6.3. множественная регрессия
6.3. множественная регрессия
По данным о рынке жилья в Московской области, представленным в табл. 6.1, исследуется зависимость между ценой квартиры Y (тыс. долл.) и следующими основными факторами :
Y цена квартиры, тыс. долл.;
X1 город области (1Подольск, 2-Люберцы);
X2 число комнат в квартире;
X3 общая площадь квартиры (м );
X4 жилая площадь квартиры (м );
X5 этаж квартиры;
X6 площадь кухни (м).
Необходимо провести полный множественный анализ зависимости признака Y от факторов X1... X6.
Задание: 1) построить линейную модель множественной регрессии со всеми факторами; 2) исследовать корреляционную матрицу на мультиколлинеарность, исключить лишние факторы, исключить незначимые факторы и построить новую линейную модель; 3) оценить адекватность обоих уравнений регрессии по критерию Фишера; 4) сравнить обе модели; 5) провести анализ на нормальность и гомоскедастичность остатков; 6) сравнить цены в обоих городах.
Доверительный уровень взять равным а=0,05. Расчет основных статистик.
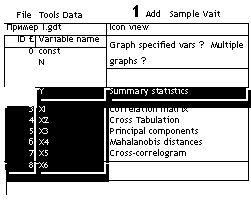
Выбираем переменные: выделяем курсором первую нужную переменную (Y), нажимаем клавишу [Shift] на клавиатуре и выделяем курсором последнюю переменную (X6). Можно также выделять переменные курсором по очереди, удерживая клавишу [Ctrl].
В первой строке программой вставлена вспомогательная переменная, во второй строке находятся номера наблюдений (были в исходном файле данных).
Последовательно выбираем пункты меню [View]^[Summary statistics] (рис. 6.5). После нажатия на последний, появляется окно с расчетными данными (рис. 6.6).
Рис. 6.5. Расчет основных статистик.
 |
Полученные результаты можно сохранить, распечатать, скопировать или произвести в них поиск (соответствующие кнопки находятся на верхней части панели окна основных статистик).
При копировании данных появляется окно выбора формата представления.
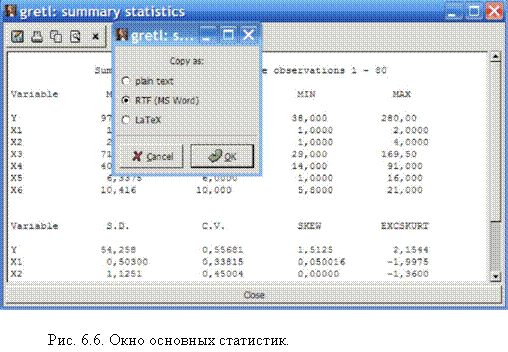
Копия результатов приведена ниже в табл. 6.1.
Таблица 6.1.
 Основные статистики исследуемых переменных. Полная выборка.
Основные статистики исследуемых переменных. Полная выборка.
| X4 | 40,8312 | 38,4000 | 14,0000 | 91,0000 |
| X5 | 6,33750 | 6,00000 | 1,00000 | 16,0000 |
| X6 | 10,4163 | 10,0000 | 5,80000 | 21,0000 |
| Variable | Std. Dev. | C.V. | Skewness | Ex. kurtosis |
| Y | 54,2576 | 0,556808 | 1,51246 | 2,15444 |
| X1 | 0,502997 | 0,338149 | 0,0500156 | -1,99750 |
| X2 | 1,12509 | 0,450035 | 0,000000 | -1,36000 |
| X3 | 30,0915 | 0,423429 | 1,16395 | 1,66153 |
| X4 | 18,9478 | 0,464051 | 0,639572 | 0,00998983 |
| X5 | 3,91668 | 0,618016 | 0,365690 | -0,880473 |
| X6 | 2,94263 | 0,282504 | 1,10553 | 2,41852 |
В табл. 6.1 приведены следующие статистики:
среднее арифметическое (Mean);
медиана (Median);
минимальное значение (Minimum);
максимальное значение (Maximum);
стандартное (среднее квадратическое) отклонение (Std.
Dev.);
коэффициент вариации (C.V.);
коэффициент асимметрии (Skewness);
коэффициент концентрации (Ex. kurtosis).
Расчет коэффициентов линейного уравнения регрессии, включающего в себя все факторы.
Последовательно выбираем пункты меню [Model] —» [Ordinary Least Squares...] (рис. 6.7).
Последовательно выбираем нажатием курсора признак (Y) и факторы. Признак вводится нажатием кнопки [Choose—>], а факторы [Add->] (рис. 6.8).
Нажимаем кнопку [OK]. Появляется окно с результатами расчетов (рис. 6.9).
