Тема 5.3 учет автокоррелированности ошибок
Тема 5.3 учет автокоррелированности ошибок
Такой вид нарушений стандартных предположений, как автокоррелирован-ность (сериальная корреляция) ошибок (autocorrelation, serial correlation), характерен для статистических данных, развернутых во времени (временные ряды). Автокоррелированность ошибок обычно возникает вследствие неправильной спецификации модели, например, при невключении в модель существенной объясняющей переменной с выраженной автокорреляцией. Последствия автокоррелированности ошибок:
RSS
стандартная оценка S2 = дисперсии случайных ошибок смещена
п-р
вниз в случае положительной автокоррелированности ошибок и смещена вверх в случае отрицательной автокоррелированности ошибок;
стандартные оценки дисперсий случайных величин 6Х, вр (оценок коэффициентов линейной модели) оказываются заниженными в случае положительной и завышенными в случае отрицательной автокоррелированности ошибок;
построенные доверительные интервалы для ви 9р не соответствуют заявленным уровням значимости: в случае положительной автокоррелированности ошибок построенные интервалы неоправданно узки, а в случае отрицательной автокоррелированности ошибок — неоправданно широки;
вычисленные значения tи F-отношений нельзя рассматривать как наблюдаемые значения случайных величин, имеющих tи F-распреде-ления, соответствующие стандартным предположениям. Поэтому сравнение вычисленных значений tи F-отношений с квантилями указанных U и F-распределений может приводить к ошибочным статистическим выводам по поводу гипотез о значениях коэффициентов линейной модели. Вычисленные значения и F-отношений завышены в случае положительной и занижены в случае отрицательной автокоррелированности ошибок.
Коррекция статистических выводов при автокоррелированности ошибок
Пусть имеем дело с наблюдениями, производимыми последовательно через равные промежутки времени (ежедневные, еженедельные, ежеквартальные, ежегодные статистические данные), и выявляем по графику зависимости станку
дартизованных остатков ci = от / тенденцию сохранения знака соседних
наблюдений. В таком случае можно подозревать нарушение условия независимости случайных ошибок єІ9єп в принятой нами модели наблюдений
Уі=0іХі+ — + 0рХір+Єі> / = 1, • • •, л,
в форме положительной автокоррелированности ряда ошибок.
Предположим, что ошибки образуют процесс авторегрессии первого порядка (first order autoregressive process):
єі = pst_x + Si9 і = 2,..., и, где 0 < р< 1, a Si9 і = 2, п9 — независимые в совокупности случайные величины, имеющие одинаковое нормальное распределение N(09 сг2), причем St не зависит статистически от st_s для s > 0. Тогда для получения правильных статистических выводов относительно коэффициентов модели необходима соответствующая коррекция.
Итерационная процедура Кохрейна — Оркатта (Cochrane-Orcuti). Умножим обе части уравнения для (/ 1)-го наблюдения на р9 так что
и вычтем обе части полученного выражения из соответствующих частей выражения для /-го наблюдения:
У і ~ РУі-х = 0Х (xiX pXi_u j) + ... + Op (Xjp — pxt_Xp) + (є, ре{_х)
(авторегрессионное преобразование — autoregressive transformation). Таким образом приходим к преобразованной модели наблюдений
у = вххх +... + врхр + е9 і = 2,п9
где
у'і=Уі-РУі-і>
Xi = Xi ~ PXi-, ->-">Xip~Xip~ PXi-Up'
Поскольку в принятой модели ошибок
et -pet_x = Si9 i = 29...9n9
это означает, что ошибки є'І9є'п в преобразованной модели — независимые в совокупности случайные величины, имеющие одинаковое нормальное распределение N(09 а2).
Иными словами, случайные ошибки в преобразованной модели удовлетворяют стандартным предположениям. Следовательно, в рамках преобразованной модели никакой дополнительной коррекции обычных статистических выводов о коэффициентах модели не требуется. Проблема только в том, что используемое в процессе преобразования модели значение коэффициента р нам неизвестно. Поэтому реально провести указанное преобразование невозможно. Вместо этого можно пытаться заменить указанное преобразование какой-либо его аппроксимацией с заменой неизвестного значения р на его оценку по данным наблюдений. Конечно, при использовании такой аппроксимации уже нельзя гарантировать, что є'29 є'п в преобразованной модели будут независимыми в совокупности случайными величинами, однако есть надежда на то, что эти ошибки все же будут обнаруживать меньшую авто-коррелированность по сравнению с ошибками в исходной модели.
