Г л а в а viii статистические методы психогенетики
Г л а в а viii статистические методы психогенетики
Образно говоря, статистика является «правой рукой» психогенетики. Как уже отмечалось, психогенетика изучает вопросы наследования поведенческих признаков и психологических функций в популяциях, и по определению эта наука озабочена не отдельными индивидуальностями, а их разнообразием, т.е. популяционной изменчивостью (вариативностью, дисперсией) изучаемого признака. Иными словами, психогенетику интересуют вопросы, касающиеся характеристик распределений (среднем, дисперсии и других моментах распределения) индивидуальных значений по изучаемому признаку в популяции, а также вопросы о том, влиянием каких факторов генетических или средовых можно объяснить наблюдаемую изменчивость. Статистики, описывающие параметры популяции (выборки), приводятся в любом руководстве по статистике, поэтому здесь мы их касаться не будем, а перейдем сразу к статистическим решениям собственно психогенетических задач.
Как уже говорилось, психологические признаки принадлежат к классу количественных признаков, законы наследования которых существенно отличаются от менделевских. Особая здесь и статистика. Последовательно рассмотрим связанные с этим вопросы.
Генетика количественных признаков и ее
значение для психогенетики
Генетика количественных признаков предоставляет психогенетике общую теорию, на базе которой строится методологический аппарат изучения природы индивидуальных психологических различий.
В самом общем виде генетика количественных признаков применительно к психологическим задачам исходит из того, что люди отличаются друг от друга по ряду сложных психологических признаков, и предлагает модель, в рамках которой межиндивидуальные различия по этим признакам могут быть описаны в терминах фенотипической дисперсии признака в популяции, а сама фенотипическая дисперсия может быть разложена на составляющие ее генетические и средовые компоненты.
МОДЕЛЬ ОДНОГО ГЕНА
Количественные генетические модели позволяют описать измеряемые эффекты различных генотипов, возможных в отдельно взятом локусе, и суммировать эффекты всех локусов, контролирующих тот или иной поведенческий признак. Причем количество локусов, контролирующих данный признак, обычно неизвестно, и чаше всего ученые делают допущение о том, что генетический контроль большинства поведенческих признаков осуществляется большим количеством генов, вклад которых в дисперсию изучаемого признака примерно одинаков. Одним из характерных признаков количественных генетических моделей является то, что они предполагают существование нормально распределенных фенотипических значений признаков, контролируемых множеством генов, эффекты которых, в свою очередь, опосредованы средовыми влияниями. Многолетние психологические исследования показали, что распределение большинства поведенческих признаков действительно соответствует нормальной кривой. Поэтому допущение о нормальности распределения признака, контролируемого большим количеством генов и значимых средовых влияний (т.е. являющегося мультифакторным), психологически адекватная и статистически удобная модель для психогенетики. Важно заметить, что ожидаемая от полигенной системы нормальность распределения, будучи статистически удобной и эмпирически оправданной, не зависит от количества генов, контролирующих эту систему. Как статистические характеристики, так и теоретические положения, лежащие в основе моделей количественной генетики, одинаково правомерны для моделей, содержащих 1, 2, 25 или более генов. Именно поэтому мы начнем изложение основных признаков количественной генетики с рассмотрения модели одного гена и только потом перейдем к модели множественных генов (так называемой полигенной модели).

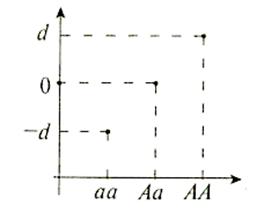
Рис. 8.1. Соотношение трех генотипов, возможных для
двуаллельной системы.
Параметры d и h представляют собой разницы эффектов генов А-а. Аа может находиться на любой из сторон от т, что, соответственно, будет влиять на знак h. В примере, показанном на рисунке, значение h положительно [253, 342].
