где Wj, w1000— независимые случайные величины, имеющие одинаковое стандартное нормальное распределение N(0, 1).
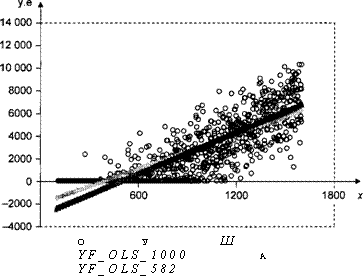
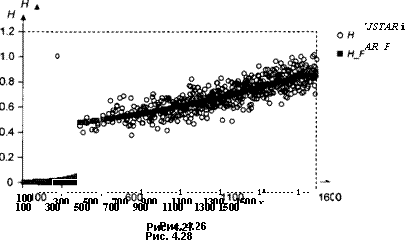
На рис. 4.17 для сравнения показан разброс значений переменной price] и прогнозных значений для этой переменной, полученных по оцененной усеченной модели (price_starf_truri) и по оцененной цензурированной модели (price_starf сет). Отметим, что прогнозные значения, полученные по двум оцененным моделям, весьма близки.
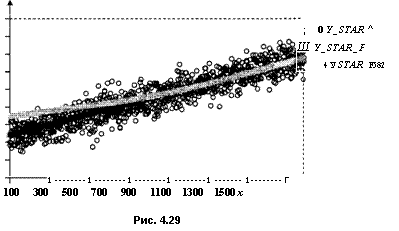
На рис. 4.18 проиллюстрирован разброс значений переменной yt и ожидаемых значений переменной^, рассчитанных по двум оцененным моделям.
Отметим, что для xt > 1330 ожидаемые значения^, рассчитанные по цензурированной модели, больше ожидаемых значений^, рассчитанных по усеченной модели. Однако это различие практически незаметно. В то же время для xt < 1330 ожидаемые значения^, рассчитанные по цензурированной модели, меньше ожидаемых значений j/,, рассчитанных по усеченной модели, причем это различие становится весьма заметным при уменьшении значений xt.
Заметим также, что ожидаемые значения^, рассчитанные и по усеченной, и по цензурированной моделям, положительны для всех 1000 наблюдений, тогда как это не выполняется для линейных моделей, подобранных методом наименьших квадратов.
 |
Так, оценивание модели yt = а + f5xt + е{ по всем 1000 наблюдениям обычным методом наименьших квадратов дает результаты, представленные в табл. 4.26.
Для xt < 470 подобранная модель прогнозирует отрицательные значения объясняемой переменной. При подгонке такой модели методом наименьших квадратов по 582 наблюдениям получаем результаты, приведенные в табл. 4.27.

 |
Как было сказано ранее (во второй части), одним из показателей качества прогноза произвольного временного рядаг,, / = 1, является его средняя абсолютная процентная ошибка (МАРЕ — mean squared absolute error). Она определяется следующим образом: если і, — прогнозное значение для zi9 то
МАРЕ =-У 100
Z— Z-
Сравним качество полученных альтернативных прогнозов для у{ с точки зрения средней абсолютной процентной ошибки (табл. 4.28). Как видно из этой таблицы, наилучшее качество имеют прогнозы, полученные с использованием цензурированной модели регрессии.
 Таблица 4.28
Таблица 4.28
xj в + сгЯ
у а /
Ф
v G J
= Е(уІхІ)-Ф
у ° J
где Eiy^Xi)—условное математическое ожидание значения у( в усеченной модели.
Отсюда получаем следующее разложение:
дх„
= Ф
ЭХ::
Ґхїе)дЕ(УіХі) ~
v ° J
дФ
у а J
ЭХ;:
Первое слагаемое отражает изменение в ожидаемых значениях yt > О,
взвешенное с весом Ф
= Р{у. > 0}, а второе — изменение вероятности Р{Уі > 0}, взвешенное с весом, равным £(у,.|дг,-). Заметим в связи с этим, что
дФ
дР{Уі>0} etc,,.
у ° J
дху
1
:—<Р
а
у G у
в,
показано на рис. 4.21.
В нашем примере изменение E(ytxt) показано на рис. 4.20 (по оси абсцисс на этом и следующих 5 графиках откладываются значения среднемесячного дохода на одного члена семьи).
~ дР{у,>0}
Изменение производной
дхИ
дЕ(ух.)
Входящие в разложение для lJ-Lслагаемые изображены на рис. 4.22
дх,.
и 4.23.