Процедура Кохрейна — Оркатта использует для получения аппроксимации теоретического преобразования оценку для р в виде
п і = 2
Г=— »
і = 2
где е19еп — остатки, получаемые при оценивании исходной модели наблюдений. Аппроксимирующее преобразование определяется соотношениями
Уі=Уі-гУі-ї9 * *
ХП = ХП ~~ ГХІ-, 1 ' ' ' ' ' ХІр~ХІр~ ГХІ-, р '
которые приводят к преобразованной модели
У*=0хп + ' = 2,..., л.
Если в последней модели автокоррелированность используемыми тестами не выявляется, то полученные в рамках этой модели оценки параметров
вХ9 вр можно принять в качестве уточненных оценок параметров вХ9 вр. Если же в преобразованной модели еще остается выраженная автокоррелированность, то процесс преобразования применяют уже к преобразованной модели и еще раз уточняют значения параметров и т.д., пока последовательно уточняемые значения параметров не перестанут изменяться в пределах заданной точности.
Заметим, наконец, что обычно предполагаем хп = 1. Соответственно для первой объясняющей переменной получим
* — _ — 1 —
Xi Xil rXi-h ~ 1 Г'
так что фактически имеем преобразованную модель
у* =а* +в2х*2 +... + 6рх]р +£*, / = 2,..., л,
с а* = вх(1 г). Получив в этой модели оценку а* для а*9 можно оценить
параметр вх исходной модели, просто полагая вх = .
ПРИМЕР 5.3.1
 Проанализируем статистические данные о совокупных потребительских расходах (CONS) и денежной массе (MONEY) в США за 1952—1956 гг. (табл. 5.14).
Проанализируем статистические данные о совокупных потребительских расходах (CONS) и денежной массе (MONEY) в США за 1952—1956 гг. (табл. 5.14).
Результаты оценивания линейной модели наблюдений
У;=а + 0Х1+еп / = 1, 20,
где у і — значения объясняемой переменной CONS;
X; — значения объясняющей переменной MONEY, приведены в табл. 5.15.
 Хотя коэффициент детерминации весьма близок к 1, значение статистики Дарбина — Уотсона достаточно мало, и это дает основание подозревать наличие положительной автокоррелированности ошибок в принятой модели наблюдений. График на рис. 5.13 дает представление о рассеянии значений переменных, а на рис. 5.14 — о поведении остатков. Здесь наблюдаются серии остатков, имеющих одинаковые знаки, что как раз характерно для моделей, в которых имеется положительная автокоррелирован-ность ошибок.
Хотя коэффициент детерминации весьма близок к 1, значение статистики Дарбина — Уотсона достаточно мало, и это дает основание подозревать наличие положительной автокоррелированности ошибок в принятой модели наблюдений. График на рис. 5.13 дает представление о рассеянии значений переменных, а на рис. 5.14 — о поведении остатков. Здесь наблюдаются серии остатков, имеющих одинаковые знаки, что как раз характерно для моделей, в которых имеется положительная автокоррелирован-ность ошибок.
 |
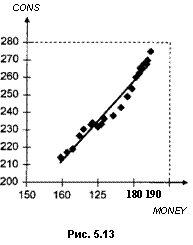 Рис. 5.14
Рис. 5.14 Для подтверждения положительной автокоррелированности ошибок используем критерий Дарбина — Уотсона. Из табл. А.5, приведенной в учебнике (Доугерти, 2004, с. 403), находим нижнюю границу для критического значения d005 при п = 20: dL 005 = 1.20. Полученное при оценивании модели значение DW= 0.328 существенно меньше этой нижней границы, так что гипотеза Я0 : р = 0 отвергается в пользу альтернативной гипотезы НА : р > 0. Для коррекции статистических выводов используем процедуру Кохрейна — Оркатта.
