2.1. принципы построения и этапы проектирования базы данных
2.1. принципы построения и этапы проектирования базы данных
Автоматизированные информационно-справочные системы в настоящее время получили весьма широкое распространение, что связано прежде всего со сравнительной простотой их создания и исключительно высоким эффектом от внедрения. Методологической основой информационных технологий, реализуемых в АИСС, являются концепции централизованной (в рамках разработки баз и банков данных) и распределенной (в рамках создания информационных сетей) обработки информации.
2.1.1. Основные понятия и определения
В науке одним из наиболее сложных для строгого определения является понятие "информация". Согласно кибернетическому подходу [15] "информация — первоначальное сообщение данных, сведений, осведомление и т. п. Кибернетика вывела понятие информации за пределы человеческой речи и других форм коммуникации между людьми, связала его с целенаправленными системами любой природы. Информация выступает в трех формах:
биологической (биотоки; связи в генетических механизмах);
машинной (сигналы в электрических цепях);
социальной (движение знаний в общественных системах)".
Иными словами, "информация — связь в любых целенаправленных системах, определяющая их целостность, устойчивость, уровень функционирования" [49]. Содержание и особенности информации раскрываются указанием действий, в которых она участвует:
хранение (на некотором носителе информации);
преобразование (в соответствии с некоторым алгоритмом)',
передача (с помощью передатчика и приемника по некоторой линии связи).
В соответствии с этим же подходом "данные — факты и идеи, представленные в формализованном виде, позволяющем передавать или обрабатывать их при помощи некоторого про-цесса и соответствующих технических устройств" [15].
Толковый словарь по информатике [49, 53] определяет понятия "информация" и "данные" несколько иначе:
"информация — 1) совокупность знаний о фактических данных и связях между ними; 2) в вычислительной технике — содержание, присваиваемое данным посредством соглашений, распространяющихся на эти данные; данные, подлежащие вводу в ЭВМ, хранимые в ее памяти, обрабатываемые на ЭВМ и выдаваемые пользователям";
"данные — информация, представленная в виде, пригодном для обработки автоматическими средствами при возможном участии человека".
Как легко заметить, приведенные определения вынужденно используют такие сложно определяемые понятия, как "факты", "идеи" и, особенно, "знания".
В дальнейшем под информацией будем понимать любые сведения о процессах и явлениях, которые в той или иной форме передаются между объектами материального мира (людьми; животными; растениями; автоматами и др.).
Если рассмотреть некоторый объект материального мира, информация о котором представляет интерес, и наблюдателя (в роли которого и выступают АИС), способного фиксировать эту информацию в определенной, понятной другим форме, то говорят, что в памяти ("сознании") наблюдателя находятся данные, описывающие состояние объекта. Таким образом, данными будем называть формализованную информацию, пригодную для последующей обработки, хранения и передачи средствами автоматизации профессиональной деятельности.
Информацию в ЭВМ можно хранить в виде различных данных (числовых; текстовых; визуальных и т. п.). Более того, для описания одной и той же информации можно предложить различные варианты их состава и структуры. Иными словами, правомерно говорить о моделировании в АИС информации о некотором множестве объектов материального мира совокупностью взаимосвязанных данных.
Информационное обеспечение (information support) АИС — совокупность единой системы классификации и кодирования информации; унифицированных систем документации и используемых массивов информации [53, 54]. В дальнейшем нас будет интересовать именно последний аспект данного определения.
В этой связи в качестве главных задач создания информационного обеспечения АИС можно выделить:
во-первых, определение состава и структуры данных, достаточно "хорошо" описывающих требуемую информацию;
во-вторых, обоснование способов хранения и переработки данных с использованием ЭВМ.
Процесс создания информационного обеспечения включает несколько этапов, рассмотрению которых посвящен п. 2.1.2. В данном пункте остановимся на понятиях и определениях, связанных с технологией банков данных.
Прежде чем определить понятие "банк данных", необходимо остановиться на другом ключевом понятии — "предметная область".
Под предметной областью будем понимать информацию об объектах, процессах и явлениях окружающего мира, которая, с точки зрения потенциальных пользователей, должна храниться и обрабатываться в информационной системе. В этом определении особое внимание следует уделить важности роли потенциальных потребителей информационных ресурсов АИС. Именно этот аспект обусловливает и структуру, и основные задачи, и вообще целесообразность создания того или иного банка.
Банк данных (БнД) — информационная система, включающая в свой состав комплекс специальных методов и средств для поддержания динамической информационной модели с целью обеспечения информационных потребностей пользователей [15, 39]. Очевидно, что БнД может рассматриваться как специальная обеспечивающая подсистема в составе старшей по иерархии АИС.
Поддержание динамической модели ПО предусматривает не только хранение информации о ней и своевременное внесение изменений в соответствии с реальным состоянием объектов, но и обеспечение возможности учета изменений состава этих объектов (в том числе появление новых) и связей между ними (т. е. изменений самой структуры хранимой информации).
Обеспечение информационных потребностей (запросов) пользователей имеет два аспекта [45]:
определение границ конкретной ПО и разработка описания соответствующей информационной модели;
разработка БнД, ориентированного на эффективное обслуживание запросов различных категорий пользователей.
С точки зрения целевой направленности профессиональной деятельности принято выделять пять основных категорий пользователей [45]:
аналитики;
системные программисты;
прикладные программисты;
администраторы;
конечные пользователи.
Кроме того, различают пользователей постоянных и разовых; пользователей-людей и пользователей-задач; пользователей с различным уровнем компетентности (приоритетом) и др., причем каждый класс пользователей предъявляет собственные специфические требования к своему обслуживанию (прежде всего — с точки зрения организации диалога "запрос—ответ"). Так, например, постоянные пользователи, как правило, обращаются в БнД с фиксированными по форме (типовыми) запросами; пользователи-задачи должны иметь возможность получать информацию из БнД в согласованной форме в указанные области памяти; пользователи с низким приоритетом могут получать ограниченную часть информации и т. д. Наличие столь разнообразного состава потребителей информации потребовало включения в БнД специального элемента — словаря данных, о чем будет сказано ниже.
Уровень сложности и важности задач информационного обеспечения АИС в рамках рассматриваемой технологии определяет ряд основных требований к БнД [53]:
адекватность информации состоянию предметной области;
быстродействие и производительность;
простота и удобство использования;
массовость использования;
защита информации;
♦ возможность расширения круга решаемых задач. (Отметим, что все названные требования можно предъявить и к любому финансовому банку.)