Копируем результаты (рис. 6.9) и вставляем их в текст (табл.
 6.2).
6.2).
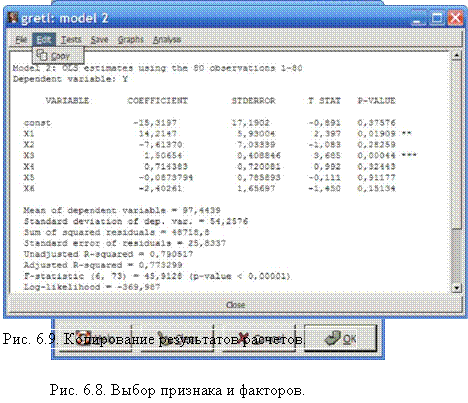 В табл. 6.2 представлены результаты расчета.
В табл. 6.2 представлены результаты расчета.
 |
 Mean of dependent variable = 97,4439 Standard deviation of dep. var. = 54,2576 Sum of squared residuals = 48718,8 Standard error of residuals = 25,8337 Unadjusted R2 = 0,790517 Adjusted R2 = 0,773299
Mean of dependent variable = 97,4439 Standard deviation of dep. var. = 54,2576 Sum of squared residuals = 48718,8 Standard error of residuals = 25,8337 Unadjusted R2 = 0,790517 Adjusted R2 = 0,773299 F-statistic (6, 73) = 45,9128 (p-value < 0,00001) Log-likelihood = -369,987 Akaike information criterion = 753,974 Schwarz Bayesian criterion = 770,648 Hannan-Quinn criterion = 760,659
По данным таблицы можно записать уравнение регрессии: y= -15,3197 + 14,21 47-jcj -7,61 37-jc2 + 1,50654-x3 +
+ 0,714383-Jt4 0,087379-jc5 2,40261-jc6 Коэффициент детерминации (Adjusted R2 = 0,773299) достаточно велик. Он показывает, что уравнение регрессии на 77\% объясняет поведение признака. Случайные отклонения от расчета всего лишь 23\%.
Адекватность уравнения регрессии проверяется F-критерием Фишера. Расчетное значение F-статистики равно 45,9128, в то время как критическое значение 6,73. Т.к. расчетное значение превосходит критическое, то уравнение регрессии адекватно.
Вместе с тем следует отметить, что по результатам теста по t-критерию только два коэффициента уравнения регрессии программа признала значимыми (отмечены звездочками в табл. 6.2) (множитель при Х) и Рз (множитель при JC3).
Анализ корреляционной матрицы. Выбор значимых факторов.
Этот шаг, на самом деле, должен быть первым, поскольку наличие мультиколлинеарности может настолько сильно исказить результаты анализа, что модель будет полностью непригодна для использования, несмотря на наличие значимых коэффициентов уравнения регрессии.
 |
 |
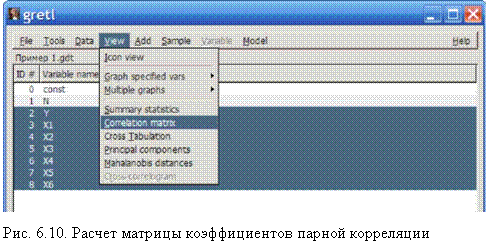
Результаты расчетов были скопированы и приведены в табл.
6.3.
Таблица 6.3.
Корреляционная матрица Correlation coefficients, using the observations 1 80 5\% critical value (two-tailed) = 0,2199 for n = 80
| Y | X1 | X2 | X3 | X4 | X5 | X6 | |
| 1,0000 | 0,2028 | 0,7248 | 0,8721 | 0,8536 | 0,0214 | 0,4856 | Y |
| 1,0000 | 0,1007 | 0,0693 | 0,0996 | -0,1938 | -0,0225 | X1 | |
| 1,0000 | 0,8091 | 0,8909 | -0,0158 | 0,2223 | X2 | ||
| 1,0000 | 0,9546 | 0,0835 | 0,6327 | X3 | |||
| 1,0000 | 0,0021 | 0,5062 | X4 | ||||
| 1,0000 | 0,1501 | X5 | |||||
| 1,0000 | X6 |
2. Анализ корреляционной матрицы показывает, что факторы
Х1 и Х5 слабо связаны с признаком и их можно не включать в модель (расчеты программы показали, что если |r|<0,2199, то этот коэффициент парной корреляции следует считать незначимым).
Можно также заметить, что три фактора Х2, Х3, Х4 тесно связаны между собой (коэффициенты парной корреляции превышают 0,8), т.е. наблюдаем явление мулътиколлинеарности. Для устранения этого явления удалим из модели факторы Х2 и Х4 (они слабее связаны с признаком Y).