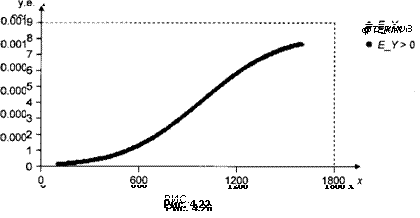 |
 дЕ(у х)
дЕ(у х) В сумме они дают функцию —1— = в Ф|
dxtj
на рис. 4.24.
которая представлена
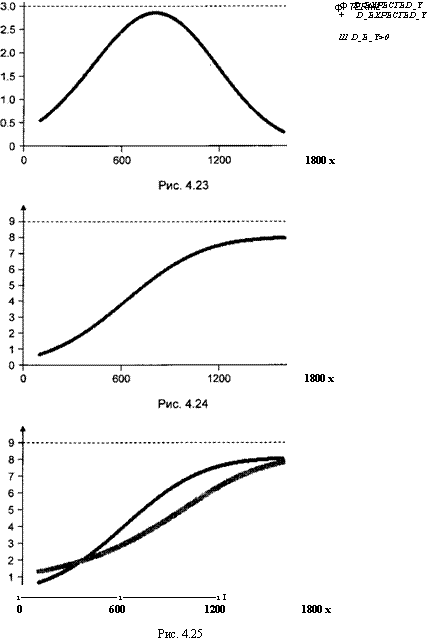 |
Рисунок 4.25 позволяет сравнить влияние единичного возрастания дохода на ожидаемые значения yt во всей популяции (D EXPECTED Y) и среди семей cyi>0(D_E_Y>0).
Модель тобит-И
Выше была рассмотрена линейная модель наблюдений
price* = а + /3xt + <тєі9 і = 1,..., п,
где price* — цена, которую уплатила за покупку автомобиля (автомобилей) і-я семья, имеющая автомобиль, или цена, которую уплатила бы за покупку автомобиля і-я семья, не имеющая автомобиля, если бы эта семья решила приобрести его.
При этом предполагали, что і-я семья покупает автомобиль по цене price*, если price* > у Таким образом, в этой модели решение о приобретении или неприобретении автомобиля определяется самой ценой, по которой предполагается приобрести автомобиль. В то же время можно рассмотреть и другую модель, в которой процесс принятия решения о стоимости покупаемого автомобиля отделен от процесса принятия решения о покупке автомобиля.
Пусть имеем дело с некоторым показателем у*9 значения которого наблюдаются не для всех /. Значение у* наблюдается, если выполнено условие h* > О, где h* — некоторая функция полезности. Предположим, что:
У* = Хув{ +eU9 1 = 1,...,Л,
ht — x2i в2 + є2і,
где хи, = (хиj, хХрхj)T—вектор значений рх объясняющих переменных
в уравнении для у*; Q = (#11 > 6рхУ — вектор коэффициентов при этих переменных; x2i' = (*2i,/> х2р2,іУ—вектор значений р2 объясняющих переменных
в уравнении для А/; #2 = (#219 • •02р2)Т — вектор коэффициентов при этих переменных.
Случайные составляющие єии є2і могут быть коррелированными, так что Cov(su, є2і) Ф 0. Следуя обычной практике, будем предполагать, что двумерные случайные векторы (єІІ9 є2і)т, і = 1, п, независимы в совокупности и имеют одинаковое двумерное нормальное распределение N2(0, Z) с нулевым вектором математических ожиданий и ковариационной матрицей
( „2
'12
V°"l2
т.е.
id.d. N,
'12
S2iJ
V°"l2
>2J)
Для нормализации функции полезности полагаем ст2 = 1. Наблюдаемыми являются:
значения объясняющих переменных xXji, j = 1, ..x2ji, j = 1, ...,p2»
/'= 1,л;
значения переменной h{.
II, если Л* >0, [О, если А. <0;
значения переменной :
_ j>>* если hi =1, [о, если hi = 0.
Определенную таким образом модель называют стандартной тобит-И моделью (Tobit II model). Соответственно о модели, рассмотренной в предыдущем разделе, в этом контексте говорят как о стандартной тобит-1 модели
(standard Tobit I model).
Замечание 4.3.1. Объясняющие переменные в уравнениях для у и И* могут быть как одинаковыми, так и различными. В ряде ситуаций экономическая аргументация указывает на необходимость включения в правую часть уравнения для h* («уравнение выбора») всех переменных, включенных в правую часть уравнения для у*. При этом коэффициенты при одной и той же переменной в уравнениях для у і и h * могут быть различными.
