56. метод максимума правдоподобия
56. метод максимума правдоподобия
Метод максимума правдоподобия (maximum likelihood function) применяется для определения неизвестных коэффициентов модели регрессии и является альтернативой методу наименьших квадратов. Суть данного метода состоит в максимизации функции правдоподобия или её логарифма.
Общий вид функции правдоподобия:
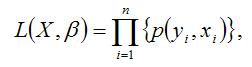
где
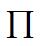
– это геометрическая сумма, означающая перемножение вероятностей по всем возможным случаям внутри скобок.
Предположим, что на основании полученных данных была построена модель регрессии бинарного выбора, где результативная переменная представлена с помощью латентной переменной:
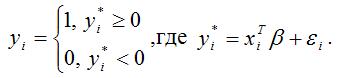
Следовательно, вероятность события, что результативная переменная yi примет значение, равное единице, можно выразить следующим образом:
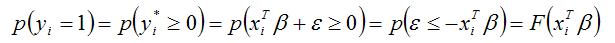
Вероятность события, что результативная переменная yi примет значение, равное нулю, можно выразить следующим образом:
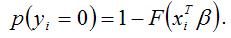
В связи с тем, что для вероятностей считается справедливым равенство вида:
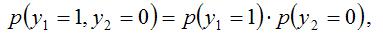
функция правдоподобия может быть записана как геометрическая сумма вероятностей наблюдений:
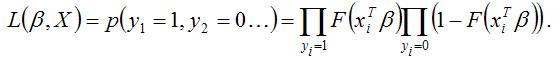
Для логит-регрессии и пробит-регрессии функция правдоподобия строится через сумму натуральных логарифмов правдоподобия следующим образом:
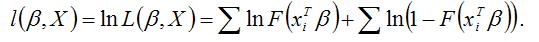
Оценки неизвестных параметров логит-регрессии и пробит-регрессии определяются с помощью максимизации функции правдоподобия:
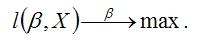
Для определения максимума функции l(β,X) необходимо вычислить частные производные этой функции по каждому из оцениваемых параметров и приравнять их к нулю. Результатом данной процедуры будет стационарная система уравнений:
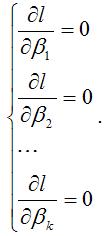
С помощью преобразований данной системы уравнений переходим к системе нормальных уравнений, решениями которой и будут оценки максимального правдоподобия
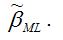
Прежде, чем использовать пробит-регрессию и логит-регрессию для прогнозирования или анализа, необходимо проверить значимость вычисленных коэффициентов пробит и логит регрессий и моделей регрессии в целом. Подобная проверка осуществляется с помощью величины (l1-l0), где параметр l1 соответствует максимально правдоподобной оценке основной модели регрессии, а параметр l0 – оценка нулевой модели регрессии, т. е. yi=β0.
При проверке значимости коэффициентов пробит или логит-регрессии выдвигается основная гипотеза о незначимости данных коэффициентов:
H0:β1=β2=…=βk=0.
Тогда конкурирующей или альтернативной гипотезой будет гипотеза вида:
H1:β1≠β2≠…≠βk≠0.
Для проверки выдвинутых гипотез рассчитывается величина H=-2(l1–l0), которая распределена по χ2закону распределения с k степенями свободы.
Критическое значение χ2-критерия определяется по таблице по β2распределения в зависимости от заданного значения вероятности а и степени свободы k.
При проверке гипотез возможны следующие ситуации:
Если величина H больше критического значение χ2-критерия, т.е.
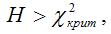
то основная гипотеза отвергается, и коэффициенты модели регрессии являются значимыми. Следовательно, модель пробит или логит-регрессии также является значимой.
Если величина H меньше критического значение β2-критерия, т. е.
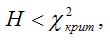
то основная гипотеза принимается, и коэффициенты модели регрессии являются незначимыми. Следовательно, модель пробит или логит-регрессии также является незначимой.
Оценки неизвестных коэффициентов модели регрессии, полученные методом максимума правдоподобия, удовлетворяют следующему утверждению.
Пусть ω – это элемент, принадлежащий заданному пространству А. Если А является открытым интервалом, а функция L(ω) дифференцируема и достигает максимума в заданном интервале A, то оценки максимального правдоподобия удовлетворяют равенству вида:
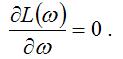
Докажем данное утверждение на примере модели логит-регрессии.
