7.4. тесты на гетероскедастичность
7.4. тесты на гетероскедастичность
В примере, рассмотренном в § 7.3, наличие гетероскедастич-ности не вызывает сомнения, — чтобы убедиться в этом, достаточно взглянуть на рис. 7.1. Однако в некоторых случаях гетеро-скедастичность визуально не столь очевидна.
Рассмотрим еще один пример, в котором исследуется зависимость дохода индивидуума (У) от уровня его образования Х, принимающего значения от 1 до 5, по данным п = 150 наблюдений. В число объясняющих переменных (регрессоров) включен также и возраст Х2.
На рис. 7.2 приведен график зависимости переменной Y от номеров наблюдений, упорядоченных по возрастанию уровня значений объясняющей переменной Х.
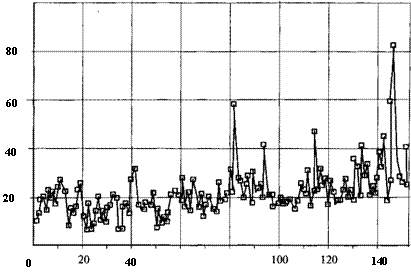 Хотя диаграмма имеет локально расположенные пики, в целом подобный рисунок может соответствовать как гомо-, так и гетероскедастичной выборке.
Хотя диаграмма имеет локально расположенные пики, в целом подобный рисунок может соответствовать как гомо-, так и гетероскедастичной выборке.
60 80 Рис. 7.2
Чтобы определить, какая же именно ситуация имеет место, используются тесты на гетероскедастичность. Все они используют в качестве нулевой гипотезы Щ гипотезу об отсутствии гетероскедастичности.
Тест ранговой корреляции Спирмена использует наиболее общие предположения о зависимости дисперсий ошибок регрессии от значений регрессоров:
1,..., п.
При этом никаких дополнительных предположений относительно вида функций fi не делается. Не накладываются также ограничения на закон распределения возмущений (ошибок) регрессии Є/.
Идея теста заключается в том, что абсолютные величины остатков регрессии в являются оценками а,, поэтому в случае ге-тероскедастичности абсолютные величины остатков в и значения регрессоров х будут коррелированы.
Для нахождения коэффициента ранговой корреляции рхе
(см. § 3.8) следует ранжировать наблюдения по значениям переменной X/ и остатков и вычислить рх е по формуле (3.49):
at*?
px,e=l--JzL—, (7.17) п5 -п
где dt — разность между рангами значений X/ и е,-.
В соответствии с (3.50) коэффициент ранговой корреляции значим на уровне значимости а при п > 10, если статистика
и рхел1п-2
И = /Г , ><W <7Л8>
Vі ~Рх,е
где tx_a.n_2 — табличное значение /-критерия Стьюдента, определенное на уровне значимости а при числе степеней свободы (лі—2).
Тест Голдфелда—Квандта. Этот тест применяется в том случае, если ошибки регрессии можно считать нормально распределенными случайными величинами.
Предположим, что средние квадратические (стандартные) отклонения возмущений пропорциональны значениям объясняющей переменной X (это означает постоянство часто встречающегося на практике относительного (а не абсолютного, как в классической модели) разброса возмущений є,регрессионной модели.
Упорядочим п наблюдений в порядке возрастания значений регрессора Хи выберем т первых и т последних наблюдений.
В этом случае гипотеза о гомоскедастичности будет равносильна тому, что значения е,...9 ет и еп-т+9...9 еп (т. е. остатки et регрессии первых и последних т наблюдений) представляют собой выборочные наблюдения нормально распределенных случайных величин, имеющих одинаковые дисперсии.
Гипотеза о равенстве дисперсий двух нормально распределенных совокупностей, как известно (см., например, [12]), проверяется с помощью критерия Фишера—Снедекора.
Нулевая гипотеза о равенстве дисперсий двух наборов по т наблюдений (т. е. гипотеза об отсутствии гетероскедастичности) отвергается, если
т
F = п ^ ^а;т-р;т-р ? (71^)
2>,2
i-n-m+
где р — число регрессоров.
Заметим, что числитель и знаменатель в выражении (7.19) следовало разделить на соответствующее число степеней свободы, но в данном случае эти числа одинаковы и равны (т — р).
Мощность теста, т. е. вероятность отвергнуть гипотезу об отсутствии гетероскедастичности, когда действительно гетероскедастичности нет, оказывается максимальной, если выбирать т порядка я/3.
При применении теста Голдфелда—Квандта на компьютере нет необходимости вычислять значение статистики F вручную, так как
т т
величины Y^ef и Zl^ представляют собой суммы квадратов
/=1 i=n-m+
остатков регрессии, осуществленных по «урезанным» выборкам.
► Пример 7.1. По данным п = 150 наблюдений о доходе индивидуума Y (рис. 7.2), уровне его образования Х и возрасте Хі выяснить, можно ли считать на уровне значимости а=0,05 линейную регрессионную модель Y по Х и Хі гетероскедастичной.
Решение. Возьмем по т=п/3=150/3=50 значений доходов лиц с наименьшим и наибольшим уровнем образования Х.
Вычислим суммы квадратов остатков (само уравнение регрессии (7.22) приведено ниже)1:
150 150
2>?= 894,1; =3918,2; /=3918,2/894,1=4,38.