По сравнению с традиционным обеспечением монопольными файлами каждого приложения централизованное управление данными в БнД имеет ряд важных преимуществ:
сокращение избыточности хранимых данных;
устранение противоречивости хранимых данных;
многоаспектное использование данных (при однократном вводе);
ташпдетсская оптимизация (с точки зрения удовлетворения разнообразных, в том числе и противоречивых, требований "в целом");
обеспечение возможности стандартизации;
обеспечение возможности санкционированного доступа к данным и др.
Все названные преимущества по существу связаны с такими основополагающими принципами концепции БнД, как интеграция данных, централизация управления ими и обеспечение независимости прикладных программ обработки данных и самих данных.
Структура типового БнД, удовлетворяющего предъявляемым требованиям, приведена на рис. 2.1.1, где представлены:
ВС — вычислительная система, включающая технические средства (ТС) и общее программное обеспечение {ОПО);
БД — базы данных;
СУБД — система управления БД;
АБД — администратор баз данных, а также обслуживающий персонал и словарь данных.
Подробнее остановимся на составляющих БнД, представляющих наибольший интерес. БД — совокупность специальным образом организованных (структурированных) данных и связей между ними. Иными словами, БД — это так называемое датологическое (от англ. data — данные) представление информации о предметной области. Если в состав БнД входит одна БД, банк принято называть локальным; если БД несколько — интегрированным.
СУБД — специальный комплекс программ и языков, посредством которого организуется централизованное управление базами данных и обеспечивается доступ к ним.
В состав любой СУБД входят языки двух типов:
язык описания данных (с его помощью описываются типы данных, их структура и связи);
язык манипулирования данными (его часто называют язык запросов к БД), предназначенный для организации работы с данными в интересах всех типов пользователей.
Банк данных (БнД)
ВС
БД
СУБД
АБД
опо
Словарь данных
Персонал
тс
Рис. 2.1.1. Основные компоненты БнД
Словарь данных предназначен для хранения единообразной и централизованной информации обо всех ресурсах данных конкретного банка:
об объектах, их свойствах и отношениях для данной ПО;
о данных, хранимых в БД (наименование; смысловое описание; структура; связи и т. п.);
о возможных значениях и форматах представления данных;
об источниках возникновения данных;
о кодах защиты и разграничении доступа пользователей к данным и т. п.
Администратор баз данных — это лицо (группа лиц), реализующее управление БД. В этой связи сам БнД можно рассматривать как автоматизированную систему управления базами данных. Функции АБД являются долгосрочными; он координирует все виды работ на этапах создания и применения БнД. На стадии проектирования АБД выступает как идеолог и главный конструктор системы; на стадии эксплуатации он отвечает за нормальное функционирование БнД, управляет режимом его работы и обеспечивает безопасность данных (последнее особенно важно при современном уровне развития средств коммуникации — см. подразд. 1.5).
Основные функции АБД [15, 54]:
решать вопросы организации данных об объектах ПО и установления связей между этими данными с целью объединения информации о различных объектах; согласовывать представления пользователей;
координировать все действия по проектированию, реализации и ведению БД; учитывать текущие и перспективные требования пользователей; следить, чтобы БД удовлетворяли актуальным потребностям;
решать вопросы, связанные с расширением БД в связи с изменением границ ПО;
разрабатывать и реализовывать меры по обеспечению защиты данных от некомпетентного их использования, от сбоев технических средств, по обеспечению секретности определенной части данных и разграничению доступа к ним;
выполнять работы по ведению словаря данных; контролировать избыточность и противоречивость данных, их достоверность;
следить за тем, чтобы БнД отвечал заданным требованиям по производительности, т. е. чтобы обработка запросов выполнялась за приемлемое время;
выполнять при необходимости изменения методов хранения данных, путей доступа к ним, связей между данными, их форматов; определять степень влияния изменений в данных на всю БД;
координировать вопросы технического обеспечения системы аппаратными средствами, исходя из требований, предъявляемых БД к оборудованию;
координировать работы системных программистов, разрабатывающих дополнительное программное обеспечение для улучшения эксплуатационных характеристик системы;
координировать работы прикладных программистов, разрабатывающих новые прикладные программы, и выполнять их проверку и включение в состав ПО системы и т. п.
 На рис. 2.1.2 представлен типовой состав группы АБД, отражающий основные направления деятельности специалистов.
На рис. 2.1.2 представлен типовой состав группы АБД, отражающий основные направления деятельности специалистов.
2.1.2. Описательная модель предметной области
Процесс проектирования БД является весьма сложным. По сути, он заключается в определении перечня данных, хранимых на физических носителях (магнитных дисках и лентах), которые достаточно полно отражают информационные потребности потенциальных пользователей в конкретной ПО. Проектирование БД начинается с анализа предметной области и возможных запросов пользователей. В результате этого анализа определяется перечень данных и связей между ними, которые адекватно — с точки зрения будущих потребителей — отражают ПО. Завершается проектирование БД определением форм и способов хранения необходимых данных на физическом уровне.
Весь процесс проектирования БД можно разбить на ряд взаимосвязанных этапов, каждый из которых обладает своими особенностями и методами проведения. На рис. 2.1.3 представлены типовые этапы.
На этапе мифологического (информационно-логического) проектирования осуществляется построение семантичес-
 Выбор СУБД
Выбор СУБД
I
Построение концептуальной модели данных (ЛП)
Этап датологического проектирования
Построение физической модели данных (ФП)
Рис 2.1.3. Этапы проектирования БД
кой модели, описывающей сведения из предметной области, которые могут заинтересовать пользователей БД. Семантическая модель (semantic model) — представление совокупности о ПО понятий... в виде графа, в вершинах которого расположены понятия, в терминальных вершинах — элементарные понятия, а дуги представляют отношения между понятиями.
Сначала из объективной реальности выделяется ПО, т. е. очерчиваются ее границы. Логический анализ выделенной ПО и потенциальных запросов пользователей завершается построением инфологической модели ПО — перечня сведений об объектах ПО, которые необходимо хранить в БД и связях между ними.
Анализ информационных потребностей потенциальных пользователей имеет два аспекта:
определение собственно сведений об объектах ПО;
анализ возможных запросов к БД и требований по оперативности их выполнения.
