Лекция № 16. модели бинарного выбора. метод максимума правдоподобия
Лекция № 16. модели бинарного выбора. метод максимума правдоподобия
В нормальной линейной регрессионной модели вида:
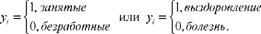
Рассмотренные бинарные переменные являются величинами дискретными. Бинарная непрерывная величина задается как:
зависимая переменная y является непрерывной величиной, которая может принимать любые значения. Существуют регрессионные зависимости, в которых переменная y должна принимать определенный узкий круг заранее заданных значений. Эти зависимости называются моделями бинарного выбора. Примерами такой переменной могут служить:
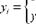
Прогнозные значения y !>Рогтз будут выходить за пределы интервала [0; +1], поэтому их нельзя будет интерпретировать.
Задачу регрессии можно сформулировать не как предсказание конкретных значений бинарной переменной, а как предсказание непрерывной переменной, значения которой заключаются в интервале [0; +1].
Для аппроксимации данной регрессионной зависимости необходимо подобрать кривую, которая отвечала бы следующим свойствам: Д—оо) = 0; Д+оо) = 1; при х1 > х2 — F(x1) > F(x2).
Указанным свойствам удовлетворяет функция распределения вероятности. С помощью данной функции парную регрессионную модель с зависимой бинарной переменной можно представить в виде:
prob (yі =1) = F (в, +в^,),
где prob(y. = 1) — это вероятность того, что зависимая переменная у;.примет значение, равное единице.
Достоинством применения функции распределения вероятности является то, что прогнозные значения упрогно3 будут лежать в пределах интервала [0; +1].
Модель бинарного выбора можно записать через скрытую (латентную) переменную:
yi* = Л + А х1і + --+ ЛХИ + ЄІ или в векторном виде:
y* = xT в + Єі,
где зависимая бинарная переменная yi принимает следующие значения в зависимости от латентной у/:
їй, У< 0.
Если предположить, что остатки регрессионной модели бинарного выбора єі являются случайными нормально распределенными величинами, а функция распределения вероятностей является нормальной вероятностной функцией, то модель бинарного выбора будет называться пробит-моделью или про-бит-регрессией (probit regression).
Пробит-регрессия может быть выражена уравнением вида:
NP (yt ) = NP (в +e1xb +^ + ekxki),
где NP — это нормальная вероятность (normal probability).
Если же предположить, что случайные остатки єі подчиняются логистическому закону распределения, то модель бинарного выбора называется логит-моделью или логит-регрессией (logit regression).
Логит-регрессию можно записать с помощью следующего уравнения:
Уі (1 + exp (в +e1xn+ ^
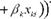
_ exp +e1xn +.-. + ekxki )
Основное достоинство данного уравнения заключается в том, что при любых значениях факторных переменных и регрессионных коэффициентов значения зависимой переменной yi будут всегда лежать в интервале [0; +1].
Помимо рассмотренной логит-модели, существует также обобщенная логит-модель, которая может выражаться уравнением: ' 1 + Д хехр (j32 x x.)'
которая позволяет зависимой переменной произвольно меняться внутри фиксированного интервала (не только [0; +1]).
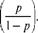
Логит модель может быть сведена к линейной с помощью преобразования, носящего название логистического, или логит-преобразования, которое можно записать на примере преобразования обычной вероятности p:
Р = loge
Показателем качества построенной пробитили логит-регрес-сии является псевдокоэффициент детерминации:
2 1
psevdoR =1 т г-.
У 1 + 2(/і Ч )
N
Если его значение близко к единице, то модель считается адекватной реальным данным.
Метод максимума правдоподобия.
Термин «метод максимума правдоподобия» (maximum likelihood function) был впервые использован в работе Р. А. Фишера в 1922 г.
Этот метод — альтернатива методу наименьших квадратов и со стоит в максимизации функции правдоподобия или ее логарифма. Общий вид функции правдоподобия:
L (X, в)=П{Р (У., X )}
;=1
где — это геометрическая сумма, означающая перемножение вероятностей по всем возможным случаям внутри скобок. Построена регрессионная модель бинарного выбора, где зависимая переменная представлена через скрытую (латентную) переменную:
У' |0, у* < 0,
где у* = xTв+єі.
Вероятность того, что переменная yi примет значение единицы, можно выразить следующим образом:
Р(Уі = 1) = Р(Уі* > 0)= p(xT0 + e> 0) = p(e<-x[0) = F (xT0).
Вероятность того, что переменная yi примет значение нуль, будет равно:
Р (у = 0)=1-F (xT 0).
Для вероятностей выполняется следующее равенство:
p (yi = 1, У2 = 0 )= p (yi = 1 )x p = 0 ).
С учетом данного равенства функцию правдоподобия можно записать как геометрическую сумму вероятностей наблюдений:
L(0, X)= p(yi =1, У2 = 0...)= ПF(xT0)П(1-F(xt0))
Функция правдоподобия для регрессионных логити пробит-моделей строится через сумму натуральных логарифмов правдоподобия:
l (0, X )= In L (0, X )= 2 In F (xT 0) + 2 In (1 F (xT 0))
Для нахождения оценок неизвестных коэффициентов логит-и пробит-регрессии метод наименьших квадратов применять не оптимально. Оценки 0определяются с помощью максимизации функции правдоподобия для логити пробит-регрессий:
l (0, X )—0-^max.
Для нахождения максимума функции l (0, X) вычислим частные производные по каждому из оцениваемых параметров и приравняем их к нулю:
(4=0,
301
4=0,
■ 302
4=0.
