1.5. проверка выполнения стандартных предположений
1.5. проверка выполнения стандартных предположений
При анализе обычных линейных моделей регрессии проверка выполнения стандартных предположений осуществляется посредством графического анализа и различных статистических критериев, призванных выявить наличие таких особенностей статистических данных, которые могут говорить не в пользу гипотезы о выполнении стандартных предположений.
Посмотрим, однако, на график остатков для пробит-модели, оцененной по рассматривавшемуся выше множеству данных о наличии (отсутствии) собственных автомобилей у 1000 семей.
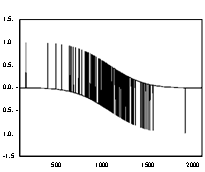 |
Поскольку мы используем для оценивания модели бинарного выбора метод максимального правдоподобия, естественным представляется сравнение максимумов функций правдоподобия, получаемых при оценивании модели с выполненными стандартными предположениями и при оценивании модели, в которой эти предположения не выполняются. При этом предполагается, что эти две модели гнездовые, т.е. первая вложена во вторую, так что вторая модель является более сложной, а первая является частным случаем второй модели.
Здесь надо заметить, что сравнением максимумов правдоподобий в двух гнездовых моделях мы фактически уже пользовались выше. Действительно, на таком сравнении основаны определения коэффициентов pseudoR = 1 -, г—
1 + 2(lnЦ lnL0)/n
и
McFaddenR 2 = 1 -lnL-.
lnL0
В этом случае в качестве гнездовых моделей рассматриваются основная модель (с одной или несколькими объясняющими переменными помимо константы) и вложенная в нее тривиальная модель (в правую часть в качестве объясняющей переменной включается только константа).
Кроме того, если две гнездовые модели сравниваются с использованием информационных критериев (Акаике, Шварца, Хеннана-Куинна), то такое сравнение опять сводится к сравнению максимумов функций правдоподобия в этих моделях.
В этом разделе мы сосредоточимся на некоторых статистических критериях проверки гипотез о выполнении стандартных предположений, но прежде чем перейти к рассмотрению и применению подобных критериев, мы рассмотрим процесс порождения данных, приводящий к пробит-модели.
Предположим, что переменная у* характеризует "полезность" наличия некоторого предмета длительного пользования для i -й семьи, и эта полезность определяется соотношением
y* = Ахд + ••• + PpXip +£,, ' =1 n, где xi1,. , xip значения p объясняющих переменных для i -й
семьи, £b...,£n случайные ошибки, отражающие влияние на полезность наличия указанного предмета для i -й семьи каких-то неучтенных дополнительных факторов. Пусть i -я семья приобретает этот предмет длительного пользования, если у* > у, где у " пороговое значение, и индикаторная переменная yt отмечает наличие (y i = 1) или отсутствие (y i = 0) данного предмета у i -й семьи. Тогда
Py, =1 xi}= p{y*>r xi}= p{p1xn + L + Ppx,p +£,>У,xi}=
= p{el>rl-p1x4 fipxipxi },
и если xi1 = 1, то
P[yt = 1 xi}=P{et >(y Д )-(P2x,2 + l + Pvxp) x,}.
Если предположить, что ошибки є1,...,єп независимые в совокупности (и независимые от xj, j = 1,...,p ) случайные величины, имеющие одинаковое нормальное распределение et ~ N (0, a2), то тогда
P[y, = 1 x }= 1 Ф
f (їі-в. ) (P2xi2 + ^ + [lpxip ^
a a
Ф
+
aa
(Здесь мы использовали вытекающее из симметрии стандартного нормального распределения соотношение 1 Ф(x) = Ф(-x).) Обозначая
в = (-ї+в), в =в,
a 3 a '
получаем:
P[y, = 1 x i }= Ф(в x,1 + ^ + epx v ) = Ф^в).
Но именно таким образом и определяется пробит-модель.
Пусть мы имеем в наличии только значения yi, xл,..., xpp, а
значения y* не доступны наблюдению. В таком случае переменную
y* называют латентной (скрытой) переменной. Применяя метод
максимального правдоподобия, мы получаем оценки параметров пробит-модели в1, к, в , но не можем однозначно восстановить по ним значения параметров Д,...,/?р, если не известны значения о и
Y,...,7n • Действительно, если оценки о, Y,...,fn , Л,"-, Л p таковы, что
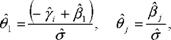
то к тем же значениям ..., в приводят и оценки ко, kf1,..., kyYn ,
Л, к, k/?p , где к произвольное число, °° < к<
Таким образом, в рассмотренной ситуации для однозначной идентификации коэффициентов 1,. , p необходима какая-то
нормализация функции полезности. В стандартной модели предполагается, что о = 1 и у1 = ••• = yn = 0, так что
Л = в1," •, Л p =в p , и именно такую модель мы будем теперь рассматривать.
Прежде всего заметим, что при получении оценок параметров 1, . , p в такой модели методом максимального правдоподобия
мы принципиально опираемся на предположение о нормальности ошибок є1,к,єп: єі~N(0,1)• Поэтому важной является задача проверки этого предположения, т.е. проверка гипотезы Я0: Є,...,Єп~ i.i.d., є,~N(0,1).
Наряду со стандартной моделью (модель 1) рассмотрим модель 2, отличающуюся от стандартной тем, что в ней
Р[є, < t} = 0>(t + щґ2 + co2t3), так что
Py, = 1 x,}= <ї(xTв + щ(хт1 в) + Щ(xTв)) .