Генотипическое значение. Генотипическим значением называется некоторое количественное значение, приписываемое определенному генотипу. Так, в рамках простейшей двуаллельной системы (А и а) существуют два параметра, определяющие измеряемые эффекты трех возможных генотипов (АА, Аа и ad). Этими параметрами являются параметр d, представляющий собой удвоенную разницу между гомо-зиготами АА и аа, и параметр h, определяющий измеряемый эффект гетерозиготы Аа таким образом, что он не является точным усредненным эффектом двух гомозигот. Средняя точка между двумя гомозиго-тами, точка т, отражает среднее эффектов двух гомозиготных генотипов. Параметры d и h называются эффектами генотипов. Графически соотношение трех генотипов показано на рис. 8.1. Если в локусе отсутствует доминантность, то h будет равняться нулю, а значение генотипа Аа будет соответствовать значению в точке т. При полной доми-нантности значение Аа будет равняться значению АА. Если же доминантность А частична, то Аа будет находиться ближе к точке АА (или аа, в зависимости от направления доминантности) и значение h будет положительным.
Приведем пример. Предположим, что известны гены, которые влияют на вес человека. Предположим также, что нормальный вес женщин среднего роста составляет 48-70 кг, т.е. разница между максимальным и минимальным значениями по весу равна 22 кг. Теперь предположим, что гены, контролирующие вариативность веса человека, расположены на каждой из 22 аутосомных хромосом (по одному на каждой), причем все гены вызывают примерно одинаковые эффекты. Тогда в рамках нашей гипотетической системы гомозиготы по каждому из изучаемых генов вкладывают примерно ± 1/2 кг (от средней точки), в зависимости от того, являются они гомозиготами по аллелям, обозначаемым заглавной буквой (АА, ВВ, СС и т.д. обладание этими генотипами повышает рост), или гомозиготами по аллелям, обозначаемым строчными буквами (аа, bb, cc и т.д. обладание этими генотипами понижает рост). Рассмотренный пример, однако, невероятен по крайней мере по двум причинам: во-первых, генов, контролирующих вариативность веса человека, мы не знаем и, во-вторых, в ре-льной ситуации вклады генотипов, скорее всего, будут меньше или больше, см /г кг, затрудняя подсчет генотипического значения.
Модели генетики количественных признаков, во всяком случае в их классическом варианте, не являются ни средством идентификации конкретных генов, контролирующих вариативность признака, ни средством точного определения вклада каждого генотипа. Эти модели решают другую задачу, а именно задачу определения общего вклада генотипа в вариативность изучаемого признака в популяции.
Аддитивное генотипическое значение. «Аддитивное генотипическое значение» представляет собой фундаментальное понятие количественной генетики, поскольку оно отражает, насколько генотип «истинно наследуется». Аддитивный (суммарный) эффект генов представляет собой не что иное, как сумму эффектов отдельных аллелей. Более точно,аддитивное генотипическое значение есть генотипическое значение, обусловленное действием отдельных аллелей данного локуса. Генная доза генотипа подсчитывается на основе того, сколько аллелей определенного типа (например, аллелей А) присутствует в данном генотипе. Если наличие определенного аллеля в генотипе увеличивается на 1 (как это происходит, например, в случае перехода от генотипа аа к генотипу Aа), то аддитивное значение увеличивается на некоторую определенную величину. На рис. 8.2 дана графическая иллюстрация аддитивного генотипического значения при отсутствии доминантности. Эффект генотипа аа = -d, поэтому эффект аллеля (гена) а = 1/2(-d); эффект генотипа АА = d, поэтому эффект аллеля А = 1/2(d); соответственно, эффект генотипа Аа = 1/2(d) + 1/2(-d) = 0.
 Заметим, что аддитивные генные значения зависят от частоты встречаемости аллелей в популяции. При отсутствии доминирования аддитивный эффект полностью определяет генотипическое значение. Доминантность, однако, вносит самые разные отклонения от ожидаемых значений, об этом пойдет речь ниже.
Заметим, что аддитивные генные значения зависят от частоты встречаемости аллелей в популяции. При отсутствии доминирования аддитивный эффект полностью определяет генотипическое значение. Доминантность, однако, вносит самые разные отклонения от ожидаемых значений, об этом пойдет речь ниже.