Анализ возможных запросов к БД позволяет уточнить связи между сведениями, которые необходимо хранить. Пусть, например, в БД по учебному процессу института хранятся сведения об учебных группах, читаемых курсах и кафедрах, а также связи "учебные группы—читаемые курсы" и "читаемые курсы—кафедры". Тогда запрос о том, проводит ли некоторая кафедра занятия в конкретной учебной группе может быть выполнен только путем перебора всех читаемых в данной группе курсов.
Хранение большого числа связей усложняет БД и приводит к увеличению потребной памяти ЭВМ, но часто существенно ускоряет поиск нужной информации. Поэтому разработчику БД (АБД) приходится принимать компромиссное решение, причем процесс определения перечня хранимых связей, как правило, имеет итерационный характер.
Датологическое проектирование подразделяется на логическое (построение концептуальной модели данных) и физическое (построение физической модели) проектирование.
Главной задачей логического проектирования (ЛП) БД является представление выделенных на предыдущем этапе сведений в виде данных в форматах, поддерживаемых выбранной СУБД.
Задача физического проектирования (ФП) — выбор способа хранения данных на физических носителях и методов доступа к ним с использованием возможностей, предоставляемых СУБД.
Мифологическая модель "сущность—связь" (entity — relationship model; ER-model) П. Чена (P. Chen) представляет собой описательную (неформальную) модель ПО, семантически определяющую в ней сущности и связи [44].
Относительная простота и наглядность описания ПО позволяет использовать ее в процессе диалога с потенциальными пользователями с самого начала инфологического проектирования. Построение инфологической модели П. Чена, как и любой другой модели, является творческим процессом, поэтому единой методики ее создания нет. Однако при любом подходе к построению модели используют три основных конструктивных элемента:
сущность;
атрибут;
связь.
Сущность — это собирательное понятие некоторого повторяющегося объекта, процесса или явления окружающего мира, о котором необходимо хранить информацию в системе. Сущность может определять как материальные (например, "студент", "грузовой автомобиль" и т. п.), так и нематериальные объекты (например, "экзамен", "проверка" и т. п.). Главной особенностью сущности является то, что вокруг нее сосредоточен сбор информации в конкретной ПО. Тип сущности определяет набор однородных объектов, а экземпляр сущности — конкретный объект в наборе. Каждая сущность в модели Чена именуется. Для идентификации конкретного экземпляра сущности и его описания используется один или несколько атрибутов.
Атрибут — это поименованная характеристика сущности, которая принимает значения из некоторого мнбжества значений [46]. Например, у сущности "студент" могут быть атрибуты "фамилия", "имя", "отчество", "дата рождения", "средний балл за время обучения" и т. п.
Связи в инфологической модели выступают в качестве средства, с помощью которого представляются отношения между сущностями, имеющими место в ПО. При анализе связей между сущностями могут встречаться бинарные (между двумя сущностями) и, в общем случае, п-арные (между п сущностями) связи. Например, сущности "отец", "мать" и "ребенок" могут находиться в трехарном отношении "семья" ("является членом семьи").
Связи должны быть поименованы; между двумя типами сущностей могут существовать несколько связей.
Наиболее распространены бинарные связи. Учитывая, что любую п-арную связь можно представить в виде нескольких бинарных, подробнее остановимся именно на таких связях между двумя типами сущностей, устанавливающими соответствие между множествами экземпляров сущностей.
Различают четыре типа связей:
связь один к одному (1:1);
связь один ко многим (1:М);
связь многие к одному (М:1);
связь многие ко многим (M:N).
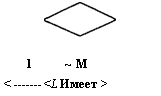
Связь один к одному определяет такой тип связи между типами сущностей А и В, при которой каждому экземпляру сущности А соответствует один и только один экземпляр сущности В, и наоборот. Таким образом, имея некоторый экземпляр сущности А, можно однозначно идентифицировать соответствующий ему экземпляр сущности В, а по экземпляру сущности В — экземпляр сущности А. Например, связь типа 1:1 "имеет" может быть определена между сущностями "автомобиль" и "двигатель", так как на конкретном автомобиле может быть установлен только один двигатель, и этот двигатель, естественно, нельзя установить сразу на несколько автомобилей.
Связь один ко многим определяет такой тип связи между типами сущностей А и В, для которой одному экземпляру сущности А может соответствовать 0, 1 или несколько экземпляров сущности В, но каждому экземпляру сущности В соответствует один экземпляр сущности А. При этом однозначно идентифицировать можно только экземпляр сущности А по экземпляру сущности В. Примером связи типа 1:М является связь "учится" между сущностями "учебная группа" и "студент". Для такой связи, зная конкретного студента, можно однозначно идентифицировать учебную группу, в которой он учится, или, зная учебную группу, можно определить всех обучающихся в ней студентов.
Связь многие к одному по сути эквивалентна связи один ко многим. Различие заключается лишь в том, с точки зрения какой сущности (А или В) данная связь рассматривается.
Связь многие ко многим определяет такой тип связи между типами сущностей А и В, при котором каждому экземпляру сущности А может соответствовать 0, 1 или несколько экземпляров сущности В, и наоборот. При такой связи, зная экземпляр одной сущности, можно указать все экземпляры другой сущности, относящиеся к исходному, т. е. идентификация сущностей не уникальна в обоих направлениях. В качестве примера такой связи можно рассмотреть связь "изучает" между сущностями "учебная дисциплина" и "учебная группа".
Реально все связи являются двунаправленными, т. е., зная экземпляр одной из сущностей, можно идентифицировать (однозначно или многозначно) экземпляр (экземпляры) другой сущности. В некоторых случаях целесообразно рассматривать лишь однонаправленные связи между сущностями в целях экономии ресурсов ЭВМ. Возможность введения таких связей полностью определяется информационными потребностями пользователей. Различают простую и многозначную однонаправленные связи, которые являются аналогами связей типа 1:1 и 1:М с учетом направления идентификации. Так, для простой однонаправленной связи "староста" ("является старостой") между сущностями "учебная группа" и "студент" можно, зная учебную группу, однозначно определить ее старосту, но, зная конкретного студента, нельзя сказать, является ли он старостой учебной группы. Примером многозначной однонаправленной связи служит связь между сущностями "пациент" и "болезнь", для которой можно для каждого пациента указать его болезни, но нельзя выявить всех обладателей конкретного заболевания.
