Раздел 4 проверка выполнения стандартных предположений о модели наблюдений тема 4.1 графические методы
Раздел 4 проверка выполнения стандартных предположений о модели наблюдений тема 4.1 графические методы
Рассмотренный комплекс процедур получения статистических выводов для моделей простой или множественной регрессии опирается на вполне определенные стандартные предположения о модели наблюдений (линейная модель, независимые нормально распределенные ошибки с нулевыми математическими ожиданиями и одинаковыми дисперсиями).
В связи с этим большие значения коэффициента детерминации R2 (близкие к 1) или статистическая значимость всех коэффициентов вовсе не обязательно говорят о том, что подобранная модель вполне соответствует характеру имеющихся статистических данных, воспроизводит глобальные особенности имеющихся статистических данных — адекватна статистическим данным (adequate model) — и для нее можно использовать указанный комплекс статистических процедур.
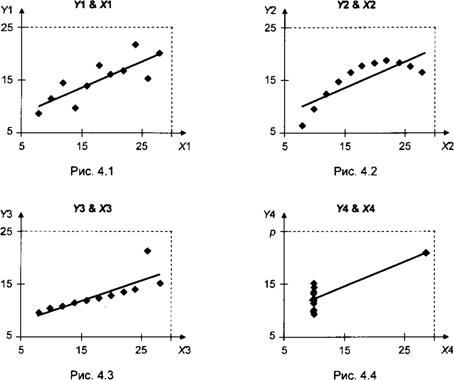
В этом отношении весьма поучителен искусственный пример с 4 различными множествами данных (табл. 4.1), которые имеют качественно различные диаграммы рассеяния и в то же время приводят при использовании модели наблюдений
yi =a + pxt +£,., / = 1,...,л,
к одним и тем же (в пределах двух знаков после запятой) оценкам параметров, значениям коэффициента R2 и ^-статистик. Для всех 4 множеств:
подобранная модель линейной связи имеет вид^ = 6.00 + 0.50х;
а имеет (оцененную) стандартную ошибку s& = 1.12;
Р имеет (оцененную) стандартную ошибку Sp = 0.12;
 /-статистика для проверки нулевой гипотезы Н0 : а 0 равна 2.67, что соответствует Р-значению 0.026;
/-статистика для проверки нулевой гипотезы Н0 : а 0 равна 2.67, что соответствует Р-значению 0.026;
/-статистика для проверки нулевой гипотезы Н0 : J3= 0 равна 4.24, что соответствует Р-значению 0.002;
R2 = 0.67.
Однако диаграммы рассеяния различаются коренным образом (рис. 4.1—4.4).
Уже чисто визуальный анализ 4 диаграмм рассеяния показывает, что только первое множество данных (рис. 4.1) можно признать удовлетворительно описываемым линейной моделью наблюдений
yt = <* + /?х,. +£,., i = l,...,n.
Для второго множества (рис. 4.2) более подходящей представляется модель
yi =а + pxt+yx2 +єі9 / = 1,...,л.
В третьем множестве (рис. 4.3) явно выделяется одна точка (3-е наблюдение), которая существенно влияет на наклон и положение подбираемой прямой.
Четвертое множество (рис. 4.4) совершенно непригодно для подбора линейной зависимости, поскольку наклон подобранной прямой фактически определяется наличием одного выпадающего наблюдения.
Метод наименьших квадратов достаточно устойчив к малым отклонениям от стандартных предположений в том смысле, что при таких малых отклонениях статистические выводы на основе статистического анализа модели
в основном сохраняются. Однако существенные отклонения от стандартных предположений могут серьезно исказить статистические выводы. Возможные последствия таких отклонений:
оценки ви вр коэффициентов линейной модели, построенные на базе стандартных предположений, оказываются смещенными;
оценки дисперсий случайных величин в19 вр (оценок коэффициентов линейной модели), построенные на базе стандартных предположений, оказываются смещенными;
построенные на базе стандартных предположений доверительные интервалы для ви вр не соответствуют заявленным уровням значимости;
вычисленные значения tи F-отношений нельзя рассматривать как наблюдаемые значения случайных величин, имеющих tи F-распределе-ния. Поэтому при сравнении вычисленных значений tи F-отношений с квантилями указанных и ^-распределений можно прийти к ошибочным статистическим выводам о гипотезах о значениях коэффициентов линейной модели;
прогнозы, построенные по подобранной модели, оказываются смещенными.