3. Проведем новые расчеты с оставшимися факторами Х3 и Х6.
Результаты расчета коэффициентов модели приведены в табл.
6.4.
Таблица 6.4.
Линейная модель с неколлинеарными и значимыми факторами
Model 2: OLS estimates using the 80 observations 1-80
Dependent variable: Y
Variable Coefficient Std. Error t-statistic p-value
***
const -2,05977 10,9624 -0,1879 0,85145
X3 1,6984 0,127836 13,2858 <0,00001
X6 -2,03482 1,30725 -1,5566 0,12368
Mean of dependent variable = 97,4439 Standard deviation of dep. var. = 54,2576 Sum of squared residuals = 53980,6 Standard error of residuals = 26,4773
Unadjusted R2 = 0,767892
Adjusted R2 = 0,761863
F-statistic (2, 77) = 127,371 (p-value < 0,00001)
Log-likelihood = -374,089
Akaike information criterion = 754,178 Schwarz Bayesian criterion = 761,324 Hannan-Quinn criterion = 757,043
Анализ результатов показывает, что уравнение регрессии адекватно, т.к. расчетное значение критерия Фишера равно 127,371, в то время как критическое 2,77, что существенно меньше.
Коэффициент детерминации R = 0,761863 достаточно велик, хотя и уменьшился на 0,012, по сравнению с полной моделью.
Также можно заметить, что по критерию Стьюдента лишь один коэффициент (множитель при Х3) уравнения регрессии является значимым. Таким образом, мы получили, что именно общая площадь квартиры почти полностью определяет ее цену.
Сравнение цен по городам
1. Выделим данные только для Подольска. Они характеризуются значением параметра Х1=1.
Выделение группы данных осуществляется через меню [Sam-pie] —> [Restrict, based on criterion...] (рис. 6.12).
| File Tools Data View Add | 1 Variable Model | |
| Пример l.gdt | Set range... Restore full range | |
| ID £ Variable name Descriptive 1 | ||
| 0 const auto-gener; 1 N | Define, based on dummy... | |
| Restrict, based on criterion... | ||
| 2 Y 3 XI 4 X2 5 X3 6 X4 | 1 Random sub-sample... 1 Drop all obs with missing values 1 Count missing values 1 Set missing value code... | |
Рис. 6.12. Выделение подвыборки по критерию. Появляется окно определения критерия отбора (рис 6.13):
 После ввода критерия отбора снова рассчитываются основные статистики (табл. 6.5).
После ввода критерия отбора снова рассчитываются основные статистики (табл. 6.5).
2. Проделаем ту же операцию для Люберец: Х1=2.
Окно ввода критерия отбора содержит теперь дополнительное услвие: [add to current restriction] и [replace current restriction] («добавить в существующее ограничение» и «заменить существующее ограничение») (рис. 6.14). Выбираем пункт «заменить».
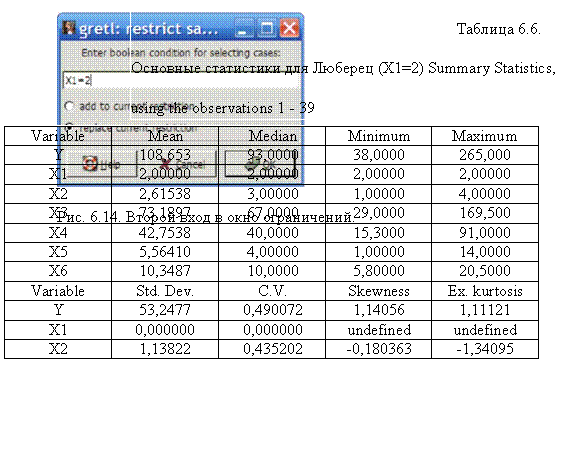 Результаты расчета основных статистик для Люберец приведены в табл. 6.6.
Результаты расчета основных статистик для Люберец приведены в табл. 6.6.
| X3 | 32,0682 | 0,438151 | 1,11674 | 1,40541 |
| X4 | 20,1908 | 0,472257 | 0,581823 | -0,216828 |
| X5 | 3,71196 | 0,667127 | 0,512349 | -0,976710 |
| X6 | 3,42221 | 0,330689 | 0,852933 | 0,627740 |
3. Сравнение цен в двух городах.
По табл. 6.5 и табл.6.6 можно заметить, что средняя цена квартиры в Люберцах (108,653) превышает то же в Подольске (86,7817).
Возникает вопрос, насколько значимо это превышение.
С этой целью проведем оценку значимости отклонения по t-критерию Стьюдента. Для этого воспользуемся меню [Tools] —> [Test statistic calculator] (рис. 6.14).