Введение однонаправленных связей означает, что в результате анализа потенциальных запросов потребителей установлено, что потребности в информации, аналогичной приведенной в двух последних примерах, у пользователей не
будет (и они не будут формулировать соответствующие запросы к БД).
Графически типы сущностей, атрибуты и связи принято изображать прямоугольниками, овалами и ромбами соответственно. На рис. 2.1.4 представлены примеры связей различных типов; на рис. 2.1.5 и 2.1.6 — фрагменты инфологических моделей "военнослужащие" (без указания атрибутов) и "учебный процесс факультета".
Несмотря на то, что построение инфологической модели есть процесс творческий, можно указать два основополагающих правила, которыми следует пользоваться всем проектировщикам БД [15,44]:
при построении модели должны использоваться только три типа конструктивных элементов: сущность, атрибут, связь;
каждый компонент информации должен моделироваться только одним из приведенных выше конструктивных элементов для исключения избыточности и противоречивости описания.
 |
Личный №
 |
Подчиненный
 |
НИР
Двунаправленные связи
Пациент
1 ^ М ^
И С Имеет > И

Заболевание
Однонаправленная связь Рис. 2.1.4. Примеры связей между сущностями
Моделирование ПО начинают с выбора сущностей, необходимых для ее описания. Каждая сущность должна соответствовать некоторому объекту (или группе объектов) ПО, о котором в системе будет накапливаться информация. Существует проблема выбора конструктивного элемента для моделирования той или иной "порции" информации, что существенно затрудняет процесс построения модели.
Так, информация о том, что некоторый студент входит в состав учебной группы (УГ) можно в модели представить:
как связь "входит в состав" для сущностей "студент" и "УГ";
как атрибут "имеет в составе "студента" сущности "УГ";
как сущность "состав УГ".
В этих случаях приходится рассматривать несколько вариантов и с учетом информационных потребностей пользователей разбивать ПО на такие фрагменты, которые с их точки зрения представляют самостоятельный интерес.
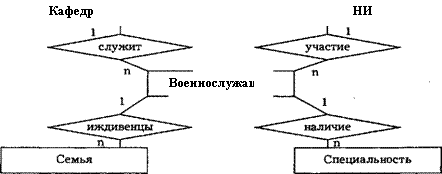 Рис. 2.1.5. Фрагмент ER-модели "Военнослужащие"
Рис. 2.1.5. Фрагмент ER-модели "Военнослужащие"
При моделировании ПО следует обращать внимание на существующий в ней документооборот. Именно документы, циркулирующие в ПО, должны являться основой для формулирования сущностей. Это связано с двумя обстоятельствами: ♦ эти документы, как правило, достаточно полно отражают информацию, которую необходимо хранить в БД, причем в виде конкретных данных;
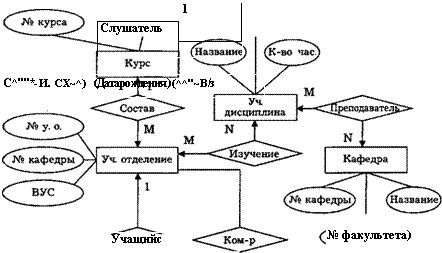 ♦ создаваемая информационная система должна предоставлять пользователям привычную для них информацию в привычном виде, что в последующем существенно облегчит ввод БД в эксплуатацию.
♦ создаваемая информационная система должна предоставлять пользователям привычную для них информацию в привычном виде, что в последующем существенно облегчит ввод БД в эксплуатацию.
Рис. 2.1.6. Фрагмент ER-модели "Учебный процесс факультета"
При описании атрибутов сущности необходимо выбрать ряд атрибутов, позволяющих однозначно идентифицировать экземпляр сущности. Совокупность идентифицирующих атрибутов называют ключом.
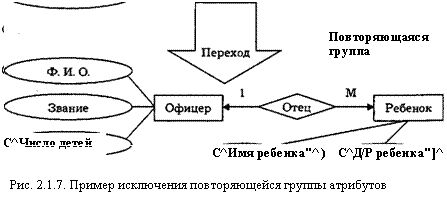
Помимо идентифицирующих используются и описательные атрибуты, предназначенные для более полного определения сущностей. Число атрибутов (их тип) определяется единственным образом — на основе анализа возможных запросов пользователей. Существует ряд рекомендаций по "работе с атрибутами" [15, 44], например, по исключению повторяющихся групп атрибутов (см. рис. 2.1.7). Все они направлены на улучшение качества инфологической модели.
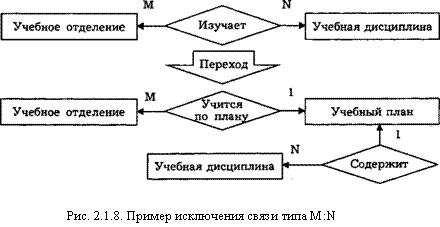
При определении связей между сущностями следует избегать связей типа M:N, так как они приводят к существенным затратам ресурсов ЭВМ. Устранение таких связей предусматривает введение других (дополнительных) элементов — сущностей и связей. На рис. 2.1.8 приведен пример исключения связи многие ко многим.
 В заключение приведем типовую последовательность работ (действий) по построению инфологической модели:
В заключение приведем типовую последовательность работ (действий) по построению инфологической модели:
выделение в ПО сущностей;
введение множества атрибутов для каждой сущности и выделение из них ключевых;
исключение множества повторяющихся атрибутов (при необходимости);
формирование связей между сущностями;
исключение связей типа M:N (при необходимости);
преобразование связей в однонаправленные (по возможности).
 Помимо модели Чена существуют и другие инфологи-ческие модели. Все они представляют собой описательные (неформальные) модели, использующие различные конструктивные элементы и соглашения по их использованию для представления в БД информации о ПО. Иными словами, первый этап построения БД всегда связан с моделированием предметной области.
Помимо модели Чена существуют и другие инфологи-ческие модели. Все они представляют собой описательные (неформальные) модели, использующие различные конструктивные элементы и соглашения по их использованию для представления в БД информации о ПО. Иными словами, первый этап построения БД всегда связан с моделированием предметной области.