При этом модель 1 является частным случаем модели 2 (при (1 =в)2 = 0), так что модель 1 и модель 2 гнездовые модели, и в
рамках более общей модели 2 гипотеза H0 принимает вид
H 0:(о1 =(02 = 0 .
Класс распределений вида P{ei < t}= ф( t + (01t2 + (2t3) допускает
асимметрию и положительный эксцесс (островершинность) распределения. Следующий график позволяет сравнить поведение функции стандартного нормального распределения ) (толстая
линия) и функции ф( t + 0.5t2 + 0.5t3) (тонкая линия).
0.8J
0.6J
0.4J
0.2J
0.0Ц.
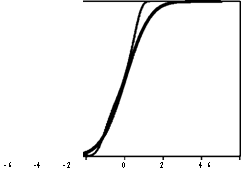
1.0-,
Пусть Lj максимум функции правдоподобия в модели j, j = 1,2 , и LR = 2(ln L2 In L1). Критерий отношения правдоподобий отвергает гипотезу H0 , если наблюдаемое значение статистики LR превышает критическое значение LRcrit, соответствующее выбранному уровню значимости а. Этот критерий асимптотический: критическое значение LRcrU вычисляется на основе распределения, к которому стремится при n — °° распределение статистики LR, если гипотеза H0 верна. Этим предельным распределением является распределение хи-квадрат с двумя степенями свободы. Итак, в соответствии с критерием отношения правдоподобий, гипотеза H0 отвергается, если
LR >ХІа(2),
где Хі2-а(2) квантиль уровня 1 -а распределения хи-квадрат с двумя степенями свободы.
Обратимся опять к смоделированным данным о наличии или отсутствии собственных автомобилей у 1000 домохозяйств.
Оценивая пробит-модель (модель 1) по этим данным, мы получили следующие результаты:
| Коэффициент | Оценка | Std. Error z-Statistic | Prob. |
| а | -3.503812 | 0.200637 -17.46343 | 0.0000 |
| в | 0.003254 | 0.000178 18.25529 | 0.0000 |
| ln l | -275.7686 | Akaike info criterion | 0.555537 |
| Schwarz criterion | 0.565353 | ||
| Hannan-Quinn criter. | 0.559268 | ||
| Оценивание модели 2 дает следующие результаты: | |||
| Коэффициент | Оценка | Std. Error z-Statistic | Prob. |
| а | -3.851178 | 0.324895 -11.85359 | 0.0000 |
| в | 0.003540 | 0.000292 12.11708 | 0.0000 |
| 0.022954 | 0.025086 0.915039 | 0.3602 | |
| -0.017232 | 0.010178 -1.693097 | 0.0904 | |
| -274.6286 | Akaike info criterion | 0.557257 | |
| Schwarz criterion | 0.576888 | ||
| Hannan-Quinn criter. | 0.564718 | ||
Соответственно, здесь
LR = 2(lnL2 lnL1) = 2(275.7686 274.6286) = 2.28 .
Поскольку же \%0>95 (2) = 5.99, то критерий отношения правдоподобий не отвергает гипотезу H0 при уровне значимости 0.05. Заметим еще, что значению LR = 2.28 соответствует (вычисляемое по асимптотическому распределению X (2)) P -значение 0.6802. Таким образом, критерий отношения правдоподобий не отвергает гипотезу H0 при любом разумном уровне значимости.
Еще одним "стандартным предположением" является предположение об одинаковой распределенности случайных ошибок єі в процессе порождения данных. В сочетании с предположением нормальности этих ошибок, данное условие сводится к совпадению дисперсий всех этих ошибок. Нарушение этого условия приводит к гетероскедастичной модели и к несостоятельности оценок максимального правдоподобия, получаемых на основании стандартной модели. Для проверки гипотезы совпадения дисперсий мы можем опять рассмотреть какую-нибудь более общую модель с наличием гетероскедастичности, частным случаем которой является стандартная пробит-модель.
В примере с автомобилями можно допустить, что дисперсии случайных ошибок в процессе порождения данных возрастают с возрастанием значений x , например, как
Z)( |x;.) = exp(k xt), к > 0 ,
так что (модель 3)
yjexp(kx,)
Здесь мы имеем две гнездовые модели модель 3, допускающую гетероскедастичность в указанной форме, и модель 1 (стандартную
 LR = 2(lnL3 lnL) = 2(275.2619 274.6286) = 1.27. Это значение меньше критического значения 3.84, соответствующего уровню значимости 0.05 и вычисленного как квантиль уровня 0.95 асимптотического распределения хи-квадрат с одной степенью свободы. Следовательно, гипотеза H0 : к = 0 не отвергается.
LR = 2(lnL3 lnL) = 2(275.2619 274.6286) = 1.27. Это значение меньше критического значения 3.84, соответствующего уровню значимости 0.05 и вычисленного как квантиль уровня 0.95 асимптотического распределения хи-квадрат с одной степенью свободы. Следовательно, гипотеза H0 : к = 0 не отвергается.
Отметим, что решения, принятые нами на основании критерия отношения правдоподобий, согласуются с решениями, принимаемыми в рассматриваемом примере на основании информационных критериев:
| AIC | SC | HQ | |
| Модель 1 (пробит) | 0.555537 | 0.565353 | 0.559268 |
| Модель 2 | 0.557257 | 0.576888 | 0.564718 |
| Модель 3 (гетеро) | 0.556524 | 0.571247 | 0.562120 |
По всем трем критериям стандартная пробит-модель предпочтительнее альтернативных моделей.

Обсуждение Эконометрика для начинающих (Дополнительные главы)
Комментарии, рецензии и отзывы