Прежде всего, найдем оценку для неизвестного значения коэффициента р:
-і
г = — = 0.874.
п
= 2 п
-і
/=2
2Х,
 Основываясь на этой оценке, перейдем к преобразованной модели, результаты оценивания которой приведены в табл. 5.16.
Основываясь на этой оценке, перейдем к преобразованной модели, результаты оценивания которой приведены в табл. 5.16.
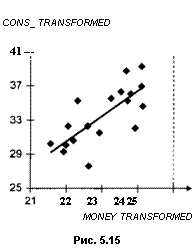
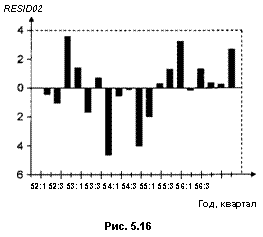
Хотя в преобразованной модели коэффициент детерминации существенно ниже, чем в непреобразованной модели, значение статистики Дарбина — Уотсона теперь превышает верхнюю границу dv 0 05 = 1.40 для критического значения d0 059 соответствующего п = 19. (В преобразованной модели наблюдений на единицу меньше, чем в исходной, так как при преобразовании используются запаздывающие значения переменных.) Поэтому гипотеза о независимости в совокупности ошибок в преобразованной модели не отвергается (в пользу гипотезы об их положительной автокоррелированности). График на рис. 5.15 дает представление о рассеянии значений преобразованных переменных, а на рис. 5.16 — о поведении остатков в преобразованной модели. Обратим внимание на существенно более нерегулярное поведение остатков по сравнению с исходной моделью.
Обратившись к результатам оценивания коэффициентов в преобразованной модели, отметим значительное (более чем в 5 раз!) возрастание оценки стандартной ошибки Sp, что подтверждает сделанное ранее замечание о занижении стандартных ошибок при неучете имеющейся в действительности положительной автокорреляции случайных ошибок в модели наблюдений. Столь существенное возрастание значения Sp приводит к возрастанию более чем в 5 раз и ширины доверительного интервала для мультипликатора Д Если при оценивании исходной линейной модели 95\%-й доверительный интервал для этого параметра имел вид 2.058 < Д < 2.542, то при оценивании преобразованной модели получим интервал 1.516 < Д< 4.074.И
 | |||
 | |||
Более того, используя преобразованную модель, можно получить улучшенную модель для прогнозирования объемов расходов на потребление при планируемых объемах денежной массы. Поясним это на примере простой линейной модели
У1=а + Ръ+€п / = 1,...,и.
Предполагая, что єі pst_x = Si9 і 2, п9 и используя оценку г для коэффициента р9 перейдем к преобразованной модели
у* =а* + fix* + є*9 і = 2,..., л,
У* = У і ~ гУі> х* = (х, rxt_x), і = 2,..., п, а = а( г).
В рамках этой модели получим оценки а* и fi параметров а* и fi. Тогда оцененная модель линейной связи между преобразованными переменными имеет вид:
yt =а + fixi9 i = 29...9n. В исходных переменных последние соотношения принимают вид: У і ~ гУі=a(l-r) + fi (х, rxt_x), і = 2,..., п,
а
где а = , откуда получаем:
l-r
yt = а + Pxt+r{yt_x-dJ3xt_x)9 / = 2,...,я.
Если прогнозировать будущее значение уп+Х9 соответствующее плановому значению хп+1 объясняющей переменной, то естественно воспользоваться полученным соотношением и предложить в качестве прогнозного для уп+х значение
Уп+ + fan+ + ЛУП -а-0хп).
При таком способе вычисления прогнозного значения для^„+1 учитывается тенденция сохранения знака остатков: если в последнем наблюдении значение уп больше а + J3xn9 предсказываемого линейной моделью связи у = а + то и последующее значение уп+1 прогнозируется с превышением значения а + J3xn+l9 предсказываемого этой линейной моделью связи при г > 0. Если же значение уп меньше, чем а + flx„9 то будущее значение уп+1
прогнозируется значением, меньшим, чем а + Рхп+Х.
Рассмотрим еще одно важное следствие автокоррелированности ошибок в линейной модели
yt=a + pxt+si9 i = l,...,/i, et-pet_x = Si9 i = 29...9n.