Рис. 8.2. При отсутствии доминантности (h = 0) аддитивное генотипическое значение определяется генной дозой.
Теперь допустим, что каждый аллель генотипа имеет некоторый средний эффект. В этом смысле аддитивное генотипическое значение представляет собой сумму средних эффектов каждого аллеля для всех аллелей, входящих в генотип. Каждый аллель характеризуется определенным аддитивным эффектом, соответственно, при унаследовании определенного аллеля от родителя ребенок наследует и аддитивный эффект этого аллеля, т.е. вклад аллеля в генотип ребенка будет таким же, каким был его (аллеля) вклад в генотип родителя. И неважно, сколько (много или мало) аллелей присутствует в данном локусе или сколько локусов вовлечено в контроль вариативности по тому или другому признаку. Иными словами, аддитивное генотипическое значение представляет собой не что иное, как сумму вкладов каждого аллеля в генотип.
Доминантные отклонения. Доминантные отклонения есть мера того, насколько генотип отличается от своего ожидаемого аддитивного значения.
Доминантные отклонения (рис. 8.3) это разница между ожидаемыми и наблюдаемыми значениями генотипов. Феномен доминантности допускает, что два аллеля одного локуса могут взаимодействовать друг с другом и тем самым менять генотипическое значение, которое наблюдалось бы в том случае, если бы они были независимы друг от друга и делали независимые вклады в генотипическое значение. Так, в результате взаимодействия аллелей Аа наблюдаемое генотипическое значение меньше того, которое ожидалось бы при условии полной доминантности. Напротив, значения АА и аа выше ожидаемых при допущении, что аллель А полностью доминантен по отношению к аллелю а.
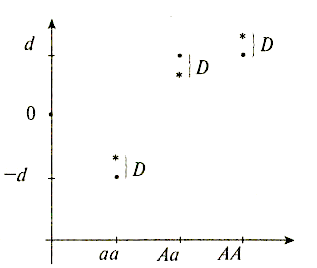
Рис. 8.3. Графическое изображение доминантных отклонений.
Наличие доминантности вносит разного рода изменения в аддитивное
генотипическое значение.
Обозначения'. • аддитивные генотипические значения при условии полной доминантности; * наблюдаемые аддитивные значения, определяемые на основе генных доз; D доминантные отклонения, которые представляют собой разницу между ожидаемыми аддитивными значениями, соответствующими ситуации полной доминантности, и значениями, наблюдаемыми для определенных генных доз.
Доминантность обязана своим возникновением уникальному сочетанию аллелей в данном локусе. Очевидно, что генотип потомка, наследующего только один аллель от каждого из родителей, в подавляющем большинстве случаев не может воспроизвести уникальность генотипа одного из них. Поэтому потомки будут отличаться от своих Родителей в той мере, в какой аллели данного локуса не суммируются линейным образом при определении генотипического значения.
Рассмотрев типы генетических влияний, определим, как частоты встречаемости аллелей, определяющие эти типы, задают среднее значение генотипа в популяции. Допустим, что в популяции аллели А и а встречаются с частотами р и q, соответственно. Тогда первая колонка в табл. 8.1 показывает три возможных генотипа, вторая частоты их встречаемости в популяции (при допущении, что особи в этой популяции образуют родительские пары случайным образом) и третья значение генотипа. Популяционное среднее получается путем умножения значений генотипа на частоту встречаемости тех аллелей, которые этот генотип составляют, и последующего суммирования значений все трех генотипов.
