7. одномерное распознавание
7. одномерное распознавание
Распознавание одномерных образов с неизвестными средними а1 и а2 и общей дисперсией a2. Неизвестные средние определяются в результате обучения из (5.28):
а, = m Z x(1) a2 Ij x(2)
m,=i s m ,.=i (71)
и представляют собой несмещенные и состоятельные оценки максимального правдоподобия средних по обучающим выборкам
Vx /-^ ,k,Xm ; из S1 и ^ ;-Vx >■■■>Xm ; из S2. Оценка логарифма отношения правдоподобия будет иметь вид:
]f( ) , «в) , (2^exp{-ЬZ{х'-*'У
InL(x,..., x„) In ,n2) -J Ь
юn(xlSi) і expl_lZ(x _a )2
:1nexpi" 207
k-і
2a2
k-і
У-(xk аі У ]
_
"202";
_
Z к t-fe^ )]+a2 \% }=
(a2 а і) a2
k-і
k
іщ a])
—^ :
2a2
n a2 a1 і
2aa
Z
Г 2^
k і
xk a2 сі
--YZ
2
(7.2)
где обозначены случайные величины Y и Z:
Y сі2 сі1 z -a
t xk -(a2 + a1 )
k-1
(7.3)
Решающее правило получается подстановкой значения 1n L(x) из (7.2) в (6.56)
У
2
2 a a
n a2 a 1
Г2^ . /
X v /7 /7
П k-1
>
<
ln C, a2 > a
 | |||||
 | |||||
 | |||||
1
n k-1 < 2
+ a2
ln C
n(a2 a1 ) '
a2 > a1
У
(7.4)
для алгоритма максимума правдоподобия с = 1, In с =0 и
1
У 2
> а, + а2
n— < 2
Уі . (7.5) Вероятность ошибок распознавания одномерных образов. Для нахождения вероятностей ошибок распознавания 1 и 2 рода аир, найдем сначала распределение оценки логарифма отношения
правдоподобия
со,
которое выражается через Y и Z как
распределение произведения этих случайных величин [1, 2]:
СО
-СО
со in l (( )= Jco7 (u )coZ (l/u )du/u
(7.6)
или
 СО ~l I =
СО ~l I =
in L
1
J
exp
(u + а J (l/u а )2
du_ lul
(7.7)
где обозначено
а, а2 2 2 2 2 4
а = а, =— а2 = 1—
а 1 m m n
(7.8)
Вероятности ошибок 1-го и 2-го рода аир одномерного
распознавания определяются подстановкой значения ClnL(() в формулы (3.9) и (3.10):
= Р = Jю[п l (()dl = 2—1 J J J єхр| ~
(u + а)2 ((/u а)2
du
u
+
J expj2
о
(u а)2 ((u + а)2
~Z~2 ' ~~~2
а, а,
(7.9)
Меняя порядок интегрирования в (7.9), получаем:
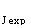 а = р =
а = р =
1
exp
(u а )2 1 1
|а2л/2л 0
((u а )2
d (l/u ) +
-exp
1
(u + а)
[ 2а2 |а2л/2П
Jexp
о
(l/u + а )2 ^ J
d(l u )
du
(7.10)
F
С а ^
Внутренние интегралы можно заменить их значениями
V Q2 У
и
F
' а ^
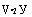
( а >
(7.11) (7.12)
, выражающимися через табулированный интеграл Лапласа F(Z):
F
expi
1 г | (l/u а)2
d (l/u)
J
( а ^
1
F
Va2 У
J expl^^ (l/u)
где [11]
J
F (.) =
1
2
dx
. (7.13) Подставляя (7.11) и (7.12) в (7.10), получаем для а = в:
а = в =
1
a 1
J І ехр 4
(u a ) 2a 1
2
a
a
(u + a У І [ a 2a2
du.
(7.14)
F
f a ^
Оставшиеся интегралы также можно заменить их значениями
Va1 J
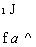
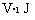
F
и
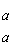 F
F
J expj
выражающимися через интеграл Лапласа F(z) (7.13):
V2n
2a? J
a
1 ? f (u a У }
(7.15)
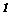

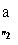
 F
F
2a2
0 ^ "0I J . (7.16)
| a | F | a | + F | a | F | a |
| (ai J | v a2 J | v а1 J | la2 J |
Сопоставлением (7.15) и (7.16) с (7.14) получаем для вероятностей ошибок распознавания а = в их выражение через табулированный интеграл Лапласа:
а = р = f|
(7.17)
Во многих практически важных случаях целесообразно иметь выражение вероятностей ошибок распознавания а = в через другой табулированный интеграл интеграл вероятностей Ф(х) [11].
Ф(х ) = ^= J e -Z?dZ
V271 о (7.18) который связан с интегралом Лапласа (7.13) формулами
Ч /V?