В связи с этим, необходимо иметь инструментарий:
для обнаружения отклонений от стандартных предположений, или, говоря иначе, для проведения диагностики подобранной модели {diagnostic for model misspecification);
• для коррекции выявленных отклонений от стандартных предположений,
позволяющий проводить строгий и информативный анализ статистических данных.
В конечном счете, диагностические процедуры предназначены для проверки гипотезы о том, что выполнены все стандартные предположения о модели. В то же время они помогают выявить характер нарушений этих предположений, если таковые обнаружены, а это позволяет изменить в правильном направлении спецификацию модели или соответствующим образом скорректировать статистические выводы. Специализированные диагностические процедуры, рассмотренные ниже, направлены на выявление следующих типов нарушений стандартных предположений:
отличие распределения ошибок от нормального;
неодинаковые дисперсии ошибок;
статистическая зависимость ошибок в наблюдениях, производимых в последовательные моменты времени;
неправильный выбор функциональной формы модели;
непостоянство коэффициентов модели на периоде наблюдений.
При выявлении некоторых типов нарушений стандартных предположений можно, в принципе, не изменяя спецификации модели, ограничиться лишь коррекцией статистических выводов в отношении подобранной модели (например, соответствующим образом корректируя значения используемых ґ-ста-тистик, о чем будет сказано ниже). Однако методология эконометрических исследований, известная как методология Лондонской школы экономики (LSE approach; LSE — London School of Economics), предлагает другой подход. При обнаружении нарушений стандартных предположений следует изменить спецификацию модели таким образом, чтобы при оценивании модели с измененной спецификацией нарушения стандартных предположений уже не выявлялись, по крайней мере, теми диагностическими процедурами, которые имеются в распоряжении исследователя. Таких процедур в распоряжении исследователя должно быть достаточно много для того, чтобы выявлять различные типы нарушений, и эти процедуры должны быть по возможности достаточно эффективными, чтобы можно было обнаруживать нарушения стандартных предположений и при не очень большом количестве наблюдений. Основатель и пропагандист этого подхода Девид Хендри указывает в связи с этим на «три золотых правила эконометрики»: проверка, проверка и проверка (test, test and test) (см. (Hendry, 2003), с. 27—28).
Согласно методологии Лондонской школы экономики модели, которые претендуют на научность, должны:
успешно проходить диагностические процедуры;
объяснять результаты предыдущих исследований;
быть обоснованными с точки зрения экономической теории.
Эффективным средством обнаружения отклонений от стандартных предположений о линейной модели наблюдений
у і = +... + врхф +єі9 / = 1,...,и,
т.е.
у = Хв + є,
является анализ остатков (residual analysis), т.е. анализ разностей
єі=Уі-Уі> / = 1,...,л.
Наблюдаемые разности yt yt в силу случайности значений st в модели наблюдений можно рассматривать как значения соответствующих случайных величин Yt-Yi9 за которыми сохраним те же обозначения et. Соответственно вектор остатков
е = у-Хв = уХ(ХТХУХ Хт у = (1Х(ХТХУ1 Хт )у = (1Н)у
можно рассматривать как реализацию случайного вектора, за которым сохраним то же обозначение е.
Если выполнены наши стандартные предположения о модели наблюдений, то случайный вектор е имеет математическое ожидание
Е(е) = Е(у-Хв) = Е(Хв + є-Хв) = Хв-Хв = 0 и ковариационную матрицу
Cov(e) = Cov((I Н)у) = (/ H)Cov(y)(I Н)т = = ст2(ІН)(1 Н)т = а2 (I Н).