Таблица 8.1
Определение среднего значения генотипа в популяции
| Генотип | Частота | Значение | Частота х значение |
| АА | Р2 | +d | p2d |
| Аа | 2pq | h | 2pqh |
| Аа | q2 | -d | -q2d |
| | |||
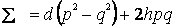
Значение 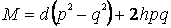 представляет собой одновременно и фенотипическое и генотипическое значения среднего в популяции при допущении, что средовая дисперсия в популяции равна 0. Таким образом, вклад любого локуса в популяционное среднее определяется двумя величинами: величиной rf(/?2-^2), приписываемой влиянию гомозиготности, и Ihpq, приписываемой влиянию гетерозиготности. При отсутствии доминантности (А = 0) значение второго термина равно 0 и, соответственно, популяционное среднее пропорционально генной частоте М == d( 1 lq). В случае полной доминантности {h = с/) популяционное среднее пропорционально квадрату генной частоты М = d{ 2<72). При отсутствии сверхдоминантности разброс значений, приписываемых локусу, равняется Id (иначе говоря, если аллель А фиксирован в популяции, т.е. р = 1, то популяционное среднее будет равно d; если же в популяции фиксирован аллель а, т.е. q = 1, популяционное среднее будет равно -d). Однако при сверхдоминантности локуса среднее в популяции с отсутствием фиксации может лежать за пределами этого спектра.
представляет собой одновременно и фенотипическое и генотипическое значения среднего в популяции при допущении, что средовая дисперсия в популяции равна 0. Таким образом, вклад любого локуса в популяционное среднее определяется двумя величинами: величиной rf(/?2-^2), приписываемой влиянию гомозиготности, и Ihpq, приписываемой влиянию гетерозиготности. При отсутствии доминантности (А = 0) значение второго термина равно 0 и, соответственно, популяционное среднее пропорционально генной частоте М == d( 1 lq). В случае полной доминантности {h = с/) популяционное среднее пропорционально квадрату генной частоты М = d{ 2<72). При отсутствии сверхдоминантности разброс значений, приписываемых локусу, равняется Id (иначе говоря, если аллель А фиксирован в популяции, т.е. р = 1, то популяционное среднее будет равно d; если же в популяции фиксирован аллель а, т.е. q = 1, популяционное среднее будет равно -d). Однако при сверхдоминантности локуса среднее в популяции с отсутствием фиксации может лежать за пределами этого спектра.
полигенные ГЕНЕТИЧЕСКИЕ МОДЕЛИ
Одним из центральных допущений генетики количественных признаков, в том числе и психологических, является допущение о возможности суммирования генетических эффектов каждого локуса внутри генетической системы, включающей несколько локусов. Иными словами, если генетическая система состоит из двух локусов, А и В, то при определении генетического эффекта всей системы генетические эффекты А (аддитивные и доминантные) суммируются с генетическими эффектами В (аддитивными и доминантными). Кроме того, при характеристике общего генетического эффекта этой системы необходимо учитывать эффекты, возникающие в результате взаимодействия между локусами А и В. Эти эффекты называются эпистатическими эффектами.
Эпистатические эффекты. Напомним, что доминантность возникает в результате неаддитивных взаимодействий аллелей в одном ло-кусе. Подобным же образом аллели разных локусов, функционируя в рамках одной генетической системы, могут взаимодействовать, приводя к возникновению так называемого эпистаза. Таким образом, в отличие от доминантности, возникающей в результате взаимодействия аллелей внутри одного локуса, эпистаз есть результат взаимодействия аллелей разных локусов.
Итак, генетические эффекты, возникающие в рамках полигенной модели, бывают трех типов: аддитивные (А), доминантные (D) и эпистатические (I). Представим это заключение символически:
G = А + D + I.
Соответственно сказанному выше, G представляет собой сумму всех генетических влияний в рамках полигенной системы; А сумму всех аддитивных влияний для всех локусов, входящих в данную систему; D отражает все доминантные влияния в данной системе, и / характеризует генетические влияния, которые возникают в результате взаимодействия аллелей разных локусов, включенных в данную систему.
Фенотипическое значение. Мы рассмотрели представления генетики количественных признаков о генетических влияниях на формирование межиндивидуальной вариативности непрерывно распределенных признаков. Однако совершенно очевидно, что на поведенческие признаки оказывает влияние и среда. Количественная генетическая модель предполагает, что межиндивидуальная вариативность по признаку в популяции определяется как генетическими, так и средовыми факторами. Иными словами,
P=G+E+(G ´ E),
где Р наблюдаемые (фенотипические) значения признака в некоторой популяции. Р функция генетических (G) и средовых (Е) отклонений от, соответственно, генотипического и средового средних, и некоего интеракционистского члена G ´ Е, который отражает влияния, возникающие в результате взаимодействия генотипа и среды (ГС-взаимодействия и ГС-корреляции).