Путем преобразований исходной системы уравнений находим стационарную систему уравнений, а затем систему нормальных уравнений.
Решениями системы нормальных уравнений будут оценки максимального правдоподобия fiML.
Проверка значимости вычисленных коэффициентов пробити логит-регрессии и уравнения регрессии определяется с помощью величины (/1 — /0), где /1 соответствует максимально правдоподобной оценке основного уравнения регрессии; /0 — оценка нулевой модели регрессии, т. е. yi = в0.
Выдвигается основная гипотеза о незначимости коэффициентов пробитили логит-регрессии:
Ho/ ві = вг = = 0к = 0.
Для проверки гипотезы вычисляется величина H = — 2 (/1 — /0), которая подчиняется распределению с k степенями свободы.
Величина H сравнивается с критическим значением ^-критерия, которое зависит от заданного значения вероятности а и степени свободы k.
Если H> х2, то основная гипотеза отвергается, коэффициенты регрессионной зависимости являются значимыми, следовательно, значимым является само уравнение логитили пробит-ре-грессии.
Пусть о — это элемент, принадлежащий заданному пространству A. Если A является открытым интервалом, а функция L(o) дифференцируема и достигает максимума в заданном интервале A, то оценки максимального правдоподобия удовлетворяют равенству
Що>) = 0
до
Докажем высказанное утверждение на примере логит-регрессии.
Функция максимального правдоподобия для логит-модели имеет вид:
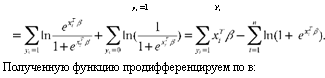 |
l (в, X) = ln L( в, X) = 2> F (xT в) + F( xT в))
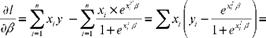
= 2 х( yt p) = 0.
Утверждение доказано.
Если регрессионная модель удовлетворяет предпосылкам нормальной линейной регрессионной модели, то оценки коэффициентов, полученные с помощью метода наименьших квадратов, и оценки, полученные с помощью метода максимума правдоподобия, будут одинаковыми.
Термин «гетероскедастичность» в широком смысле означает предположение о дисперсии случайных ошибок регрессионной модели. Случайная ошибка — отклонение в модели линейной множественной регрессии:
Величина случайной регрессионной ошибки является неизвестной, поэтому вычисляется выборочная оценка случайной ошибки регрессионной модели по формуле:
ei = yi -yi = у -00 -0ixik ---0nxik,
где e — остатки регрессионной модели.
Нормальная линейная регрессионная модель строится на основании следующих предпосылок о случайной ошибке:
математическое ожидание случайной ошибки уравнения регрессии равно нулю во всех наблюдениях: е(є;.) = 0, где
i = 1, n;
дисперсия случайной ошибки уравнения регрессии является постоянной для всех наблюдений:/)^.) = E(e?) = G 2 =const;
случайные ошибки уравнения регрессии не коррелированы между собой, т. е. ковариация случайных ошибок любых двух разных наблюдений равна нулю: Cov(e,, є}) = Е(єр єр = 0, где i ^ j. Условие D(£) = Е(є2) = G 2 = const трактуется как гомоскедастичность (homoscedasticity — «однородный разброс») дисперсий случайных ошибок регрессионной модели. Гомоскедастич-ность — это предположение о том, что дисперсия случайной ошибки єі является известной постоянной величиной для всех i наблюдений регрессионной модели.
На практике предположение о гомоскедастичности случайной ошибки єі или остатков регрессионной модели ei далеко не всегда оказывается верным.
ЛЕКЦИЯ № 17. Гетероскедастичность остатков регрессионной модели. Обнаружение и устранение гетероскедастичности
Предположение о том, что дисперсии случайных ошибок являются разными величинами для всех наблюдений, называется гетероскедастичностью (heteroscedasticity — неоднородный разброс):
Щє) * Б(є}) * G2 * const,
где i * j.
0 0
Условие гетероскедастичности можно записать через ковариационную матрицу случайных ошибок регрессионной модели:
0 ... 0 ' G22 ... 0
0 ... G,
где G^*G22* ... *Gn2.
Тогда є( подчиняется нормальному закону распределения с параметрами: є( — N (0;G 2 Q ), где Q — матрица ковариаций случайной ошибки.
Наличие гетероскедастичности в регрессионной модели может привести к негативным последствиям:
оценки уравнения нормальной линейной регрессии остаются несмещенными и состоятельными, но при этом теряется эффективность;
появляется большая вероятность того, что оценки стандартных ошибок коэффициентов регрессионной модели будут рассчитаны неверно, что конечном итоге может привести к утверждению неверной гипотезы о значимости регрессионных коэффициентов и значимости уравнения регрессии в целом. Если дисперсии случайных ошибок регрессионной модели G?
известны заранее, то от проблемы гетероскедастичности можно было бы легко избавится. Но на практике, как правило, неизвестна даже точная функция зависимости y = fx) между изучаемыми переменными, которую предстоит построить и оценить. Чтобы в подобранной регрессионной модели обнаружить гетероске-дастичность, необходимо провести анализ остатков регрессионной модели. Проверяются следующие гипотезы.
Основная гипотеза H0, утверждающая о постоянстве дисперсий случайных ошибок регрессии, т. е. о присутствии в модели условия гомоскедастичности:
Альтернативной гипотезой H1 является предположение о неодинаковых дисперсиях случайных ошибок в различных наблюдениях, т. е. о присутствии в модели условия гетероскедастичности:
H0/G12 *G2 *...*GB2.

Обсуждение Эконометрика.Конспект лекций
Комментарии, рецензии и отзывы