Тема 3.2 модели с фиксированными и случайными эффектами
Тема 3.2 модели с фиксированными и случайными эффектами
Фиксированные эффекты
Обратимся теперь к методам анализа панельных данных, предназначенным в основном для анализа данных {yit9 xit; і = 1, N9 t = 1, 7}, в которых количество субъектов исследования N велико, а количество наблюдений Т над каждым субъектом мало. Вследствие малости Т в таких ситуациях затруднительно использовать технику, интерпретирующую ylt9 y2t9 ..., Унт как N временных рядов длины Т (например, технику векторных авторегрессий и моделей коррекции ошибок для нестационарных временных рядов). Основная направленность методов, предполагающих малость Г, — получение по возможности наиболее эффективных оценок коэффициентов.
Сначала сфокусируем внимание на модели, соответствующей гипотезе Нх со скалярной объясняющей переменной х:
yit =ai +fixit+uit, i = l9...,N9 t = 9...,T9
т.е.
N
yit=Y.aidij+Pxit+uit>
где dtj9 если / = у, и dtJ, = О в противном случае, так что в правой части имеем N дамми-переменных. Здесь а( трактуются как неизвестные фиксированные параметры (фиксированные эффекты — fixed effects). Как и ранее, будем предполагать1, что в этой модели
uit~i.i.d.N(09au2)9 i=l9...9N9 t=l9 Г,
и что
E(xit ujs) = О для любых i9j = 1, ..., N9 t9s=9 ...9Т9
так что х является экзогенной переменной. Альтернативные названия этой модели:
OLS-дамми-модель (LSDV— least squares dummy variables);
модель с фиксированными эффектами (FE — fixed effects);
модель ковариационного анализа (CV— covariance analysis).
В этой модели оценка наименьших квадратов, как было отмечено выше, имеет вид:
N Т PCV ~NT
IK**-*,-)2
при этом
іі(*,-*,)2
/=1 t=
Альтернативные названия этой оценки:
1 Если интересоваться только асимптотическими свойствами оценок, то здесь и далее предположение о нормальности распределения ошибок является излишним: достаточно предполагать, что uit ~ i.i.d. с E(uit) = 0 и D(uit) = о, 0 < ст* < оо (см., например, (Hsiao, 2003)).
«внутригрупповая» оценка («внутри»-оценка — within-estimator);
оценка фиксированных эффектов (FE-оценка);
ковариационная оценка.
Часто для этой оценки используют также обозначения f5w (индекс W— от
within) и flFE. Как было отмечено выше, эта оценка имеет одно и то же значение при двух альтернативных методах ее получения: в рамках статистической
N
модели yit=^Gciclij+Pxit+uit с дамми-переменными и в рамках модели
в отклонениях от групповых средних уи у і = (3(xit Xt) + (uit -ut)9 і = 1, ..., N9 t = 1, Т. Однако если количество субъектов анализа N велико, то в первой модели приходится обращать матрицу весьма большого порядка (N+ 1), тогда как во второй модели такая проблема не возникает.
Оценки для фиксированных эффектов вычисляются по формуле:
cci =yi-pxi9 i = l,..., N.
При сделанных предположениях pcv является наилучшей линейной несмещенной оценкой (BLUE — best linear unbiased estimate) для коэффициента Д
р lim pcv =р, р lim pcv =Р, р lim at = at,
Г->оо 7Y->oo Г->оо
нор lim а. Ф ai9 хотя E(at)= а(.
N->00
Таким образом, pcv является состоятельной оценкой и когда N -» оо, и когда Т -> оо, в то время как dt состоятельна только тогда, когда Т-> оо. Последнее есть следствие того, что оценивание каждого at производится фактически лишь по Т наблюдениям, так что при фиксированном Т с ростом N происходит лишь увеличение количества параметров ai9 но это не приводит к повышению точности оценивания каждого конкретного аг.
Заметим, что если нас интересует только состоятельность оценки PCV9 но не ее эффективность (т.е. свойство BLUE), то для этого не требуется строгая экзогенность х (т.е. не требуется, чтобы E(xit ujs) = 0 для любых i9j = 1, N9 t9 s = 1, Т. В этом случае достаточно выполнения соотношений E(xit uis) = О
для любых s = 1, Т и / = 1, N (т.е. требуется лишь экзогенность X в рамках каждого отдельного субъекта исследования).
В модели с фиксированными эффектами полученные выводы являются условными по отношению к значениям эффектов at в выборке. Такая интерпретация наиболее подходит для случаев, когда субъектами исследования выступают страны, крупные компании или предприятия, т.е. каждый субъект «имеет свое лицо».
Сами эффекты аі9 по существу, отражают наличие у субъектов исследования некоторых индивидуальных характеристик, не изменяющихся со временем в процессе наблюдений, которые трудно или даже невозможно наблюдать или измерить. Если значения таких характеристик не наблюдаются, то эти характеристики невозможно непосредственно включить в правые части уравнений регрессии в качестве объясняющих переменных. Но тогда мы имеем дело с «пропущенными переменными» — с ситуацией, которая может приводить к смещению оценок наименьших квадратов. Чтобы исключить такое смещение, в правые части уравнений вместо значений ненаблюдаемых индивидуальных характеристик как раз и вводятся ненаблюдаемые эффекты а,.. Проиллюстрируем возникновение указанного смещения на следующем примере.