Как уже было сказано (гл. V), популяцией называется группа индивидов, проживающих на определенной территории, имеющих общий язык, общую историю и культуру и характерный генофонд, сформированный и сохранившийся в результате того, что члены популяции вступают в браки между собой намного чаще, чем с представителями других популяций. Члены популяции похожи друг на друга (или отличаются друг от друга) по набору морфологических, физиологических, психологических и других характеристик, называемых в генетике признаками. Напомним, что измеряемое значение любого признака называется фенотипом (гл. I), он является результатом реализации данного генотипа в данной среде. Популяционный разброс по изучаемому признаку (популяционная вариативность признака) называется фенотипической дисперсией (Vp) и вычисляется по формуле:
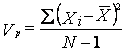 ,
,
где Nколичество индивидов в исследуемой популяции, Xi значение исследуемого признака у i-го члена популяции (т.е. его фенотип), а Х популяционное среднее по исследуемому признаку.
Теперь запишем обе полученные формулы (для G и для Р) в терминах дисперсии:
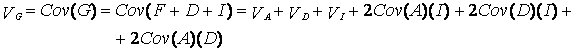
При допущении независимости (т.е. отсутствия корреляции между ними) А, D и /, члены уравнения, отражающие ковариации между этими составляющими генотипической дисперсии, могут быть сокращены. Тогда
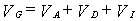 .
.
Иными словами, наблюдаемая генотипическая вариативность в популяции есть результат суммирования вариативности аддитивной, доминантной и эпистатической.
Подобным же образом в терминах дисперсии может быть записано фенотипическое разнообразие людей в популяции:
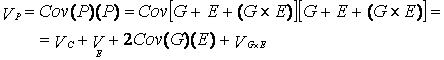
Иначе говоря, количественные психогенетические модели основаны на допущении, что популяционная фенотипическая вариативность может быть объяснена влиянием генетических (VG) и средовых факторов (VE), а также гено-средовых эффектов, возникающих в результате соприсутствия этих двух факторов [генотип-средовой ковариации Cov(G)(E) и генотип-средового взаимодействия (VG´E)]. Если всю фенотипическую изменчивость принять за 100\%, то вклады генотипа, среды и генотип-средовых эффектов тоже могут быть выражены в процентах. Иными словами, когда говорят, что вклад генотипа в формирование межиндивидуальной вариативности признака составляет 60\%, это означает, что на все остальные составляющие приходится 40\%.
Распределение фенотипических значений признака в популяции может быть представлено в качестве суммы разбросов определенных значений (см. табл. 8.2).
Таблица 8.2
Структура фенотипической вариативности признака в популяции
| Составляющая изменчивости | Символ | Значение, для которого определяется дисперсия |
| Фенотипическая | VP | Фенотипическое значение |
| Генотипическая | VG | Генотипическое значение |
| Аддитивная | VA | Аддитивное значение |
| Доминантная | VD | Доминантность |
| Эпистатическая | VI | Значение эффекта взаимодействия генов |
| Средовая | VE | Средовые отклонения |
В обобщенном виде задачу генетики количественных признаков можно сформулировать так: установление того, какие компоненты и в какой степени определяют вариативность фенотипических значений исследуемого признака.
Рассмотрим далее составляющие психогенетической количественной модели подробнее.