2.1.3. Концептуальные модели данных
В отличие от инфологической модели ПО, описывающей по некоторым правилам сведения об объектах материального мира и связи между ними, которые следует иметь в БД, концептуальная модель описывает хранимые в ЭВМ данные и связи. В силу этого каждая модель данных неразрывно связана с языком описания данных конкретной СУБД (см. рис. 2.1.3).
По существу модель данных — это совокупность трех составляющих [15, 44]:
типов (структур) данных;
операций над данными;
ограничений целостности.
Другими словами, модель данных представляет собой некоторое интеллектуальное средство проектировщика, позволяющее реализовать интерпритацию сведений о ПО в виде формализованных данных в соответствии с определенными требованиями, т. е. средство абстракции, которое дает возможность увидеть "лес" (информационное содержание данных), а не отдельные "деревья" (конкретные значения данных).
Типы структур данных
Среди широкого множества определений, обозначающих типы структур данных, наиболее распространена терминология КОДАСИЛ (Conference of DAta SYstems Language) — международной ассоциации по языкам систем обработки данных, созданной в 1959 г.
В соответствии с этой терминологией используют пять типовых структур (в порядке усложнения):
элемент данных;
агрегат данных;
запись;
набор;
база данных.
Дадим краткие определения этих структур [15, 44, 45].
Элемент данных — наименьшая поименованная единица данных, к которой СУБД может адресоваться непосредственно и с помощью которой выполняется построение всех остальных структур данных.
Агрегат данных — поименованная совокупность элементов данных, которую можно рассматривать как единое целое. Агрегат может быть простым или составным (если он включает в себя другие агрегаты).
Запись — поименованная совокупность элементов данных и (или) агрегатов. Таким образом, запись — это агрегат, не входящий в другие агрегаты. Запись может иметь сложную иерархическую структуру, поскольку допускает многократное применение агрегации.
Набор — поименованная совокупность записей, образующих двухуровневую иерархическую структуру. Каждый тип набора представляет собой связь между двумя типами записей. Набор определяется путем объявления одного типа записи "записью-владельцем", а других типов записей — "записями-членами". При этом каждый экземпляр набора должен содержать один экземпляр "записи-владельца" и любое количество "записей-членов". Если запись представляет в модели данных сущность, то набор — связь между сущностями. Например, если рассматривать связь "учится" между сущностями "учебная группа" и "студент", то первая из сущностей объявляется "записью-владельцем" (она в экземпляре набора одна), а вторая — "записью-членом" (их в экземпляре набора может быть несколько).
База данных — поименованная совокупность экземпляров записей различного типа, содержащая ссылки между записями, представленные экземплярами наборов.
Отметим, что структуры БД строятся на основании следующих основных композиционных правил [15, 44]:
БД может содержать любое количество типов записей и типов наборов;
между двумя типами записей может быть определено любое количество наборов;
тип записи может быть владельцем и одновременно членом нескольких типов наборов.
Следование данным правилам позволяет моделировать данные о сколь угодно сложной ПО с требуемым уровнем полноты и детализации.
Рассмотренные типы структур данных могут быть представлены в различной форме — графовой; табличной; в виде исходного текста языка описания данных конкретной СУБД.
Операции над данными
Операции, реализуемые СУБД, включают селекцию (поиск) данных; действия над данными.
Селекция данных выполняется с помощью критерия, основанного на использовании либо логической позиции данного (элемента; агрегата; записи), либо значения данного, либо связей между данными [46].
Селекция на основе логической позиции данного базируется на упорядоченности данных в памяти системы. При этом критерии поиска могут формулироваться следующим образом:
найти следующее данное (запись);
найти предыдущее данное;
найти n-ое данное;
найти первое (последнее) данное. Этот тип селекции называют селекцией посредством текущей, в качестве которой используется индикатор текущего состояния, автоматически поддерживаемый СУБД и, как правило, указывающий на некоторый экземпляр записи БД.
Критерий селекции по значениям данных формируется из простых или булевых условий отбора. Примерами простых условий поиска являются:
ВУС = 200100;
ВОЗРАСТ > 20;
ДАТА < 19.04.2002 и т. п.
Булево условие отбора формируется путем объединения простых условий с применением логических операций, например:
(ДАТА_РОЖДЕНИЯ < 28.12.1963) И (СТАЖ> 10);
♦ (УЧЕНОЕ_ЗВАНИЕ=ДОЦЕНТ:) ИЛИ (УЧЕНОЕ ЗВАНИЕ=ПРОФЕССОР) и т. п.
Если модель данных, поддерживаемая некоторой СУБД, позволяет выполнить селекцию данных по связям, то можно найти данные, связанные с текущим значением какого-либо данного [46]. Например, если в модели данных реализована двунаправленная связь "учится" между сущностями "студент" и "учебная группа", можно выявить учебные группы, в которых учатся юноши (если в составе описания студента входит атрибут "пол").
Как правило, большинство современных СУБД позволяет осуществлять различные комбинации описанных выше видов селекции данных.
Ограничения целостности
Ограничения целостности — логические ограничения на данные — используются для обеспечения непротиворечивости данных некоторым заранее заданным условиям при выполнении операций над ними. По сути ограничения целостности — это набор правил, используемых при создании конкретной модели данных на базе выбранной СУБД.
Различают внутренние и явные ограничения.
Ограничения, обусловленные возможностями конкретной СУБД, называют внутренними ограничениями целостности. Эти ограничения касаются типов хранимых данных (например, "текстовый элемент данных может состоять не более чем из 256 символов" или "запись может содержать не более 100 полей") и допустимых типов связей (например, СУБД может поддерживать только так называемые функциональные связи, т. е. связи типа 1:1, 1:М или М:1). Большинство существующих СУБД поддерживают прежде всего именно внутренние ограничения целостности [46], нарушения которых приводят к некорректности данных и достаточно легко контролируются.