Если предположить, что хТХівх = х2ів2 и єХІ є2і9 то возвращаемся к стандартной тобит-1 модели, рассмотренной в предыдущем разделе.
Обращаясь опять к примеру с автомобилями, можно рассмотреть, например, модели, в которых значение priceопределяется по той же формуле:
price* = а + /3xt + <уєі9 / = 1,..., я, но наличие автомобиля соответствует выполнению соотношения h * > 0, в котором h* = у+ 8xt + ut, или, например, h* у+ 8xt + fcdman + ui9 где dman = 1, если главой семьи является мужчина, и dman = 0, если главой семьи является женщина. Прежде всего заметим, что (при фиксированных значениях xli9 x2l):
E{yihi=l} = xlTA + Е{еик1=1} = х*в1 +Е{ехе2і >-хт2ів2} =
= хтХівх +Ц-Е{є2е2і >-хт2ів2} = хтХІЄх +(тх2Л(хт2і62 а2
где, как и ранее, A(z) = .
0>(z)
Если ах2 = 0, то
E{ylhl=l} = xlAЭто означает, что если єХІ и є2і не коррелированы между собой, то можно, игнорируя уравнение для h *, производить непосредственное оценивание уравнения регрессии
Уі = *ЇА + єи
методом наименьших квадратов по наблюдениям с hi 1. Это приводит к состоятельному оцениванию значений хТХівх.
Однако если оХ2 ^ О, то при таком оценивании возникает смещение оценки хтив19 пропорциональное величине Я(х2ів2), которую называют в этом контексте лямбдой Хекмана (Heckman's lambda).
Получить состоятельные и асимптотически эффективные оценки параметров модели тобит-П можно, используя метод максимального правдоподобия, при котором соответствующая функция правдоподобия максимизируется по всем возможным значениям параметров модели 6l9 въ ох, <т2. Однако чаще такую модель оценивают, используя двухшаговую процедуру Хекмана (Heckman's two-stage procedure). Она проста в вычислительном отношении и дает хорошие стартовые значения для итерационной процедуры максимизации функции правдоподобия.
Идея Хекмана состоит в использовании приведенного выше соотношения
Е{уіігі=1} = хІів1+<ті2Л(хт21в2) и построении на его основе модели регрессии
Уі=х1ТА^(т12Яі+уі, где Я{ — переменная, определяемая соотношением:
Л = Я(х2ів2) = ^7^-г7 • Ф(хт2ів2)
Если єХІ не коррелирована с хХІ и х2/, то v, не коррелирована с xXi и Яі9 так что эту модель регрессии можно оценивать методом наименьших квадратов. Проблема, однако, в том, что значения Я, не наблюдаются, поскольку неизвестен вектор коэффициентов в2 в модели выбора.
Оценивание вектора в2 производится в рамках пробит-модели бинарного
выбора. При этом получаем оцененные значения Л{ = Я(х2ів2) (первый шаг процедуры Хекмана). Эти оцененные значения используются затем на втором шаге процедуры вместо Я{. Модель^ =хтХівх + стХ2Я; + vt оценивается методом наименьших квадратов, в результате получаем состоятельные (хотя и неэф
фективные) оценки для вх и аХ2. Используя эти оценки, получаем оцененное ожидаемое значение^ при заданных хи, x2i и ht = 1 в виде:
Если же нас интересует ожидаемое значение yt при заданных хи, х2і без условия hiг = 1, то оно оценивается величиной:
Е{Уіххі,х2і} = хіД.
Замечание 4.3.2. Поскольку смещение при оценивании уравнения для уметодом наименьших квадратов вызывается коррелирован-ностью єХІ и є2і9 представляет интерес проверка гипотезы
Н0: аХ2 = 0
об отсутствии такой коррелированное™ в рамках модели, оцененной на втором шаге. Отметим только, что при проверке этой гипотезы следует производить коррекцию значений стандартных ошибок оценок, учитывающую гетероскедастичность модели и тот факт, что вместо переменной А,на втором шаге используется предварительно
оцененная переменная Яг.
Заметим, наконец, что в стандартной тобит-И модели функция правдоподобия имеет вид:
2»
ЦвІ9в:
<Ti,au) = f(P{hi=0}f-hi(P{hi=l}f(yihi=l))hi,
где /(У/ІЛ/ = 1) —условная плотность распределения случайной величины у{
при А,= 1.