ПРИМЕР 3.2.1
На рис. 3.4 представлено облако рассеяния точек (xin yit)9 порожденных моделью
У и = а( + fixit +иіп і = 1,2, t = 1,..., 100,
в которой ах = 150, а2 = 250, /3 = 0.6, uit ~ lid. N(09 102). Значения xit заданы (неслучайны); при / = 1 значения хи меньше 150, а при / = 2 значения x2t больше 150.
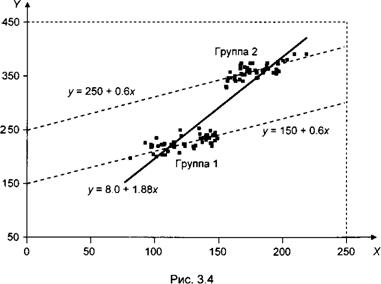
Облако точек распадается на две группы точек: в группе 1 объединяются точки, соответствующие / = 1, а в группе 2 — точки, соответствующие і = 2. Точки группы 1 располагаются вдоль (теоретической) прямой = 150 + О.бх (нижняя пунктирная линия на графике), точки группы 2 — вдоль (теоретической) прямой >> = 250 + О.бх.
Если по имеющимся 100 наблюдениям оценивать статистическую модель
у»=а + /3хи+щ9 / = 1,2, f = l,...,100, (пул),
не принимающую во внимание возможное наличие индивидуальных эффектов, то оцененная модель принимает вид:
U, =8.00 + 1.88*0.
Таким образом, оценка коэффициента J3 оказывается завышенной втрое по сравнению со значением, использованным при моделировании.
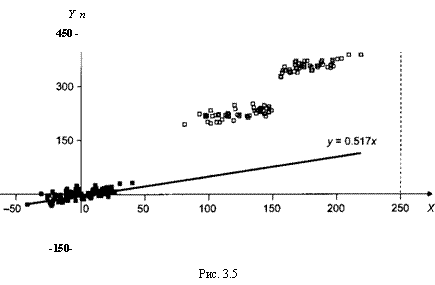 |
Оцененная модель в отклонениях от средних в группах имеет вид:
Л=0.517х„
и на этот раз оценка коэффициента Доказывается близкой к значению J3 = 0.6, использованному при моделировании.
Если оценивать модель с дамми-переменными
где с!у= 1, если j = /, и dtjг = 0 в противном случае, то получим результаты оценивания, приведенные в табл. 3.20.
 Полученные оценки ах =161.46, а2 =264.86, /3 = 0.517 близки к значениям параметров, использованным при моделировании. ■
Полученные оценки ах =161.46, а2 =264.86, /3 = 0.517 близки к значениям параметров, использованным при моделировании. ■
Случайные эффекты
Запишем модель
yit =at+j3xit+uin / = 1,...,7V, ґ = 1,...,Г, соответствующую гипотезе Нх, в равносильном виде:
N
где ^ а,. =0.
/=і
При таком условии at называют дифференциальными эффектами (differential effects). В ряде ситуаций N субъектов, для которых имеются статистические данные, рассматриваются как случайная выборка из некоторой более широкой совокупности (популяции), и исследователя интересуют не конкретные субъекты, попавшие в выборку, а обезличенные субъекты, имеющие заданные характеристики. Соответственно в таких ситуациях предполагается, что at являются случайными величинами, и тогда речь идет о модели
yit + +Pxit+uit
как о модели со случайными эффектами (random effects model). В такой модели at уже не интерпретируются как значения некоторых фиксированных параметров и не подлежат оцениванию. Вместо этого оцениваются параметры распределения случайных величин at.
Обозначив vit = at + uit, получим другую запись этой модели:
yit =fi + fixit + (а, + uit) = /л + 0хи + vit.
В такой форме модели ошибка vit состоит из двух компонент — at и uir Как и в модели с фиксированными эффектами, случайные эффекты аг также отражают наличие у субъектов исследования некоторых индивидуальных характеристик, не изменяющихся со временем в процессе наблюдений, которые трудно или даже невозможно наблюдать или измерить. Однако теперь значения этих характеристик встраиваются в состав случайной ошибки, как это делается в классической модели регрессии, в которой наличие случайных ошибок интерпретируется как недостаточность включенных в модель объясняющих переменных для полной интерпретации изменений объясняемой переменной.
К прежним предположениям о том, что
uit~U.d.N(0, <ти2), /=1, *=1,...,Г,
и что
E(xit uJS) = 0 для любых i,y= 1, N9 t,s=l,Г, добавим следующие предположения:
E(at) = О (так что и E(vit) = 0),
а2а9 если i = j9 E(aiaj) = a
[0, если і Ф j
(так что последовательность значений а,, aN представляет случайную выборку из распределения yV(0, сга2)),
E(xitaj) = 0, /,y = l,...,/V, Г= 1 Г
(так что E(xit vJs) = 0, и в модели со случайными ошибками vit переменная х является экзогенной).