Ограничения, обусловленные особенностями хранимых данных о конкретной ПО, называют явными ограничениями целостности. Эти ограничения также поддерживаются средствами выбранной СУБД, но они формируются обязательно с участием разработчика БД путем определения (программирования) специальных процедур, обеспечивающих непротиворечивость данных. Например, если элемент данных "зачетная книжка" в записи "студент" определен как ключ, он должен быть уникальным, т. е. в БД не должно быть двух записей с одинаковыми значениями ключа. Другой пример: пусть в той же записи предусмотрен элемент "военно-учетная специальность" и для него отведено 6 десятичных цифр. Тогда другие представления этого элемента данных в БД невозможны. С помощью явных ограничений целостности можно организовать как "простой" контроль вводимых данных (прежде всего, на предмет принадлежности элементов данных фиксированному и заранее заданному множеству значений: например, элемент "ученое звание" не должен принимать значение "почетный доцент", если речь идет о российских ученых), так и более сложные процедуры (например, введение значения "профессор" элемента данных "ученое звание" в запись о преподавателе, имеющем возраст 25 лет, должно требовать, по крайней мере, дополнительного подтверждения).
Элементарная единица данных может быть реализована множеством способов, что, в частности, привело к многообразию известных моделей данных. Модель данных определяет правила, в соответствии с которыми структурируются данные. Обычно операции над данными соотносятся с их структурой.
Разнообразие существующих моделей данных соответствует разнообразию областей применения и предпочтений пользователей.
В специальной литературе встречается описание довольно большого количества различных моделей данных. Хотя наибольшее распространение получили иерархическая, сетевая и, бесспорно, реляционная модели, вместе с ними следует упомянуть и некоторые другие.
Используя в качестве классификационного признака особенности логической организации данных, можно привести следующий перечень известных моделей данных:
иерархическая;
сетевая;
реляционная;
бинарная;
семантическая сеть.
Рассмотрим основные особенности перечисленных моделей.
Иерархическая модель данных
Наиболее давно используемой (можно сказать классической) является модель данных, в основе которой лежит иерархическая структура типа дерева. Дерево — орграф, в каждую вершину которого, кроме первой (корневой), входит только одна дуга, а из любой вершины (кроме конечных) может исходить произвольное число дуг. В иерархической структуре подчиненный элемент данных всегда связан только с одним исходным.
На рис. 2.1.9 показан фрагмент объектной записи в иерархической модели данных. Часто используется также "упорядоченное дерево", в котором значим относительный порядок поддеревьев.
Достоинства такой модели несомненны: простота представления предметной области, наглядность, удобство анализа структур и простота их описания. К недостаткам следует отнести сложность добавления новых и удаления существующих типов записей, невозможность отображения отношений, отличающихся от иерархических, громоздкость описания и информационную избыточность.
Характерные примеры реализации иерархических структур — язык Кобол и СУБД семейства IMS (создана в рамках проекта высадки на Луну — "Аполлон") и System 2000 (S2K).
 |
Грузовые поезда
Пассажирские суда
Грузовые суда
Сухогрузные суда
Наливные суда
Рис. 2.1.9. Фрагмент иерархической модели данных
Сетевая модель данных
В системе баз данных, предложенных CODASYL, за основу была взята сетевая структура. Существенное влияние на разработку этой модели оказали ранние сетевые системы — IDS и Ассоциативный ПЛ/1. Необходимость в процессе получения одного отчета обрабатывать несколько файлов обусловила целесообразность установления перекрестных ссылок между файлами, что в конце концов и привело к сетевым структурам [54].
Сетевая модель данных основана на представлении информации в виде орграфа, в котором в каждую вершину может входить произвольное число дуг. Вершинам графа сопоставлены типы записей, дугам — связи между ними. На рис. 2.1.10 представлен пример структуры сетевой модели данных.
По сравнению с иерархическими сетевые модели обладают рядом существенных преимуществ: возможность отображения практически всего многообразия взаимоотношений объектов предметной области, непосредственный доступ к
Кафедра "Менеджмент"
Кафедра "Экономика"
Учебная дисциплина "Управление персоналом"
Учебная дисциплина "Менеджмент"
Учебная дисциплина "Экономика"
Студент факультета менеджмента
Студент факультета экономики
Студент юридического факультета
Рис. 2.1.10. Фрагмент сетевой модели данных
любой вершине сети (без указания других вершин), малая информационная избыточность. Вместе с тем в сетевой модели невозможно достичь полной независимости данных [54] — с ростом объема информации сетевая структура становится весьма сложной для описания и анализа.
Известно [62], что применение на практике иерархических и сетевых моделей данных в некоторых случаях требует разработки и сопровождения значительного объема кода приложения, что иногда может стать для информационной системы непосильным бременем.
Реляционная модель данных
В основе реляционной модели данных (см. п. 2.1.4) лежат не графические, а табличные методы и средства представления данных и манипулирования ими (рис. 2.1.11). В реляционной модели для отображения информации о предметной области используется таблица, называемая "отношением". Строка такой таблицы называется кортежем, столбец — атрибутом. Каждый атрибут может принимать некоторое подмножество значений из определенной области — домена [42].
Первичный ключ
Вуз
МГУ им. М. В. Ломоносова
Место расположения
г. Москва
Количество обучаемых (студентов)
26170
Поле базы данных (атрибут сущности)
Домен (множество) возможных значений характеристики объекта)
Государственный технический университет
12 150
г. Санкт-Петербург
Кортеж (вектор размерности к, включающий по одному из возможных значений к доменов)
Рис. 2.1.11. Фрагмент реляционной модели данных
Таблица организации БД позволяет реализовать ее важнейшее преимущество перед другими моделями данных, а именно — возможность использования точных математических методов манипулирования данными, и прежде всего — аппарата реляционной алгебры и исчисления отношений [54]. К другим достоинствам реляционной модели можно отнести наглядность, простоту изменения данных и организации разграничения доступа к ним.
Основным недостатком реляционной модели данных является информационная избыточность, что ведет к перерасходу ресурсов вычислительных систем (отметим, что существует ряд приемов, позволяющих в значительной степени избавиться от этого недостатка — см. подразд. 2.2). Однако именно реляционная модель данных находит все более широкое применение в практике автоматизации информационного обеспечения профессиональной деятельности.
Подавляющее большинство СУБД, ориентированных на персональные ЭВМ, являются системами, построенными на основе реляционной модели данных — реляционными СУБД.
Бинарная модель данных
 Бинарная модель данных — это графовая модель, в которой вершины являются представлениями простых однозначных атрибутов, а дуги — представлениями бинарных связей между атрибутами (см. рис. 2.1.12).
Бинарная модель данных — это графовая модель, в которой вершины являются представлениями простых однозначных атрибутов, а дуги — представлениями бинарных связей между атрибутами (см. рис. 2.1.12).