После выбора меню [Test statistic calculator] появляется окно ввода данных (рис. 6.15). В нем вверху имеется ряд закладок, среди которых мы выбираем закладку [2 means] (двухвыборочное среднее).
Затем по очереди в каждом окне и для обеих выборок вводим последовательно соответствующие значения: среднее, стандартное отклонение, объем выборки. После нажатия кнопки [OK] появляются результаты расчета (рис. 6.16).
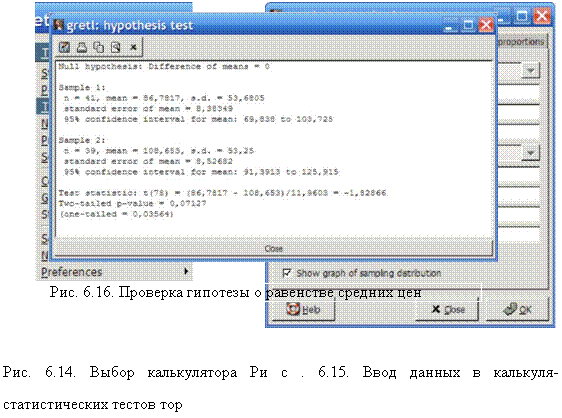 На рис. 6.16 главное для нас это строка с записью «Two-tailed р-value = 0,07127». Т.к. р>а=0,05, то отклонение средних друг от друга незначимо. Таким образом, гипотеза о независимости цен от города принимается.
На рис. 6.16 главное для нас это строка с записью «Two-tailed р-value = 0,07127». Т.к. р>а=0,05, то отклонение средних друг от друга незначимо. Таким образом, гипотеза о независимости цен от города принимается.
Проверка нормальности и гомоскедастичности остатков
 Для проведения тестов на гетероскедастичность (нарушение гомоскедастичности) и нормальность остатков в окне модели выбираем меню [Tests] -» [Heterosctdasticity] или [Tests] -» [Normality of residual] соответственно (рис. 6.17).
Для проведения тестов на гетероскедастичность (нарушение гомоскедастичности) и нормальность остатков в окне модели выбираем меню [Tests] -» [Heterosctdasticity] или [Tests] -» [Normality of residual] соответственно (рис. 6.17).
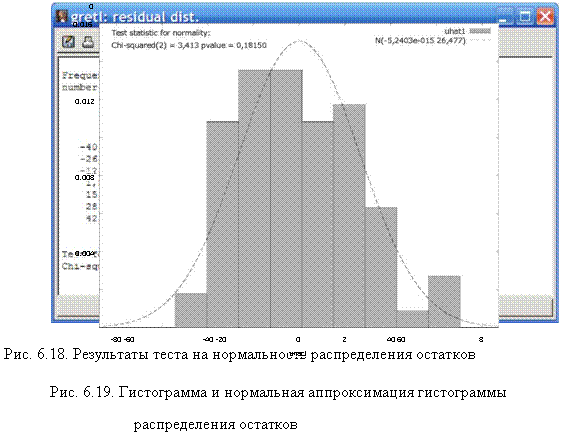
Результаты теста на нормальность распределения остатков приведены на рис. 18 и рис. 6.19. Т.к. p-value = 0,1815 > а = 0,05, то гипотезу о нормальности принимаем.
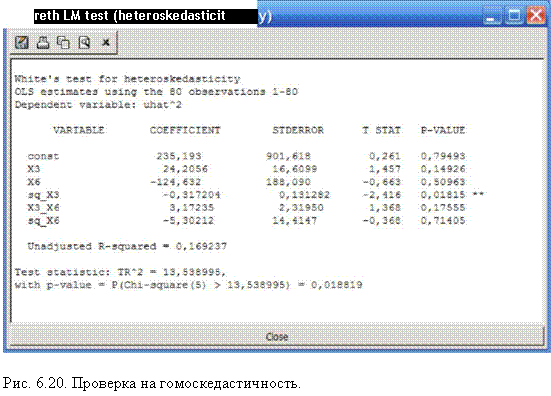
Результаты теста на гетероскедастичность приведены на рис.
6.20.
При доверительном уровне а = 0,05 наблюдается гетероскедастичность (нарушена гомоскедастичность) по фактору Х3.
 |
Установлено, что цена квартиры зависит только от общей площади. Коэффициент уравнения регрессии при факторе Х6 (площадь кухни) незначимо отличается от нуля.
Установлено, что полученная модель является адекватной по критерию Фишера.
Установлено, что разница в ценах в двух городах несущественна.
Установлено, что модель соответствует общим требованиям по нормальности остатков, но слегка нарушена гомоскедастичность.

Обсуждение Математика в экономике
Комментарии, рецензии и отзывы