Это означает, что для компонент этого случайного вектора, т.е. для остатков ei9 имеем:
Е(е() = 0, / = 1,...,и, D(ei) = <j\-hii), / = 1,...,л, где hu — і-й диагональный элемент квадратной (п х «)-матрицы
н = х(хтху1хт.
Таким образом, несмотря на то что дисперсии ошибок є{ равны между собой при наших предположениях (все они равны <т2), дисперсии остатков, вообще говоря, различны.
Для выравнивания дисперсий можно перейти к рассмотрению нормированных остатков
Є; Є;
т.е. остатков, деленных на их стандартные отклонения. Для таких остатков
D
= 1, 1 = 1,...,л.
Поскольку значение <т2 опять неизвестно, вместо нормированных остатков приходится использовать стьюдентизированные остатки (studentized residuals)
df=—Д=> і = 1,..., л, где, как обычно, S2 = .
Во многих пакетах программ величины hu в знаменателе правой части выражения для dt игнорируются, что приводит к так называемым стандартизованным остаткам (standardized residuals)
Сі =-S / = 1,...,л
(так сделано, например, в пакетах Excel и Econometric Views).
Практический анализ показывает, что графики остатков dt и с, обычно (но отнюдь не всегда!) несущественно различаются по характеру поведения. Поэтому для предварительного графического анализа адекватности (graphical diagnostic analysis) часто можно удовлетвориться и значениями сі9 і = 1, п.
К тому же поскольку Н = Х(ХТХ)~ХХТ — проекционная матрица, ранг этой матрицы равен ее следу. Так как проектирование производится на линейное подпространство размерности р (р — количество объясняющих переменных), ранг матрицы Н равен р,
п
/=і
так что если р «п (р намного меньше п то «в среднем» значения hn достаточно малы.
Графики стандартизованных (стьюдентизированных) остатков позволяют выявлять типичные отклонения от стандартных предположений о модели наблюдений по характеру поведения остатков. При этом имеется в виду, что, по крайней мере, при большом количестве наблюдений поведение остатков еі9 і = 1, п9 должно в той или иной степени имитировать поведение ошибок єі9 і = 1, п. Иначе говоря, поскольку предполагается, что ошибки єі9 і = 1,п9 — независимые в совокупности случайные величины, имеющие одинаковое нормальное распределение N(09 <т2), ожидается, что поведение последовательности остатков еі9 і = 1, п9 должно имитировать поведение последовательности независимых в совокупности случайных величин, имеющих одинаковое нормальное распределение N(09 а2). Соответственно от стандартизованных остатков можно было бы ожидать поведения, похожего на поведение последовательности независимых в совокупности случайных величин, имеющих одинаковое стандартное нормальное распределение N(09 1).
Строго говоря, последнее ожидание не вполне оправданно. Хотя стандартизованные остатки и имеют распределения, близкие (хотя бы при больших п) к стандартному нормальному, они не являются взаимно независимыми случайными величинами. Это можно понять хотя бы из того, что (как мы помним) при использовании оценок наименьших квадратов алгебраическая сумма остатков равна нулю, так что каждый остаток линейно выражается через остальные остатки. Тем не менее при большом количестве наблюдений наличие такого соотношения между остатками практически не делает картину поведения стандартизованных остатков сколь-нибудь существенно отличной от поведения последовательности независимых в совокупности случайных величин, имеющих одинаковое стандартное нормальное распределение N(09 1).
Наиболее часто для диагностики (для проверки на наличие) типичных отклонений используют графики зависимости стандартизованных остатков (как ординат) от:
оцененных значений yt = вххп + ... + врхір9
отдельных объясняющих переменных;
номера наблюдения, если наблюдения производятся в последовательные моменты времени с равными интервалами.