Бинарная модель не получила особо широкого распространения, но в ряде случаев находит практическое применение.
Так, в области искусственного интеллекта уже давно ведутся исследования с целью представления информации в виде бинарных отношений. Рассмотрим триаду (тройку) "объект—атрибут—значение" (более подробно об этом будет сказано в подразд. 4.2). Триада "Кузнецов—возраст—20" означает, что возраст некоего Кузнецова равен 20 годам. Эта же информация может быть выражена, например, бинарным отношением ВОЗРАСТ. Понятие бинарного отношения положено в основу таких моделей данных, как, например, Data Semantics (автор Абриал) и DIAM II (автор Сенко).
Бинарные модели данных обладают возможностью представления связки любой сложности (и это их несомненное преимущество), но вместе с тем их ориентация на пользователя недостаточна [53].
Семантическая сеть
Семантические сети как модели данных были предложены исследователями, работавшими над различными проблемами искусственного интеллекта (см. разд. 4). Так же, как в сетевой и бинарной моделях, базовые структуры семантической сети могут быть представлены графом, множество вершин и дуг которого образует сеть. Однако семантические сети предназначены для представления и систематизации знаний самого общего характера [53].
Таким образом, семантической сетью можно считать любую графовую модель (например — помеченный бинарный граф) если изначально четко определено, что обозначают вершины и дуги и как они используются.
Семантические сети являются богатыми источниками идей моделирования данных, чрезвычайно полезных в плане решения проблемы представления сложных ситуаций. Они могут быть использованы независимо или совместно с идеями, положенными в основу других моделей данных. Их интересной особенностью является то, что расстояние, измеренное на сети (семантическое расстояние или метрика), играет важную роль, определяя близость взаимосвязанных понятий. При этом предусмотрена возможность в явной форме подчеркнуть, что семантическое расстояние велико. Как показано на рис. 2.1.13, СПЕЦИАЛЬНОСТЬ соотносится с личностью ПРЕПОДАВАТЕЛЬ, и в то же время ПРЕПОДАВАТЕЛЮ присущ РОСТ. Взаимосвязь личности со специальностью очевидна, однако из этого не обязательно следует взаимосвязь СПЕЦИАЛЬНОСТИ и РОСТА.
 Следует сказать, что моделям данных типа семантической сети при всем присущем им богатстве возможностей при моделировании сложных ситуаций присуща усложненность и некоторая неэкономичность в концептуальном плане [53].
Следует сказать, что моделям данных типа семантической сети при всем присущем им богатстве возможностей при моделировании сложных ситуаций присуща усложненность и некоторая неэкономичность в концептуальном плане [53].
2.1.4. Реляционная модель данных
Как было отмечено в п. 2.1.3, в основе реляционной модели данных лежат их представления в виде таблиц, что в значительной степени облегчает работу проектировщика БД и — в последующем — пользователя в силу привычности и распространенности такого варианта использования информации. Данная модель была предложена Э. Ф. Коддом (Е. F. Codd) в начале 70-х гг. XX в., и вместе с иерархической и сетевой моделями составляет множество так называемых великих моделей. Можно сказать, что сегодня именно эта модель используется во всех наиболее распространенных СУБД.
Определение любой модели данных требует описания трех элементов:
типов (структур) данных;
операций над данными;
ограничений целостности.
Сначала рассмотрим структуры данных и ограничения целостности, а затем более подробно остановимся на операциях реляционной алгебры.
Типы структур данных
Рассмотрение этого вопроса требует введения определений нескольких основных понятий.
Множество возможных значений некоторой характеристики объекта называется доменом (domain):
D,= {diV diZ,...din).
Например, в качестве домена можно рассматривать такие характеристики студента, как его фамилия, курс, рост и т. п.
DKypc = {2, 3, 4, 5,};
°ФаМилия = {Иванов, Петров, Сидоров,...}; = {160, 161, 162,..,190}.
Очевидно, что можно сопоставить понятия "атрибут" инфологической и "домен" реляционной моделей данных. Возможные значения характеристик объектов могут принимать числовые или текстовые значения, а их множества могут быть как конечными, так и бесконечными. Отметим, что в случае конечности домена можно организовать проверку явных ограничений целостности: в нашем примере домен определяет, что все студенты должны иметь рост от 160 до 190 см, а номер курса не может превышать 5.
Вектор размерности к, включающий в себя по одному из возможных значений к доменов, называется кортежем (tuple). Для приведенного выше примера кортежами являются:
(1, Иванов, 172); (3, Сидоров, 181); (5, Уткин, 184).
Если в кортеж входят значения всех характеристик объекта ПО (т. е. атрибутов сущности инфологической модели), ему можно сопоставить такую типовую структуру данных, как запись (объектная запись).
Декартовым произведением k доменов называется множество всех возможных значений кортежей:
D = D, х D2 х...х Dk.
Пусть для того же примера определены три домена:
D = {1, 4}; D2 = {Иванов, Петров}; D3= {168, 181}.
Тогда их декартовым произведением будет множество D, состоящее из восьми записей:
D = Dj x D2 x D.
( (1, Иванов, 168) (1, Иванов, 181) (1, Петров, 168) (1, Петров, 181) (4, Иванов, 168) (4, Иванов, 181) (4, Петров, 168) (4, Петров, 181) t
При увеличении размерности любого из доменов увеличивается и размерность их декартова произведения. Так, если в первом домене определены три элемента D1 = {1, 4, 5}, декартово произведение имеет вид:
D — Dj х D2 х D3
1, Иванов, 168) 1, Иванов, 181) 1, Петров, 168) 1, Петров, 181) 4, Иванов, 168) 4, Иванов, 181) 4, Петров, 168)
Петров, 181)
Иванов, 168) 5, Иванов, 181) 5, Петров, 168) 5, Петров, 181)
Иными словами, декартово произведение — множество всех возможных комбинаций элементов исходных доменов.
Наконец, важнейшее определение: отношением (relation) R, определенным на множествах доменов D„ D2,...,Dk, называют подмножество их декартова произведения:
R с Dj х D2 х...х Dk.
Элементами отношения являются кортежи. Отношение может моделировать множество однотипных объектов (сущностей), причем экземпляр сущности может интерпретироваться как кортеж. С помощью отношения можно моделировать и связи, в которых находятся объекты ПО (сущности в ее инфологической модели). При этом кортеж такого отношения состоит из идентифицирующих атрибутов связываемых сущностей.