Функция максимального правдоподобия для модели логит-регрессии имеет вид:
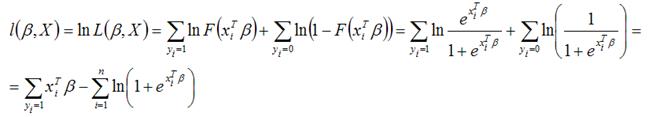
Продифференцируем полученную функцию по параметру β:
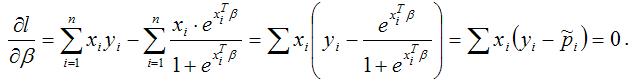
Следовательно, утверждение можно считать доказанным.
В том случае, если для модели регрессии справедливы предпосылки нормальной линейной модели регрессии, то оценки неизвестных коэффициентов, полученные с помощью метода наименьших квадратов, и оценки, полученные с помощью метода максимума правдоподобия, будут совпадать.
57. Гетероскедастичность остатков модели регрессии
Случайной ошибкой называется отклонение в линейной модели множественной регрессии:
εi=yi–β0–β1x1i–…–βmxmi
В связи с тем, что величина случайной ошибки модели регрессии является неизвестной величиной, рассчитывается выборочная оценка случайной ошибки модели регрессии по формуле:
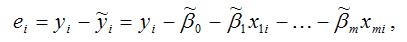
где ei – остатки модели регрессии.
Термин гетероскедастичность в широком смысле понимается как предположение о дисперсии случайных ошибок модели регрессии.
При построении нормальной линейной модели регрессии учитываются следующие условия, касающиеся случайной ошибки модели регрессии:
6) математическое ожидание случайной ошибки модели регрессии равно нулю во всех наблюдениях:
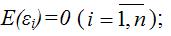
7) дисперсия случайной ошибки модели регрессии постоянна для всех наблюдений:
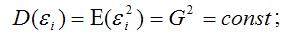
8) между значениями случайных ошибок модели регрессии в любых двух наблюдениях отсутствует систематическая взаимосвязь, т. е. случайные ошибки модели регрессии не коррелированны между собой (ковариация случайных ошибок любых двух разных наблюдений равна нулю):

Второе условие
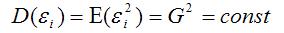
означает гомоскедастичность (homoscedasticity – однородный разброс) дисперсий случайных ошибок модели регрессии.
Под гомоскедастичностью понимается предположение о том, что дисперсия случайной ошибки βi является известной постоянной величиной для всех наблюдений.
Но на практике предположение о гомоскедастичности случайной ошибки βi или остатков модели регрессии ei выполняется не всегда.
Под гетероскедастичностью (heteroscedasticity – неоднородный разброс) понимается предположение о том, что дисперсии случайных ошибок являются разными величинами для всех наблюдений, что означает нарушение второго условия нормальной линейной модели множественной регрессии:
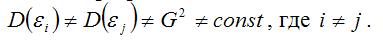
Гетероскедастичность можно записать через ковариационную матрицу случайных ошибок модели регрессии:
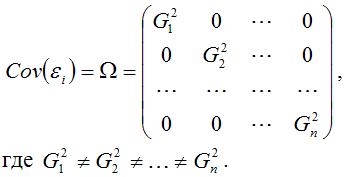
Тогда можно утверждать, что случайная ошибка модели регрессии βi подчиняется нормальному закону распределения с нулевым математическим ожиданием и дисперсией G2Ω:
εi~N(0; G2Ω),
где Ω – матрица ковариаций случайной ошибки.
Если дисперсии случайных ошибок
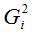
модели регрессии известны заранее, то проблема гетероскедастичности легко устраняется. Однако в большинстве случаев неизвестными являются не только дисперсии случайных ошибок, но и сама функция регрессионной зависимости y=f(x), которую предстоит построить и оценить.
Для обнаружения гетероскедастичности остатков модели регрессии необходимо провести их анализ. При этом проверяются следующие гипотезы.
Основная гипотеза H0 предполагает постоянство дисперсий случайных ошибок модели регрессии, т. е. присутствие в модели условия гомоскедастичности:
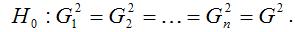
Альтернативная гипотеза H1 предполагает непостоянство дисперсиий случайных ошибок в различных наблюдениях, т. е. присутствие в модели условия гетероскедастичности:
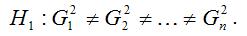
Гетероскедастичность остатков модели регрессии может привести к негативным последствиям:
1) оценки неизвестных коэффициентов нормальной линейной модели регрессии являются несмещёнными и состоятельными, но при этом теряется свойство эффективности;
2) существует большая вероятность того, что оценки стандартных ошибок коэффициентов модели регрессии будут рассчитаны неверно, что конечном итоге может привести к утверждению неверной гипотезы о значимости коэффициентов регрессии и значимости модели регрессии в целом.

Обсуждение Ответы на экзаменационные билеты по эконометрике
Комментарии, рецензии и отзывы