Если предположить еще, что
E(uit at) = 0,
то условная относительно xit дисперсия случайной величины уи равна:
D(yitxit) = D(vit xit) = D(vit) = D(at + uit ) = cj2a+al
Таким образом, дисперсия yit складывается из двух некоррелированных компонент — их называют компонентами дисперсии (variance components). Саму модель называют
моделью компонент дисперсии (variance components model);
стандартной моделью со случайными эффектами (ЛЕ-модель —
random effects model)
В векторной форме эта модель имеет вид:
Уі = [єХі] S+vi9 где
| (Уп) | f1] | fx > | |||||
| Уп | , е = | 1 | , х,= | хп | "/2 | ||
| л | XiT ) |
Заметим, что
с/ ч г/ , ч Wl+vl* если Г = 5,
[ста9 если f
так что случайные величины vit и v/5 коррелированы, даже если не коррелиро-ваны ошибки uit9 и ковариационная матрица случайного вектора vt имеет вид:
V = E(vivJ) = cjllT+<jleeT
Например, при 7=3
2 2 2
V =
2 2 2
2 2
(ті + (ті
При этом
Corr(vit, vis) = а = /7 для всех Ґ Ф S (ТІ+(ТІ
(предположение равной коррелированное™ в модели компонент дисперсии).
Оценивание. В ЛЕ-модели оценка
N Т Pcv ~ N т
IK*.-*,)2
1 = 1 /=1
остается несмещенной и состоятельной оценкой для Д Однако она перестает быть эффективной оценкой (BLUE)9 как это было в модели с фиксированными эффектами, поскольку не учитывает коррелированность vit во времени для субъекта /.
Можно ожидать, что обобщенная оценка наименьших квадратов (GLS-оценка), учитывающая такую коррелированность, будет более эффективной. Заметим, что GL-S-оценка для 8 имеет вид:
 |
и что
где 4у =
1--1 Т
Чтобы не возникало путаницы с другими Є/^-оценками, для GLS-оценки в стандартной модели со случайными эффектами используется также обозначение (АЕ-оценка — random effect estimator). Заметим, что диагональные элементы матрицы V равны
1-¥
1-У
, а недиагональные элементы
равны
2 '
Та:
Практически /З^ можно получить следующим образом. Усредняя по t обе части уравнения
yit=H + PXit+vit>
получаем соотношение
y^fi + PXt+Vi.
Обозначив в = - произведем преобразование:
УІ=У*-0Уі> x't=Xit-0Xi9 УІ=Уії-вУі9 //=(1-0)//.
В результате получим преобразованную модель
с экзогенной переменной х*п в которой ковариационная матрица вектора ошибок v*t имеет вид:
Cov(vl) = <72uIT.
Поэтому применение OLS к преобразованной модели дает BLUE-оценку:
N Т
Pgls ~
i= t=
N Т
где
і N Т і NT
* 1 * _* 1 ^-п *
У в^11л. х = ^LIX7V/ / = 1 r = l , = 1 , = 1
Это выражение можно представить в виде: где
Г
Л=^-т .
£(*,-*)2
Ръ — «межгрупповая» оценка («между»-оценка — between estimator), соответствующая регрессии средних значений yi на константу и средние значения xi9 т.е.
(«модель для групповых средних»), и игнорирующая внутригрупповую изменчивость,
у£(*,-*)2
1 = 1
w = ,
7=1 Г=1 1=1
Таким образом, обобщенная оценка наименьших квадратов fiGLS в ^-модели учитывает и внутригрупповую, и межгрупповую изменчивость. Она является взвешенным средним «межгрупповой» оценки ръ (учитывающей
только межгрупповую изменчивость) и «внутригрупповой» оценки pcv (учитывающей только внутригрупповую изменчивость), a w измеряет вес, придаваемый межгрупповой изменчивости. При сделанных предположениях обе оценки — ръ и pcv — состоятельны, следовательно, состоятельна и сама PGLS.
Если Т -> оо, то 4х -> 0, w -> 0 и fiGLS -» Д-у, так что при больших Т оценки для Д получаемые в рамках моделей фиксированных и случайных эффектов, эквивалентны.
Если а2 -> 0, то ¥ 1 и V= E(vt vj) = а*Іт + cr2eeT -> <тм2/г. Соответственно при этом СІЗ'-оценка переходит в OLiS-оценку, т.е.
n т
Pgls ~* n т = Pols
ik*,-*)2
/=1 t=
(в пределе нет никаких эффектов). Заметим далее, что
D(Pgls )= ~й Т N *
1Х(**-*;)2+^1(*,-*)2
1 = 11 = /=1
В то же время
ik*.-*,)2
/=1 t=
Поскольку 4х > 0, из двух последних соотношений следует, что
D(pGLS)<D(pcv
т.е. GLS-оценка эффективнее. Она эффективнее оценки (3CV именно потому, что использует информацию как о внутригрупповой изменчивости, так и о межгрупповой изменчивости.