Таким образом, понятие отношения позволяет моделировать данные и связи между ними. В силу этого можно определить реляционную базу данных (РБД) как совокупность экземпляров конечных отношений.
Если учесть, что результат обработки любого запроса к РБД также можно интерпретировать как отношение (возможно, не содержащее ни одного кортежа), то возникает возможность построения информационной системы, основным инструментом которой будет алгебра отношений (реляционная алгебра). Любой запрос в такой системе может быть представлен в виде формулы, состоящей из отношений, объединенных операциями реляционной алгебры. Создав СУБД, обеспечивающую выполнение этих операций, можно разрабатывать информационные системы, в которых любой запрос потребителя программируется формулой.
Ограничения целостности
Отношение может быть представлено таблицей, обладающей определенными свойствами (которые, по сути, и определяют внутренние ограничения целостности данных) [54]:
♦ каждая строка таблицы — кортеж;
порядок строк может быть любым;
повторение строк не допускается;
порядок столбцов в отношении фиксирован. Понятие "отношение" весьма схоже с понятием "файл
данных". Поэтому в дальнейшем будем использовать следующую терминологию: отношение — файл; кортеж — запись; домен — поле. Идентификация конкретной записи файла осуществляется по ключу (набору полей, по значению которого можно однозначно идентифицировать запись). В файле можно определить несколько ключей. Один из них, включающий минимально возможное для идентификации записи число полей, называется первичным ключом.
Применительно к понятию "файл данных" внутренние ограничения целостности формулируются следующим образом:
количество полей и их порядок в файле должны быть фиксированными (т. е. записи файла должны иметь одинаковые длину и формат);
каждое поле должно моделировать элемент данных (неделимую единицу данных фиксированного формата, к которому СУБД может адресоваться непосредственно);
в файле не должно быть повторяющихся записей. Системы управления базами данных, основанные на РБД,
поддерживают и явные ограничения целостности. На практике они определяются зависимостями между атрибутами (см. п. 2.1.2).
2.1.5. Операции реляционной алгебры
Операции реляционной алгебры лежат в основе языка манипулирования данными СУБД, основанных на РБД. Эти операции выполняются над файлами и результатом их выполнения также является файл, который в общем случае может оказаться и пустым.
При описании операций реляционной алгебры будем использовать обозначения:
ИФ (ИФ1; ИФ2) — имя исходного (первого исходного; второго исходного) файла;
ФР — имя файла результата.
Некоторые операции накладывают на исходные файлы ограничения, которые в определенном смысле можно рассматривать как внутренние ограничения целостности.
Проектирование
Формальная запись: ФР = proj [список имен полей] (ИФ). Операция не накладывает ограничений на исходный файл. Операция предусматривает следующие действия:
из ИФ исключаются все поля, имена которых отсутствуют в списке имен полей;
из полученного файла удаляются повторяющиеся записи.
 Пример. Пусть ИФ (КАДРЫ) содержит 4 поля:
Пример. Пусть ИФ (КАДРЫ) содержит 4 поля:
и требуется выполнить операцию
ФР = proj [П/Я] (КАДРЫ). Тогда после выполнения операции получим результат
ФР
П/Я 34170 11280 27220
Заметим, что с помощью приведенной операции можно выявить, в каких почтовых ящиках работают сотрудники, информация о которых содержится в данном файле.
Селекция (выбор)
Формальная запись: ФР = sel [условие] (ИФ).
Эта операция также не накладывает ограничений на ИФ. В файл результата заносятся те записи из ИФ, которые удовлетворяют условию поиска. Условие представляет собой логическое выражение, связывающее значения полей ИФ.
Пример. Пусть для приведенного выше ИФ КАДРЫ требуется выявить сотрудников П/Я 34170, имеющих должность "ст. инженер". Для отработки такого запроса достаточно выполнить операцию:
 ФР = sel [ДОЛЖНОСТЬ = "ст. инженер" И П/Я = "34170"] (КАДРЫ).
ФР = sel [ДОЛЖНОСТЬ = "ст. инженер" И П/Я = "34170"] (КАДРЫ).
Отметим, что данная операция не изменяет структуру ИФ. Кроме того, при такой формальной записи операции предполагается, что СУБД поддерживает отработку сложных (составных) запросов, в противном случае пришлось бы составное условие поиска отрабатывать последовательно — сначала выявить сотрудников, имеющих должность "ст. инженер", а затем — из них выделить тех, кто служит в П/Я 34170 (или наоборот). Иногда такой (последовательный) порядок поиска имеет определенные преимущества — прежде всего в тех случаях, когда на сложный запрос дан отрицательный ответ и непонятно, что послужило причиной этого (в нашем примере — или нет сотрудников должности "ст. инженер", или никто из них не "работает" в указанном П/Я, или такого предприятия вообще "нет" в БД).
Соединение
Формальная запись: ФР = ИФ1 ► < ИФ2. (список полей)
В реляционной алгебре определено несколько операций соединения. Мы рассмотрим так называемое естественное соединение.
Условием выполнения данной операции является наличие в соединяемых файлах одного или нескольких однотипных полей, по которым и осуществляется соединение (эти поля указываются в списке; если список пуст, соединение осуществляется по всем однотипным полям).
В файл результата заносятся записи, являющиеся так называемыми конкатенациями (англ. concatenate — сцеплять, связывать) записей исходных файлов. Иными словами, в ФР попадают записи ИФ1 и ИФ2 с совпадающими значениями полей, по которым осуществляется соединение ("сцепка").
Тогда после выполнения операции ФР = КАДРЫ ► < ЦЕХ получим
 |
 Следует обратить внимание, что в формате команды не указаны поля соединения. Следовательно, оно осуществляется по единственному однотипному полю (НОМЕР).
Следует обратить внимание, что в формате команды не указаны поля соединения. Следовательно, оно осуществляется по единственному однотипному полю (НОМЕР).
Пример 2. Пусть требуется выяснить, в каком цехе п/я 34170 работает ст. инженер Сидоров.
Для этого требуется выполнить операции:
ФР1 = sel [ДОЛЖНОСТЬ = "ст. инженер" И П/Я = "34170" И ФАМИЛИЯ = "Сидоров"] (К

Обсуждение Информационные системы в экономике
Комментарии, рецензии и отзывы