График зависимости с, от yi = 0xxlX + ... + врхір позволяет выявлять 3 довольно распространенных нарушения стандартных предположений классической модели.
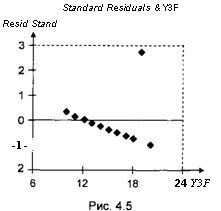
Выделяющиеся наблюдения (outliers) — наличие наблюдений, для которых либо математическое ожидание ошибки Efa) существенно отличается от 0, либо дисперсия ошибки D(st) существенно превышает величину <т2 дисперсий остальных ошибок. Подобные наблюдения могут выявляться на графике как наблюдения со «слишком большими» по абсолютной величине остатками. Такая ситуация возникает, например, при подборе прямой по третьему (из 4 рассмотренных выше) множеству данных (рис. 4.5).
 | 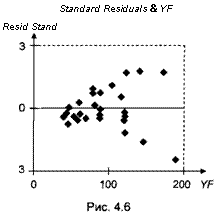 | ||
с t от у і = вххІХ + ... + в хір имеет вид, как на рис. 4.6, то это, скорее всего, отражает возрастание дисперсий ошибок с ростом значений вххІХ + ... + 6рхір.
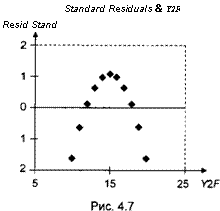
Неправильная спецификация модели в отношении множества объясняющих переменных (regression error specification) приводит к нарушению
условия Е(Єі) = 0, так что E(Yt) * вххІХ + ... + 6рхір. Такая ситуация возникает, например, при оценивании второго множества данных из 4 рассмотренных выше (рис. 4.7).
 | 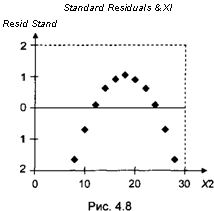 |
полезен для выявления нелинейной зависимости у от у-й объясняющей переменной. Например, график для второго из 4 искусственных множеств приведен на рис. 4.8.
 | |||
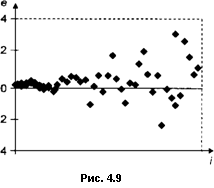 | |||
 изменение дисперсии ошибок с течением времени (рис. 4.9);
изменение дисперсии ошибок с течением времени (рис. 4.9);
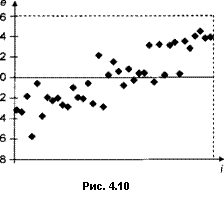
невключение в модель (пропуск) переменных, зависящих от времени и существенно влияющих на объясняемую переменную (рис. 4.10);
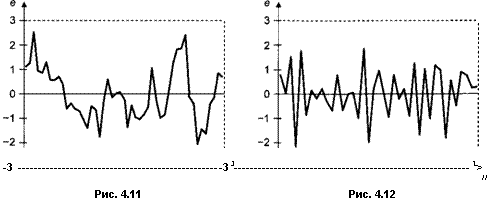
невыполнение условия независимости в совокупности случайных ошибок єі9 і = 1, w, в форме их автокоррелированности. Более подробно о такой форме статистической зависимости между случайными ошибками поговорим позднее, здесь продемонстрируем, как выглядят графики остатков в случае положительной автокоррелированности (рис. 4.11) и в случае отрицательной автокоррелированности (рис. 4.12).
В первом случае проявляется тенденция сохранения знака остатка при переходе к следующему наблюдению (за положительным остатком, скорее, следует также положительный остаток, а за отрицательным — отрицательный). Во втором случае проявляется тенденция смены знака остатка при переходе к следующему наблюдению (за положительным остатком, скорее, следует отрицательный остаток, а за отрицательным — положительный).
Отдельную группу составляют графические методы проверки предположения о нормальности распределения случайных составляющих єі9 і = 1,п.