Преобразование
у'і=Уі-РУі-і> x = xt-Pxiприводит к модели наблюдений
у = а' + Рх + 819 / = 2,...,л,
на основании которой получаем
уt = a(l-р) + pyt_x + 0(xt -pxt_x) + Si9 / = 2,..., и.
Вспомним теперь о нашем предположении, что 0 < р < 1, и преобразуем последнее соотношение следующим образом:
уt = а (1 р) + Уі_х (1 р)Уі_х + р (*,. xt_x + (1 р) xt_x) + St = = yt_x + (1 p)(a + P xt_x yt_x) + P (x, xt_x ) + Si9
или
АУі = PAX; +(p1)(Уі_х a -pxt_x ) + Si9 здесь Ay і =yt-yt_X9 Axt = xt xt_x и -1 < (p1) < 0.
Второе слагаемое в правой части, по существу, поддерживает «долговременную» линейную связь (тенденцию)
у = а + Рх.
Если в момент (/ 1) отклонениеyt_х от а + J3xi_x положительно (yt_x > а + + ), то второе слагаемое будет отрицательным и действовать в сторону уменьшения приращения Ayt -yt -у^х. Если же отклонениеyt_x от а + (3xt_x отрицательно (yt_x < а + Pxt_x)9 то второе слагаемое будет положительным и действовать в сторону увеличения приращения Ayt = yt -у^х.
Указанная модель коррекции приращений переменной у использует истинные значения параметров а, /3, р. Поскольку эти значения неизвестны, можно построить только аппроксимацию такой модели, использующую оценки параметров. При этом естественно воспользоваться оценкой г и уточненными оценками а, /?, полученными на базе преобразованной модели.
В рассмотренном примере аппроксимирующая модель коррекции приращений принимает вид:
Ау( = 2.975AJC,. -0.126(>>м 244.262-2.795хм).
Как и в случае неоднородности дисперсий случайных ошибок, при наличии автокоррелированности ошибок в модели наблюдений возникает смещение оценок дисперсий случайных величин вХ9 вр9 хотя наличие и такого
нарушения стандартных предположений оставляет сами оценки в19 вр несмещенными. В связи с этим один из методов коррекции статистических выводов при автокоррелированности ошибок состоит в использовании обычных оценок наименьших квадратов в19вр коэффициентов #lv.., вр вместе со скорректированными на автокоррелированность оценками стандартных
ОШИбоК Sq..
Один из вариантов получения скорректированных на автокоррелированность значений s§ был предложен Ньюи и Вестом (Newey, West) и реализован
в ряде пакетов статистического анализа данных, в том числе в пакете EViews. При этом удовлетворительные свойства оценки Ньюи — Веста (Newey-West estimate) гарантируются только при большом количестве наблюдений. Не будем приводить здесь детали получения оценки Ньюи — Веста (вид этой оценки указан, например, в книге (Магнус, Катышев, Пересецкш, 2005), а просто воспользуемся пакетом EViews для анализа данных из только что рассмотренного примера.
 Напомним результаты оценивания исходной линейной модели без учета автокоррелированности ошибок (табл. 5.17).
Напомним результаты оценивания исходной линейной модели без учета автокоррелированности ошибок (табл. 5.17).
 Как и ожидалось, во втором случае обнаруживаем возрастание оценок стандартных ошибок для оценок обоих коэффициентов.
Как и ожидалось, во втором случае обнаруживаем возрастание оценок стандартных ошибок для оценок обоих коэффициентов.
КОНТРОЛЬНЫЕ ВОПРОСЫ
Каковы причины автокоррелированности ошибок в линейной эконометрической модели?
Каковы последствия автокоррелированности ошибок в линейной эконометрической модели?
Как можно скорректировать модель с автокоррелированными ошибками, чтобы получить корректные статистические выводы?
Как можно получить корректные статистические выводы без преобразования модели с автокоррелированными ошибками?
Как можно использовать автокоррелированность ошибок в линейной эконометрической модели для улучшения качества прогнозов, строящихся на основе оцененной модели?

Обсуждение Эконометрика Книга первая Часть 1
Комментарии, рецензии и отзывы