Ф (x )= 2F {x4?)-1
+1
(7.19)
(7.20)
11
а = р = Ф
22
Подставляя значение F(x), выраженное через интеграл вероятностей Ф(х) согласно (7.19) в (7.17), получаем выражение вероятностей ошибок распознавания 1-го и 2-го рода а = в через табулированный интеграл вероятностей (7.18)
(
, ^ 1ф (a4ml2), v-V 2 n + Vm J (721)
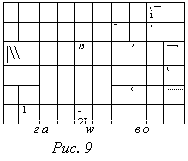
Результаты вычисления зависимости вероятностей ошибок распознавания а= =в по формуле (7.21) при а = 1 от объема m обучающих выборок при различных объемах n контрольных выборок представлены на рис. 9. Как видно из рисунка, влияние объема обучающих выборок особенно сильно проявляется в области малых m (m < 30), где, в частности, увеличение m от 5 до 20 ( при n = 30 ) приводит к уменьшению вероятности ошибок распознавания от 0, 1 до 0,02. При дальнейшем увеличении объема обучающих выборок (m > 50) их влияние на вероятность ошибок распознавания становится менее ощутимым, поскольку эталонные описания при таких значениях m уже достаточно хорошо сформированы и дальнейшее обучение мало что к ним может добавить. Аналогичным образом влияет на вероятности ошибок а = в объем контрольных выборок n это влияние сильно проявляется при малых n (n < 20) и становится мало ощутимым при n > 30.
 о
о
Распознавание одномерных образов с неизвестными средними и
неизвестными дисперсиями. Наиболее общим случаем одномерного
распознавания является определение принадлежности выборки (x )n = (x x )
v і) п) независимых наблюдений к одному из двух классов S1 и S2 характеризующихся неизвестными средними а1 и а2, и неизвестными
дисперсиями Gi и °2. В ходе обучения вычисляются оценки
неизвестных средних а и а
і=і , '" і=і (7.22)
22
_2
и дисперсий <_ и
_2 = 1 (xXf]-a J _2 = 1((2)-а2 J
m -1 і=і , m -1 і=1 . (7.23)
Оценка логарифма отношения правдоподобия будет очевидно иметь следующий вид
ln L (x, ,...,x„ )= ln 6 (X = со (x1xjS,)
(7.24)
Решающее правило получается подстановкой значения из (7.24) в (6.56):
In L (х,,..., хп)
2
1
■I
' і =1
п. С2 > + — ln—2- ln С
2 <<2 <
У1
(7.25)
для алгоритма максимального правдоподобия С решающее правило:
1 , ln С = 0 и
I
і=1
У
2
п а,2 > + -1n^0
2 а2 <
У
(7.26)
2/2
Введем параметры распознавания:
r = Со а
d2 = (а2 а 1 )2/а2 . (7 27)
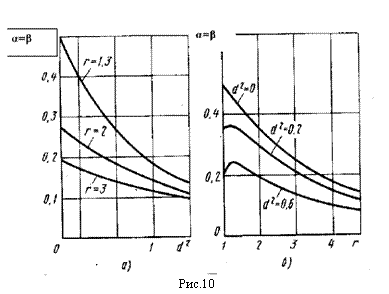 |
На рис 10 (а и б) приведены графики зависимости вероятности ошибок ос=Р от значений параметров d2 и г, вычисленные в работе [1] для n=m=10. Их анализ позволяет утверждать: с ростом расстояния d2 между классами, объемов выборок m и n вероятности ошибок а и в убывают; по мере увеличения г вероятности ошибок а и в сначала незначительно возрастают, а затем начинают быстро уменьшаться (при d2 = 0 сразу уменьшаются).
Это объясняется тем, что рост г фактически означает увеличение дисперсий случайных величин, составляющих обучающие и контрольные выборки из класса S2, что должно приводить при неизменных значениях других параметров к увеличению вероятностей ошибок а и р. С другой стороны, чем больше г, тем сильнее отличие распределений у классов S1 и S2 друг от друга и тем меньше, следовательно, должны бытьрвероятности ошибок а и р. Таким образом, характер изменения вероятностей а и р с ростом г определяется противоположным влиянием этих двух тенденций. Так, увеличение г с 1,01 до 1,3 при m = 10, n = 10, d2 =0,6 сопровождается увеличением вероятности ошибки а с 0,2 до 0,24. Однако при дальнейшем увеличении г до 2,0 вероятность ошибки а падает до 0,196. Это объясняется тем, что с ростом г усиливается влияние тенденции, ведущей к уменьшению вероятностей ошибок а и р, и начиная с некоторого значения г*, ее влияние становится доминирующим. При этом величина г* тем меньше, чем меньше d2. Так, при d2 = 0,6г* « 1,3, при d2 = 0,2г* * 1,25 при d2<0,0k* < 1,01.

Обсуждение Диагностика кризисного состояния предприятия
Комментарии, рецензии и отзывы