Чтобы реализовать эту GLS, т.е. получить доступную GLS-оценку (FGLS — feasible GLS, или EGLS — estimated GLS), надо подставить в выражения для 4х (и в) подходящие оценки для <тм2 и <тм2 + Гсга2.
Оценить <тм2 можно, используя внутригрупповые остатки (within residuals)
(Уіг-Уі)-Рсу(х»-хіі
которые получены при оценивании модели, скорректированной на индивидуальные средние:
іі[(л-л)-^(^-ї/)2]
£і _ /=і t=
N(T-)(в этой модели эффективное количество наблюдений равно N(T1) из-за наличия N линейных связей между уравнениями).
Оценить дисперсию <та2 случайных эффектов <та2 = D(at) можно, заметив, что при оценивании модели^ = ju + (3xt + vi9 приводящей к «межгрупповой» оценке т
-ч2
дисперсия остатка для і-й группы равна:
(Г2 г
Состоятельной оценкой для + аа является
D(yi-[ib-pbxi) = ^r + ai.
Т
1(й-А-А*,)2
/=1
N-2
Поэтому состоятельной оценкой для о а служит
*2=- ^
N-2 Т
/V-2
является состоятельной оценкой для <тм2 + 7сга2. Эти две оценки используют межгрупповые остатки. Они являются также оценками максимального правдоподобия соответствующих дисперсий.
Следует отметить, что — особенно при небольших значениях N и Т — значение вычисленной указанным образом оценки дисперсии сга2 может оказаться отрицательным.
Как было отмечено выше, J3GLS можно представить в виде:
так что /3GLS является линейной комбинацией «внутри»-оценки и «между»-оценки. Эта линейная комбинация оптимальна. Поэтому, например, оценка Pols* также являющаяся линейной комбинацией этих двух оценок (при Ш = 1), хотя и состоятельна, но менее эффективна.
Критерий Бройша — Пагана для индивидуальных эффектов
Данный критерий используется для проверки в рамках ЛЕ-модели (со стандартными предположениями) гипотезы
Я0: а2 О (сведение к модели пула).
Идея критерия основана на тождестве
N ( Т Л2 N Т N
Z Zw* =ZZw*+ZZw/A>
, = 1 yt=l J i=l t= i= s*t
из которого следует, что
N ( Т >2
1=1
i 2х
V'=i J
i і",л
/=1 s*t
-1=-
N T
N T
/=1 f=l
/=1 f=l
При отсутствии автокоррелированности случайных ошибок uit правая часть последнего равенства мала. Поэтому статистику критерия можно основывать на выражении, стоящем в левой части, в которое вместо ненаблюдаемых значений ии подставляются остатки йіп полученные при OLS-оценивании модели пула. Против гипотезы Н0 говорят «слишком большие» значения
п2
N ( Т ^
i i"»
N Т
ii»,?
,=1 г=1
-1
Статистика критерия Бройша — Пагана
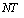 ВР = 2(Т-1)
ВР = 2(Т-1)
N ( Т 2 ii"»
N Т
ii"?
,■=1 г=1
-|2
NT
2(Г-1)
1 = 1
N Т
ii"?
/=1 t=
при гипотезе Н0 имеет асимптотическое распределение j2(l). Соответственно, гипотеза #0 отвергается, если наблюдаемое значение статистики BP превышает критическое значение, рассчитанное по распределению ^2(1).
Коэффициенты детерминации, разложение полной суммы квадратов
При анализе панельных данных возникают некоторые проблемы с определением коэффициента детерминации Л2. Так, во многих руководствах по эконометрике и монографиях, специально посвященных анализу панельных данных, вообще не упоминается о коэффициенте детерминации. В то же время в некоторых пакетах статистического анализа предусмотрено вычисление коэффициентов детерминации и для панельных данных.
Проблема с определением коэффициента детерминации в случае панельных данных связана с неопределенностью в отношении того, что считать полной суммой квадратов, подлежащей разложению на объясненную регрессией и остаточную суммы квадратов. Здесь имеем соотношение:
I N Т і N Т I N „ _ 7
—ТТ(уії-уг = —ТТ(уії-уі) +—Ц(уі-у)>
Л/І i=U= мі i=u=l TV /=1
и в качестве полной суммы квадратов может использоваться каждая из трех сумм квадратов, входящих в это выражение. Соответствующие этим полным суммам регрессионные модели объясняют:
отклонения наблюдаемых значений yit от их среднего по всем NT наблюдениям;
отклонения наблюдаемых значений yit в группах от их средних по группе;
отклонения средних по группам от среднего по всем NT наблюдениям.
Если используем оценку пул, то она получается в результате применения метода наименьших квадратов к уравнению
yit = a + fixit+uit, / = 1,...,ЛГ, / = 1,...,Г.
При этом коэффициент детерминации равен квадрату (выборочного) коэффициента корреляции между переменными уи и
Уіг=а + Р01$хіп
где pOLS — О/^-оценка коэффициента /?в модели пула.