ГЕНЕТИЧЕСКИЕ ЭФФЕКТЫ
Изучая механизм генетического контроля того или иного признака, исследователи ставят перед собой задачу найти ответы на четыре ключевых вопроса: 1) Насколько сильно влияние генотипа на формирование различий между людьми? 2) Каков биологический механизм этого влияния (сколько и какие гены вовлечены, каковы их Функции и где, на каком участке какой хромосомы, они локализова-^i? 3) Каковы биологические процессы, соединяющие белковый про-дукт генов и конкретный фенотип? 4) Существуют ли какие-нибудь бедовые факторы, влияние которых может привести к изменению следуемого генетического механизма, и если существуют, то какова величина их влияния? Остановимся несколько подробнее на первом вопросе, хотя современная психогенетика занимается поисками ответов на все указанные вопросы.
Итак, описываемая модель, адресующаяся к первому из названных вопросов, не отвечает на вопрос «как?», ее цель выяснить, насколько сильно влияние генотипа на формирование индивидуальных различий. Влияние генотипа выражается относительной величиной, отражающей размерность вклада генов в фенотипическую дисперсию. Этой величиной является коэффициент наследуемости, вычисляемый как отношение вариативности генетической к вариативности фенотипической:
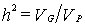
Экспериментальные генетические исследования, проведенные с растениями и животными, показали, что коэффициент наследуемости является суммарной величиной и включает как аддитивные, так и неаддитивные, возникающие в результате взаимодействия, генетические эффекты.
Выделяют два типа коэффициента наследуемости: один из них оценивает наследуемость в широком смысле, второй в узком. Первый (его иногда называют также коэффициентом генетической детерминации) говорит о том, насколько популяционная изменчивость фенотипического признака определяется генетическими различиями между людьми. Его величина может варьировать от 0 до 1, т.е. теоретически изменчивость признака может и совсем не зависеть от вариативности генотипов и, наоборот, полностью определяться ею; чем выше значение этого коэффициента, тем выше роль наследственности в формировании индивидуальных различий.
Второй коэффициент оценивает только ту долю изменчивости, которая связана с аддитивным действием генов; благодаря этому он позволяет получить сведения не о причинах популяционной изменчивости признака, а о свойствах гамет и генов, полученных потомками от своих родителей. Вот почему, например, в селекции животных и растений именно он используется при селекционировании.
Для обозначения рассматриваемых коэффициентов разные авторы используют разные символы. Мы примем те, которые предложены в авторитетном руководстве «Генетика человека», написанным Ф. Фогелем и А. Мотульски [159]. Авторы определяют наследуемость в широком смысле формулой:
где VG общая генотипическая дисперсия, включающая доминирование, эпистаз и аддитивные составляющие.
Наследуемость в узком смысле определяется формулой:
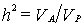
Таким образом, эти коэффициенты различаются только числителями дроби: если в числителе находится суммарная генотипическая вариативность в популяции (VG) речь идет о наследуемости в широком смысле; если же в числителе VA то имеется в виду наследуемость в узком смысле.
Как и любой статистический показатель, коэффициент наследуемости предполагает определенные допущения и ограничения, поэтому интерпретироваться должен грамотно. Фогель и Мотульски выделяют три свойства коэффициента наследуемости.
1. Поскольку коэффициент наследуемости есть отношение, его величина может изменяться при изменении числителя (т.е. вариативности генотипов) или знаменателя (т.е. вариативности средовых условий). Он увеличивается, когда повышается генетическая дисперсия или, наоборот, снижается вариативность сред.
2. Оценка дисперсии основана на анализе корреляций между родственниками; этот анализ проводится по определенным правилам (см. далее), но они справедливы только при допущении случайного подбора супружеских пар. Применительно к психологии человека это допущение неверно, поэтому необходимы статистические поправки на ассортативность, в противном случае возникают систематические смещения в оценке h2.
3. Одно из главных допущений при вычислениях h2 отсутствие ковари-ации и взаимодействия между генетическим значением и средовым отклонением, что также не всегда верно.
Все это необходимо иметь в виду при вычислении и, главное, интерпретации оценок наследуемости.