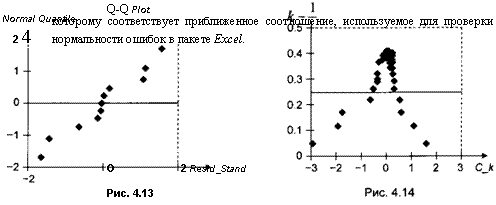
Диаграмма «квантиль-квантиль» (Q-Q plot). Для построения этой диаграммы значения стандартизованных остатков сі9 і = 1, п, упорядочивают в порядке возрастания. Упорядоченные значения образуют ряд
С(1) < С(2) < *
<Ct
Если теперь для каждого k = 1, п нанести в прямоугольной системе координат на плоскости точку с абсциссой с{к) и ординатой
2
п
где0* Ф(2)
*-1
2
квантиль уровня — стандартного нормального распределения;
п
функция стандартного нормального распределения,
то полученные п точек (с(£)? Qk к = 1, п, в случае нормального распределения ошибок должны располагаться вдоль прямой, имеющей угловой коэффициент, близкий к 1. Подобное расположение имеют точки на диаграмме, построенной указанным способом по первому из 4 множеств искусственных данных (рис. 4.13).
Замечание 4.4.1. Если в последней процедуре не проводить стандартизацию остатков, а использовать непосредственно остатки ei9
і = 1, я, то полученные точки Qk к = 1, я, также будут располагаться (при нормальном распределении ошибок) вдоль некоторой прямой, но уже имеющей угловой коэффициент, не обязательно близкий к 1.
Указанное свойство диаграммы «квантиль-квантиль» основано на том, что при больших значениях п имеет место приближенное равенство
-і
2
п
 ф(<™)*—-•
ф(<™)*—-•
п
Диаграмма плотности (DP-plot, DPP) отличается от диаграммы «квантиль-квантиль» тем, что по оси ординат вместо значений квантилей Qk откладываются значения функции плотности стандартного нормального распределения ср(х) при значениях аргумента, равных Qk9 т.е. значения <p(Qk). По такой диаграмме при достаточном количестве наблюдений можно не только проверить предположение о нормальном распределении ошибок, но и выявить характер альтернативного распределения в случае отклонения распределения ошибок от нормального. В качестве примера приведем диаграмму плотности, построенную по остаткам, полученным в результате подбора модели линейной зависимости совокупных расходов (CONS) на личное потребление от совокупного располагаемого личного дохода (DPI) (данные по США в млрд долл. 1982 г., за период с 1959 по 1985 г.) (рис. 4.14).
На этой диаграмме обнаруживается определенная асимметрия, что представляется не вполне согласующимся с предположением о нормальности ошибок. Однако не следует на этом основании сразу делать вывод о нарушении такого предположения. Дело в том, что при небольшом количестве наблюдений структура подобной диаграммы весьма неустойчива. Поэтому даже при заведомо нормальном распределении ошибок редко можно увидеть вполне симметричную картину расположения точек на диаграмме при малом количестве наблюдений.
Ядерные оценки плотности (kernel density estimates) — метод оценивания функции плотности, позволяющий получать график в виде непрерывной кривой. Существует много вариантов таких оценок, в детали которых вдаваться не будем, отметим только, что в пакете EViews предлагается на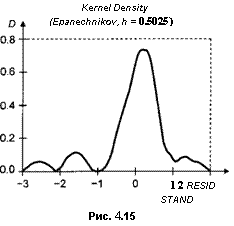
выбор 8 вариантов, в рамках которых можно еще и варьировать параметры. Вариант, применяемый по умолчанию, дает для рассмотренных данных следующую оценку плотности распределения ошибок (рис. 4.15).