Об этом коэффициенте детерминации говорят как о Л2-полном (R2-overall):
RLraii = corr2(yin a + /3OLS xit) = corr2(yin J3OLS xit).
Если используем оценку «между», то она получается в результате применения метода наименьших квадратов к уравнению
у{ = ju + Дх, i = l,...,N.
При этом коэффициент детерминации равен квадрату (выборочного) коэффициента корреляции между переменными^ и
где Д — «между»-оценка для коэффициента Д.
Об этом коэффициенте детерминации говорят как о /?2-между (R2-between)
Rbetween = COrr2(jU + Д Xt, У і ) = СОГГ2(Рь X(, Jt).
Если используем оценку «внутри», то она получается в результате применения метода наименьших квадратов к уравнению
У и ~ У і = Р(х* -*,■) + (ии -Щ i = l,...,N9 t = 1,..., Т.
В правой части последнего уравнению отсутствует константа. А при OLS-оценивании уравнений вида zt = J3w{ + v, коэффициент детерминации в общем случае не равен квадрату выборочного коэффициента корреляции между переменными = fiwi и zt. Однако если переменные zt и wt центрированы, так что z = w = О, то такое равенство обеспечивается. В нашем случае переменные yit у і и xit xt центрированы, так что коэффициент детерминации, получаемый при оценивании уравнения в отклонениях от средних по группам равен квадрату (выборочного) коэффициента корреляции между переменными yit = yit yt и
Уп = Pcv (хп -*/)> / = 1,^ t = 1,Г, где pcv — «внутри»-оценка для коэффициента Д.
Об этом коэффициенте детерминации говорят как о Л2-внутри» (R2-within)
Rlmn = corr2CPCv (xit "*/)> У it У і)'
Каждый из этих 3 вариантов R2 является обычным коэффициентом детерминации в соответствующей модели регрессии. В то же время при анализе различных моделей панельных данных часто сообщаются вычисленные значения всех 3 вариантов Л2, несмотря на то что в модели с фиксированными
эффектами используется оценка Ду, в модели со случайными эффектами —
оценка flGLS, а в модели пула — оценка PolsБолее точно, при анализе панельных данных под названиями Л2 Шп9 R2between, Roverall принято сообщать значения:
Rlithin=c°rr2(yit -уі9Р(Хь -*,)),
R2bet»een=COrr2(yi,pii)9 RLrall=C°rr2(yinPxit)
независимо от того, каким образом была получена оценка Д Если /? является /7-мерным вектором, то соответственно:
Каш =corryit -уі9Р(хи -xt)T)9
Ке^ееп=согг2(уі9РхІ), Kverall=COrrl(yit>PXl)При этом:
приводимое значение R2within является коэффициентом детерминации в обычном смысле, если Р = J3within
приводимое значение Retween является коэффициентом детерминации в обычном смысле, если р = Pbetween;
приводимое значение R2overau является коэффициентом детерминации в обычном смысле, если Р POLS.
ПРИМЕР 3.2.2
Проверка значимости регрессии в целом:
F(l,26) = 472.26, Prob >F = 0.0000.
 |
Оценивание модели с фиксированными эффектами для 3 предприятий
 Оцененное значение коэффициента корреляции между индивидуальным эффектом и предсказанием Corr(a_i, Xb) = -0.2311. Остальная часть протокола оценивания приведена в табл. 3.22.
Оцененное значение коэффициента корреляции между индивидуальным эффектом и предсказанием Corr(a_i, Xb) = -0.2311. Остальная часть протокола оценивания приведена в табл. 3.22.
Критерий в последней строке соответствует гипотезе с двумя линейными ограничениями: поскольку в модель включена постоянная составляющая, одно линейное ограничение накладывается заранее как идентифицирующее и не подлежащее проверке.
Таблица 3.23
Random-effects GLS regression
R-SQ:
within = 0.9478 between = 0.8567 overall = 0.9209
Random effects: и J ~ Gaussian
corr(a_i, X) = 0 (предполагается)
Критерий значимости регрессии в целом:
Waldchi2() = 325.94, Prob > chil = 0.0000
sigmajxlfa 0
sigmaju 1.7451362
rho 0 {fraction of variance due to a J)
Здесь полученная оценка для а2 оказалась отрицательной, поэтому ее значение полагается равным нулю. Однако тогда модель со случайными эффектами редуцируется к модели пула (табл. 3.24).
 В то же время если в рамках модели со случайными эффектами применить критерий Бройша — Пагана для проверки гипотезы об отсутствии таковых эффектов, т.е. гипотезы Н0: а* = 0, то полученное значение статистики критерия равно 8.47. Этому значению соответствует рассчитанное по асимптотическому распределению хи-квадрат с 1 степенью свободы Р-значение 0.0036. Но это говорит против гипотезы Я0. И опять это можно объяснить малым количеством наблюдений — ведь распределение хи-квадрат здесь только асимптотическое.