1 Здесь и далее (если не приведено иное) исходные значения переменных и выполненные на их основе компьютерной программой стандартные расчеты, изложенные в гл. 3,4, не приводятся.
/=1 /=101
Так Как В СООТВетСТВИИ С (7.19) /Г=4,38>/го,05;48;48 =1,61, то
гипотеза об отсутствии гетероскедастичности регрессионной модели отвергается, т. е. доходы более образованных людей действительно имеют существенно большую вариацию. ►
Тест Уайта. Тест ранговой корреляции Спирмена и тест Голдфелда—Квандта позволяют обнаружить лишь само наличие гетероскедастичности, но они не дают возможности проследить количественный характер зависимости дисперсий ошибок регрессии от значений регрессоров и, следовательно, не представляют каких-либо способов устранения гетероскедастичности.
Очевидно, для продвижения к этой цели необходимы некоторые дополнительные предположения относительно характера гетероскедастичности. В самом деле, без подобных предположений, очевидно, невозможно было бы оценить п параметров (п дисперсий ошибок регрессии af ) с помощью п наблюдений.
Наиболее простой и часто употребляемый тест на гетероске-дастичность — тест Уайта. При использовании этого теста предполагается, что дисперсии ошибок регрессии представляют собой одну и ту же функцию от наблюдаемых значений регрессоров, т.е.
а? =/(*,), /= 1 «■ (7.20)
Чаще всего функция / выбирается квадратичной, что соответствует тому, что средняя квадратическая ошибка регрессии зависит от наблюдаемых значений регрессоров приближенно линейно. Гомоскедастичной выборке соответствует случай /= const.
Идея теста Уайта заключается в оценке функции (7.20) с помощью соответствующего уравнения регрессии для квадратов остатков:
е} = /(*,•) + "«> /= 1,..., я, (7.21)
где и і — случайный член.
Гипотеза об отсутствии гетероскедастичности (условие /= const) принимается в случае незначимости регрессии (7.21) в целом.
В большинстве современных пакетов, таких, как «ЕсопотеМс Views», регрессию (7.21) не приходится осуществлять вручную — тест Уайта входит в пакет как стандартная подпрограмма. В этом случае функция / выбирается квадратичной, регрессоры в (7.21) — это регрессоры рассматриваемой модели, их квадраты и, возможно, попарные произведения.
► Пример 7.2. Решить пример 7.1, используя тест Уайта.
Решение. Применение метода наименьших квадратов дает следующее уравнение регрессии переменной Y (дохода индивидуума) по Х (уровню образования) и Х2 (возрасту):
у = -3,06 + 3,25х! + 0,48х2. (-1,40) (5,96) (8,35)
(7.22)
(В скобках указаны значения /-статистик коэффициентов регрессии.) Сравнивая их с табличным значением (4.23), т. е. *о.95:147=1>98, видим, что константа оказывается незначимой.
Обращение к программе White Heteroskedascity Test (Тест Уайта на гетероскедастичностъ) дает следующие значения ^-статистики: F= 7,12, если в число регрессоров уравнения (7.21) не включены попарные произведения переменных, и F = 7,78 — если включены. Так как в соответствии с (4.32) и в том и другом случае F> /Ь.05:2:147=3,07, т. е. гипотеза об отсутствии гетероскедастичности отвергается. ►
Заметим, что на практике применение теста Уайта с включением и невключением попарных произведений дают, как правило, один и тот же результат.
Тест Глейзера. Этот тест во многом аналогичен тесту Уайта, только в качестве зависимой переменной для изучения гетероскедастичности выбирается не квадрат остатков, а их абсолютная величина, т. е. осуществляется регрессия
Щ = /М + щ9 /=1,..., п.
(7.23)
В качестве функций / обычно выбираются функции вида / = а + ух5. Регрессия (7.23) осуществляется при разных значениях 8, затем выбирается то значение, при котором коэффициент у оказывается наиболее значимым, т. е. имеет наибольшее значение /-статистики.
► Пример 7.3. По данным п = 100 наблюдений о размере оплаты труда Y (рис. 5.1) сотрудников фирмы и их разряде выявить, можно ли считать на уровне значимости а линейную рег-рессионую модель Y по X гетероскедастичной. Если модель гете-роскедастична, то установить ее характер, оценив уравнение
Oi=f(Xi).
Решение. Предположим, что дисперсии ошибок а,связаны уравнением регрессии
а, = а + ух?. (7.24)
Используя обычный метод наименьших квадратов, оценим регрессию Y по Х9 а затем — регрессию остатков е по X в виде функции (7.24) при различных значениях 8. Получим (в скобках указаны значения /-статистики коэффициента у) при различных значениях 8:
8=2 ft 8=3 е,
8=1 ^1 = 8,26+ 10,33*,(/ = 7,18);
= 30,75 + 0,89х? (/ = 6,90); ,1 = 39,89 + 0,08*? (/ = 6,32);
8=1/2 ^1 = 32,89 + 43,38^ (/ = 6,99).
Так как все значения /-статистики больше /о.95:98=1>99, то гипотеза об отсутствии гетероскедастичности отвергается. Учитывая, что наиболее значимым коэффициент регрессии у оказывается в случае 8=1, гетероскедастичность можно аппроксимировать первым уравнением. ►

Обсуждение Эконометрика
Комментарии, рецензии и отзывы