Кроме того, разные методы психогенетики имеют разную разрешающую способность оценки как h2, так и составляющих VP. Например, метод близнецов не позволяет оценить VD т.е. дисперсию доминирования. Он дает только суммарную оценку VD+VA. Правда, Фогель и Мотульски, опираясь на работу Д. Фальконера, считают, что составляющая VD обычно незначима по сравнению с VA, и поэтому допустимо предположение о том, что практически вся генотипическая вариативность сводится к аддитивной вариативности: VG=VA. Тогда формула коэффициента наследуемости примет вид . Это сильно упрощает логику дальнейших рассуждении.
Анализу средовых и генотип-средовых эффектов была посвящена гл. VI. Обобщенная характеристика этих компонентов уравнения фенотипической дисперсии приведена в табл. 8.3.
Таблица 8.3
Компоненты фенотипической дисперсии
| Эффект | Обозначение | Тип эффекта |
| Общий средовой Уникальный средовой Генотип-средовая корреляция Генотнп-средовое взаимодействие Ассортативность | VEC (или VC) VEN (или VN) CorGE (или Cov(G)(E) G ´ E (или VG ´ E) m | средовой средовой генотип-средовой генотип-средовой генотип-средовой |
Методы анализа психогенетических
эмпирических данных
Как говорилось в гл. VII, психогенетиками была разработана система методов, которые позволяют оценить составляющие фенотипи-ческой дисперсии; все они построены на решении систем уравнений, описывающих сходство родственников различных степеней родства. К их анализу мы теперь и переходим.
КЛАССИЧЕСКИЙ АНАЛИЗ РОДСТВЕННЫХ КОРРЕЛЯЦИИ
Сходство родственников, принадлежащих к разным поколениям (предки потомки), обычно оценивается коэффициентом корреляции Пирсона, который называют также межклассовым коэффициентом корреляции. В случае близнецов и сиблингов применяется коэффициент внутриклассовой корреляции, подсчитываемый на основе дисперсионного анализа:
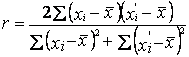 ,
,
где xi¢ и xi значения одного и того же признака у близнецов одной пары.
Использование внутриклассовой корреляции в данном случае обусловлено тем, что нет генетического критерия для отнесения того или иного члена пары в тот или другой вариационный ряд. В табл. 8.4 приведен пример вычисления внутриклассовой корреляции для МЗ близнецов.
Таблица 8.4
Вычисление внутриклассового коэффициента корреляции
| Значение признака | ||||||
| Пары | близнец 1 | близнец 2 | (Х1 – Х2) | (Х1 – Х2)2 | (Х1 + Х2) | (Х1 + Х2)2 |
| Х1 | Х2 | |||||
| 1 | 9 | 7 | 2 | 4 | 16 | 256 |
| 2 | 4 | 6 | -2 | 4 | 10 | 100 |
| 3 | 3 | 2 | 1 | 1 | 5 | 25 |
| 4 | 2 | 1 | 1 | 1 | 3 | 9 |
| 5 | 4 | 3 | 1 | 1 | 7 | 49 |
| СУММЫ 11 41 43 439 | ||||||
R= В / (B+ W); W= å(x1-x2)2 / (2N) ,
где R коэффициент корреляции; В межпарная дисперсия признака; Wвнутрипарная дисперсия признака.
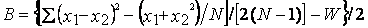 ;
;
W= 11/2/5= 1,1;
В ={[439-41/5]/2/41,1}/2 = {[439 1681/5]/81,1}/2= = 5,875
R =5,875/(5,875 + 1,1) =0,842.
Внутриклассовый коэффициент корреляции, в отличие от межклассового, не изменяется при перемене мест членов пары.
При подсчете коэффициента корреляции обычно вычисляется и ошибка его измерения. Это важно, так как наличие ошибок измерения ведет к искажению коэффициента корреляции и, следовательно, при проведении генетического анализа по коэффициентам корреляции между родственниками будут получаться смещенные оценки компонентов дисперсии признака. В связи с этим производится поправка коэффициентов корреляции на дисперсию ошибки измерения, для чего проводят повторные измерения признаков у одних и тех же индивидов. Дисперсия ошибки измерения равна внутрипар

Обсуждение Психогенетика
Комментарии, рецензии и отзывы