В то же время если в рамках модели со случайными эффектами применить критерий Бройша — Пагана для проверки гипотезы об отсутствии таковых эффектов, т.е. гипотезы Н0: а* = 0, то полученное значение статистики критерия равно 8.47. Этому значению соответствует рассчитанное по асимптотическому распределению хи-квадрат с 1 степенью свободы Р-значение 0.0036. Но это говорит против гипотезы Я0. И опять это можно объяснить малым количеством наблюдений — ведь распределение хи-квадрат здесь только асимптотическое.
 В пакете Stata 8 есть возможность оценить модель со случайными эффектами, не прибегая к С/^-оцениванию, а используя метод максимального правдоподобия. Это дает результаты, указанные в табл. 3.25. По критерию отношения правдоподобий гипотеза Я0: а* = 0 отвергается.
В пакете Stata 8 есть возможность оценить модель со случайными эффектами, не прибегая к С/^-оцениванию, а используя метод максимального правдоподобия. Это дает результаты, указанные в табл. 3.25. По критерию отношения правдоподобий гипотеза Я0: а* = 0 отвергается.
При оценивании 6еЛі>ееи-регрессии (табл. 3.26) она оказывается статистически незначимой, а близкое к 1 значение коэффициента детерминации ^between не Должно вводить в заблуждение: для оценивания двух коэффициентов имеется всего 3 наблюдения. ■
 Выбор между моделями с фиксированными или случайными эффектами
Выбор между моделями с фиксированными или случайными эффектами
Прежде всего напомним отмеченные ранее особенности моделей с фиксированными или случайными эффектами.
fe: получаемые выводы —условные по отношению к значениям эффектов а{ в выборке. Это соответствует ситуациям, когда эти значения нельзя рассматривать как случайную выборку из некоторой более широкой совокупности (популяции). Такая интерпретация наиболее подходит для случаев, когда субъектами исследования являются страны, крупные компании или предприятия, т.е. каждый субъект «имеет свое лицо».
re: получаемые выводы — безусловные относительно совокупности всех эффектов at. Исследователя не интересуют конкретные субъекты в выборке — для него это обезличенные субъекты, выбранные случайным образом из более широкой совокупности (так что набор аи а2,aN9 трактуется как случайная выборка из некоторого распределения).
Заметим в связи с этим, что:
в ^-модели E(yit | xit) = E(at + J3xit + uit xit ) = ai+ J3xit; в ЛЕ-модели E(yit I xit) = E(ju + at + J3xit + uit xit ) = ju + 0xir
Напомним, что ЛЕ-модель предполагает, в частности, что E(ai xit) = 0. Чтобы избавиться от этого условия ортогональности, предположим, что
a t =axt+ si, є і 7V(0, а), E(st єи) = 0.
Это приводит к модели Мундлака (Mundlak model): У и =М + Pxit + axt + et + uit9
она также является моделью компонент ошибки, но отличается от предыдущей модели тем, что в правую часть добавляется переменная xi9 которая изменяется только от субъекта к субъекту и отражает неоднородность субъектов. Эта переменная в отличие от ai наблюдаема. Заметим, что в модели Мундлака
Е(аі xit ) = Е((а xt + ei )xit) = aE( xt xit) =
T ( T ^
= f Z E)=■£■£(*#)+ Z E)»
* 5 = 1 * S = ,S*t ;
так что если а Ф О, то условие E(at xit) = О в общем случае не выполняется
ни для одного / = 1, ..., N.
Применение GLS к этой модели дает BLUE-оценш для /?и а:
PdS ~ Pcv 9 aGLS Pb ~ Pcv 9
и
M*GLS=y-xPb'
Иначе говоря, 5/,£/Е-оценкой для /? в этой модели является ковариационная (внутригрупповая) оценка, и из E(aGLS) = а9 E(aGLS) = E(Pb) E(J3CV) и E(PCV) = Р получаем:
Как было показано выше, в /?Е-модели (предполагающей выполнение условия E(atxit) = 0)
Рке=™&+(1-™)Рсу-Если использовать эту же оценку в модели Мундлака, то для нее получим:
E(PRE) = wE(Pb) + (1 w)E(pcv ) = w(P + a) + (l-w)P = P + w*,
так что если а Ф 0, то PRE — смещенная оценка.
Критерии спецификации
Речь здесь идет о том, совпадает или нет условное распределение а( при заданном х( с безусловным распределением at. Если не совпадает — наилучшей оценкой является pcv (FE)9 если совпадает — наилучшей оценкой является pGLS (RE).
Критерий 1. Используя формулировку Мундлака, проверяем гипотезу Я0: а = О против альтернативы Нх: а ф 0.
Критерий 2 — критерий Хаусмана (Hausmari). Проверяемая гипотеза: Я0: E(atxit) 0, альтернативная гипотеза: Нх: Да,!*,,) ф 0.
Идея критерия 2 основывается на следующих фактах:
при гипотезе Я0 и оценка PGLS, соответствующая ЯЕ-модели, и оценка Pcv, соответствующая FE-модели, состоятельны;
при гипотезе Я, оценка /?GLS несостоятельна, а оценка /?сг состоятельна.