Здесь
РЩ=0} = 1-Ф(х2\%),
P{h> = 1} f(yth, = 1) = P{ht = іУі} f{yt),
 |
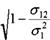
J
2Л
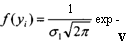 2ax2
2ax2
J
Для начала итерационной процедуры в качестве стартовых можно взять оценки параметров, полученные в процессе реализации двухшаговой процедуры Хекмана.
ПРИМЕР 4.3.1
Пусть в примере с автомобилями наличие у семьи собственного автомобиля определяется условием w* > 2000, где
w* = -3600 + 8х,+ 1800гг2/, е219 б2лш ~ Ltd. N(0, 1).
Обозначив А * = w* 2000, запишем это условие в виде А * > 0, где
А* =-5600 + 8хг. + 1800£2/,
и нормализуем функцию полезности, разделив обе части последнего равенства на 1800:
А/= -3.111 + 0.00445*; + £2/.
Пусть «потенциальная цена» автомобиля для /-й семьи определяется уравнением:
price* = 4000 46xt + єХІ9 єП9 єито ~ i.i.d. N(0, 10002).
В смоделированной выборке пары (єП9 є21)9 (suooo, £2,іооо) взаимно независимы, но Cov(sU9 є2і) = 707, так что коэффициент корреляции случайных величин єХІ9 є2і равен: рХ2 = 0.707.
В принятых выше общих обозначениях модели тобит-Н получаем:
Уі = ^11*11,/ + @2X2,i + Єі> = @2X2,i + ^22 Х22,/ + Є2і>
гдех1и = дг2М = l,xX2i = x22J = xi9 вхх =4000, вХ2 = 6, в2Х =-3.111, ^22 = 0.00445. При этом сгх = 1000, сг2 = 1, <т12 = 707.
Применив к смоделированным данным двухшаговую процедуру Хекмана, получим на первом шаге оцененное уравнение:
А/= -3.450+ 0.00476^,
а на втором шаге — оцененное уравнение:
price* = 3936.2 + 5.995хг.
Используя полученные оценки параметров в качестве стартовых значений итерационной процедуры максимального правдоподобия, приходим к уравнениям:
А* = -3.483 + 0.00480*,,
price* =4159.3 + 5.828хг..
При этом получим также &х = 1010.7, рХ2 = 0.598.
Как видим, оцененные значения параметров достаточно близки к значениям, при которых производилось порождение данных. Графики, иллюстрирующие полученные результаты, приведены на рис. 4.26 — 4.30.■
 о У
о У
У STAR F582
 У. У-е-18 000 16 000 14 000 12 000 10 000 8000 6000 4000 2000 0
У. У-е-18 000 16 000 14 000 12 000 10 000 8000 6000 4000 2000 0
 |
В условиях примера 4.3.1 смоделируем данные с измененной функцией полезности, полагая теперь
/г; = -4 + 0.003х/ + 2(^Д + ^,
где dman = 1, если главой семьи является мужчина, и dman = 0, если главой семьи является женщина.
Применив к новым смоделированным данным двухшаговую процедуру Хекмана, получим на первом шаге оцененное уравнение:
h = -4.280 + 0.00297*,. + 23Al(dman\%
а на втором шаге — оцененное уравнение:
price* = 3879.97 + 6.124x7.
 |
20 000
о У
При этом получим также &х 984.2, ри = 0.643.
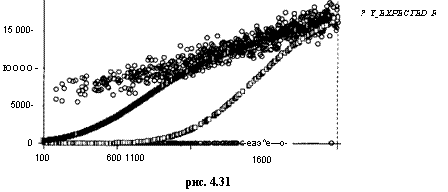
Как видим, и здесь оцененные значения параметров достаточно близки к значениям, при которых производилось порождение данных. На рис. 4.31 приведены для сравнения наблюдаемые значения переменной yt и оцененные ожидаемые значения этой переменной (YEXPECTEDF).
Обратим внимание на две ветви графика оцененных ожидаемых значений yt. Верхняя ветвь соответствует семьям, которые возглавляют мужчины, а нижняя — семьям, которые возглавляют женщины. ■
КОНТРОЛЬНЫЕ ВОПРОСЫ
Какие статистические данные называют цензурированными? Какую модель называют цензурированной линейной?
Какую модель называют усеченной моделью регрессии?
Какую модель называют стандартной тобит-моделью? Как интерпретируются коэффициенты в стандартной тобит-модели? Как производится оценивание коэффициентов?
Какую модель называют стандартной тобит-П? Каковы особенности оценивания коэффициентов такой модели? Как устроена двухшаговая процедура Хекмана?

Обсуждение Эконометрика Книга вторая Часть 3
Комментарии, рецензии и отзывы