Как видим, и при таком подходе получается график, не очень похожий на график функции плотности стандартного нормального распределения, но это опять может быть вызвано малым количеством наблюдений (п = 27).
 |
В пакете Е Views наряду с наблюдением за рекурсивными коэффициентами можно наблюдать и за рекурсивными остатками (recursive residuals), которые представляют собой последовательность нормированных ошибок прогнозов на один шаг для значений объясняемой переменной линейной эконометрической модели в процессе последовательного добавления данных. Если в модели р объясняющих переменных, то при добавлении данных впервые модель можно оценить, взяв первые р наблюдений. Нормированная ошибка прогноза по оцененной модели на (р + 1)-е наблюдение представляет рекурсивный остаток w + J. Взяв теперь первые (р + 1) наблюдений, оценим модель по этим наблюдениям и найдем нормированную ошибку прогноза по оцененной модели на (р + 2)-е наблюдение. Это будет рекурсивный остаток wp + 2-Продолжив этот процесс, получим последовательность нормированных рекурсивных остатков.
Заметим, что дисперсия ошибки прогноза на (t + 1)-е наблюдение, сделанного по модели, оцененной по первым t наблюдениям, равна:
*1 + х,+1{Х?ХУ(х,+х)Т),
где Xt —матрица значений объясняющих переменных в первых t наблюдениях;
xt+l —вектор-строка значений объясняющих переменных в (t + 1)-м наблюдении.
Нормировка ошибки прогноза на (t + 1)-е наблюдение производится делением этой ошибки на величину (1 + xt+l(X?Xt)~l (xt+l)T). При выполнении стандартных предположений, включая нормальность ошибок, рекурсивные остатки wp+l9 wn являются одинаково распределенными, взаимно независимыми нормальными случайными величинами, имеющими нулевое среднее и дисперсию а1. Это дает возможность построить доверительные интервалы для рекурсивных остатков, и тогда выход рекурсивных остатков за эти доверительные интервалы говорит не в пользу стабильности модели.
Проблема, однако, в том, что для построения доверительных интервалов необходимо знать дисперсию а2 случайных ошибок в модели. Так как она неизвестна, ее приходится оценивать, и оценки оказываются разными для моделей, использующих разное количество наблюдений. Поэтому реально построенные доверительные интервалы для рекурсивных остатков имеют различную ширину.
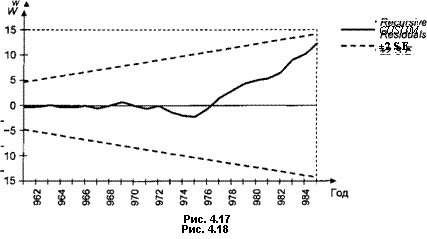
Поведение рекурсивных остатков для тех же данных по США показано на рис. 4.17.
В пакете ЕViews можно также отслеживать поведение кумулятивных сумм нормированных рекурсивных остатков (CUSUM— cumulative sums),
k IRSS
которые определяются по формуле Wk = V — , где S = I , a RSS —
t=p+i S п-р
остаточная сумма квадратов при оценивании модели по всем п наблюдениям.
При выполнении стандартных предположений о модели (включая нормальность ошибок) график Wk как функции от к должен оставаться в пределах коридора, ограниченного прямыми, соединяющими точки (р9±0.94&т]п-р) с точками (и, ±3-0.948^-/?), с вероятностью 0.95.
 |
КОНТРОЛЬНЫЕ ВОПРОСЫ
Как влияют нарушения стандартных предположений о модели на результаты, полученные методами, предполагающими выполнение всех этих предположений?
Каковы основные типы нарушений стандартных предположений?
В чем состоит методология Лондонской школы экономики?
На чем основывается использование графических процедур обнаружения нарушений стандартных предположений о модели?
Какие графические процедуры используются для обнаружения:
выделяющихся наблюдений;
неоднородности дисперсий ошибок (гетероскедастичности);
неправильной спецификации модели в отношении множества объясняющих переменных;
изменения дисперсии ошибок с течением времени;
невыполнения условия независимости в совокупности случайных ошибок;
нарушения предположения о нормальности распределения случайных ошибок;
нестабильности коэффициентов модели на периоде наблюдений?

Обсуждение Эконометрика Книга первая Часть 1
Комментарии, рецензии и отзывы