Соответственно если гипотеза Я0 верна, то между оценками (3GLS и J3CV не должно наблюдаться систематического расхождения, и эта гипотеза должна отвергаться при «слишком больших» по абсолютной величине значениях
разности pcv PGLS (больших — в сравнении со стандартной ошибкой этой разности).
Пусть q = pcv PGLS, тогда из общей формулы для дисперсии суммы двух случайных величин следует:
D{q) = D(pcv -Pgls) = D(pcv) + D(pGLS)-2Cov(/3cv, PGLS).
Если выполняются предположения стандартной ЛЕ-модели, то, как было указано выше, /3GLS является эффективной оценкой, a J3CV — неэффективной. Хаусман показал, что эффективная оценка не коррелирована с разностью ее и неэффективной оценки, так что если гипотеза Я0 верна, то
CovCPgls, Pgls -Pcv) = D(PGLS)-Cov(PGLS, Pcv) = 0,
Cov(PGLSJcv) = D(PGLS),
и
D{q) = D{Pcv)-D{PGLS). Как уже говорилось выше,
2
NT N '
I !(*,-,-^o^Ic*,-*)2
WcK) = ir-r^ •
x2>,-,-*,)2
/=1 t=
Заменив в этих выражениях неизвестные параметры их состоятельными
оценками, указанными ранее, получим состоятельную оценку D(q) для D(q). Статистика критерия Хаусмана
имеет при гипотезе #0 асимптотическое (N-> оо) распределение ^2(1). Для К регрессоров при гипотезе #0 статистика
m = qT[Cov(q)]'lq
имеет асимптотическое распределение \%2(К).
Численно идентичный критерий для проверки гипотезы #0 получается при использовании расширенной модели регрессии
где yit =yit -вуі9 x]t =хії-Єхі9
2
Гипотеза Я0 означает в этой регрессии, что у = 0. Можно показать, что здесь
Pols ~Ръ-> Yols ~Pcv ~РьГипотезу Н0 можно также проверить, используя любую из следующих разностей:
Я = Pgls "Pcv* Ч2 ~Pgls ~~Ръ* Ъ =Pcv-Pb> Ча ~ Pgls ~ PolsЭто вытекает из соотношения
0GLS=W0bHl-w)0CV
yf Замечание 3.2.1. Все входящие в эти разности оценки параметра J3 состоятельны при гипотезе Я0, поэтому все эти разности при гипотезе Н0 должны сходиться к нулю.
 Здесь Ъ = J3CV, В = fiGLS9 (b-B) = q= J3CV (3GLS. Статистика критерия Хаусмана равна:
Здесь Ъ = J3CV, В = fiGLS9 (b-B) = q= J3CV (3GLS. Статистика критерия Хаусмана равна:
chi2() = (bB)(VJ V_B)A(-l)](b -В) = -2.15,
где V_b и VJB— состоятельные оценки дисперсий оценок Pcv и J3GLS, соответственно.
Поскольку значение этой статистики оказалось отрицательным, критерий Хаусмана применить не удается.■
ПРИМЕР 3.2.3 (размер заработной платы)
Статистические данные (из National Longitudinal Survey, Youth Sample, США) содержат сведения о 545 полностью занятых мужчинах, которые окончили школу до 1980 г. и за которыми велось наблюдение в течение 1980—1987 гг. В 1980 г. эти мужчины были в возрасте от 17 до 23 лет и включились в рынок труда совсем недавно, так что на начало периода их трудовой стаж составлял в среднем около 3 лет. Логарифмы среднечасовой заработной платы (WAGEJLN) зависят здесь от длительности школьного обучения (SCHOOL), трудового стажа (EXPER) и его же в квадрате (EXPER2), а также от дамми-переменных, указывающих на членство в профсоюзе (UNION), работу в государственном секторе (PUB), семейный статус (состоит ли в браке — MAR), а также на цвет кожи (чернокожий или нет — BLACK) и испаноязычность (HISP).
 Результаты оценивания в пакете Stata8 приведены в табл. 3.28 (в скобках указаны значения /-статистики (или z-статистики) для проверки равенства соответствующего коэффициента нулю).
Результаты оценивания в пакете Stata8 приведены в табл. 3.28 (в скобках указаны значения /-статистики (или z-статистики) для проверки равенства соответствующего коэффициента нулю).
Результаты применения критерия Хаусмана
 Если выполнены предположения модели со случайными эффектами, то все четыре оценки состоятельны (если, конечно, объясняющие переменные не коррелированы с ошибкой), и при этом ЛЕ-оценка имеет наибольшую эффективность. Если, однако, индивидуальные эффекты at коррелированы хотя бы с одной из объясняющих переменных, то состоятельной остается только F^-оценка. Поэтому встает вопрос о проверке гипотезы Я0 о том, что модель является ЛЕ-моделью. Для этого можно сравнивать оценки «внутри» (FE) и «между» или оценки «внутри» (FE) и RE (соответствующие критерии равносильны). Проще сравнивать вторую пару, используя критерий Хаусмана (табл. 3.29), описанный ранее.
Если выполнены предположения модели со случайными эффектами, то все четыре оценки состоятельны (если, конечно, объясняющие переменные не коррелированы с ошибкой), и при этом ЛЕ-оценка имеет наибольшую эффективность. Если, однако, индивидуальные эффекты at коррелированы хотя бы с одной из объясняющих переменных, то состоятельной остается только F^-оценка. Поэтому встает вопрос о проверке гипотезы Я0 о том, что модель является ЛЕ-моделью. Для этого можно сравнивать оценки «внутри» (FE) и «между» или оценки «внутри» (FE) и RE (соответствующие критерии равносильны). Проще сравнивать вторую пару, используя критерий Хаусмана (табл. 3.29), описанный ранее.
Вычисленное значение статистики критерия (табл. 3.29) равно 31.75 и отражает различия в FEи ЛЕ-оценках коэффициентов при 5 переменных: EXPER, EXPER2, UNION, MAR, PUB. Для распределения j2(5) значение 31.75 соответствует Р-значению 6.6 • 10~6, так что нулевая гипотеза (ЛЕ-модель) заведомо отвергается. ■
Автокоррелированные ошибки
Во всех рассмотренных выше ситуациях предполагалось, что случайные составляющие uit — взаимно независимые случайные величины, имеющие одинаковое распределение N(0, сгм2). Между тем вполне возможно, что для /-го субъекта последовательные ошибки uil9 иа, иІТ не являются независимыми, а следуют, скажем, стационарному процессу авторегрессии первого порядка с нулевым средним.
Точнее говоря, пусть имеем дело с моделью
yit = + +/3xit+uin / = 1,...,#, f = 1,...,Г,
в которой
ult=pui,t-l+eit>
где р\<1;
єі-> єі29 єіт — случайные величины, являющиеся гауссовскими инновациями, так что они взаимно независимы и имеют одинаковое распределение N(0, а2) и, кроме того, sit не зависит от значений uit_k, к>.
Общий для всех субъектов коэффициент р можно оценить различными способами. При этом в большинстве случаев сначала переходят к модели, скорректированной на групповые средние:
У и-Уі=Р(хи-Хі) + (Міі-Щ)>
т.е.
а затем поступают по-разному.
Можно, например, оценить (методом наименьших квадратов) последнюю модель без учета автокоррелированности ошибок, получить последовательность
остатков ип, ип,..., иІТ, вычислить значение статистики Дарбина — Уотсона
і /=1t=2
d = N-^rz
IK
i= t=
и, используя приближенное соотношение р = 1 d/29 получить оценку pDW = zl-d/2.
Можно поступить иначе: получив последовательность остатков іїп,їїі2,...,їїІТ, использовать оценку наименьших квадратов, получаемую при оценивании уравнения регрессии
Искомая оценка вычисляется по формуле:
Рtscorr ~~ NT i=l t=
После получения оценки для р производится преобразование переменных для получения модели с независимыми ошибками. Наконец, в рамках преобразованной модели производится обычный анализ на фиксированные или случайные эффекты.
ПРИМЕР 3.2.4
В примере с тремя предприятиями для модели с фиксированными эффектами получаем (в пакете Statd) следующие результаты:
 при использовании ZW-оценки — результаты, приведенные в табл. 3.30. Оценка коэффициента /? по сравнению со значением 1.102192, полученным ранее без учета возможной автокоррелированности ошибок, практически не изменилась. И это согласуется со значением статистики Дарбина — Уотсона. Вывод об отсутствии индивидуальных эффектов также не изменяется;
при использовании ZW-оценки — результаты, приведенные в табл. 3.30. Оценка коэффициента /? по сравнению со значением 1.102192, полученным ранее без учета возможной автокоррелированности ошибок, практически не изменилась. И это согласуется со значением статистики Дарбина — Уотсона. Вывод об отсутствии индивидуальных эффектов также не изменяется;
при использовании tecorr-оценки — результаты, приведенные в табл. 3.31. Оцененное значение коэффициента автокорреляции р на этот раз почти в 2 раза меньше. Оценка коэффициента /? практически не изменилась. ■

КОНТРОЛЬНЫЕ ВОПРОСЫ
В каких ситуациях для анализа панельных данных используется модель с фиксированными эффектами? Как оценивается такая модель? Каковы свойства получаемых оценок?
В каких ситуациях для анализа панельных данных используется модель со случайными эффектами? Как оценивается такая модель? Каковы свойства получаемых оценок?
Каким образом производится выбор между моделями с фиксированными и случайными эффектами? Какие соображения лежат в основе построения критерия Хаусмана?
Каковы особенности модели Мундлака? Как оценивается такая модель?
Каковы особенности анализа панельных данных в случае автокоррелированности случайных ошибок?
Какие варианты коэффициента детерминации используются при анализе панельных данных?

Обсуждение Эконометрика Книга вторая Часть 3
Комментарии, рецензии и отзывы