Часть 1 основные понятия, элементарные методы раздел 1 эконометрика и ее связь с экономической теорией. метод наименьших квадратов тема 1.1 модели связи и модели наблюдений; эконометрическая модель, подобранная модель
Часть 1 основные понятия, элементарные методы раздел 1 эконометрика и ее связь с экономической теорией. метод наименьших квадратов тема 1.1 модели связи и модели наблюдений; эконометрическая модель, подобранная модель
Эконометрика (Econometrics) — совокупность методов анализа связей между различными экономическими показателями (факторами) на основе реальных статистических данных с использованием аппарата теории вероятностей и математической статистики. При помощи этих методов можно уточнять или отвергать различные гипотезы о существовании определенных связей между экономическими показателями, предлагаемые экономической теорией, выявлять новые, ранее неизвестные связи, производить прогнозирование будущих значений экономических показателей.
Наряду с микроэкономикой и макроэкономикой эконометрика является одним из базовых предметов современного экономического образования. Для анализа статистических данных эконометрика использует методы теории вероятностей и математической статистики. При этом одни модели и методы чаще применяются к исследованиям на микроуровне, тогда как другие — к исследованиям на макроуровне. В связи с этим иногда говорят о подразделении эконометрики на микроэконометрику и макроэконометрику (в этом отношении можно сослаться, например, на монографии (Favero, 2001) и (Cameron, Trivedi, 2005)). В течение многих лет основной задачей эконометрики являлось по возможности наиболее эффективное оценивание параметров математических моделей, предлагаемых экономической теорией. При этом было принято исходить из предположения о правильности спецификации модели, предлагаемой экономистами. В соответствии с таким подходом эконометрист только оценивал модель на основании статистических данных, не пытаясь ее изменить, и по результатам оценивания делал выводы о подтверждении или неподтверждении заявленных теоретических связей между экономическими факторами, а также априорных значений некоторых параметров теоретических моделей. В этом отношении можно сослаться на определение эконометрики, приведенное в работе (Samuelson, Koopmans, Stone, 1954): «The application of mathematical statistics to economic data to lend empirical support to models constructed by mathematical economics and to obtain numerical estimates»l.
С течением времени в прикладных эконометрических исследованиях значительное место стал занимать так называемый разведочный анализ (data mining), при котором исследователь в первую очередь обращается именно к имеющимся статистическим данным и пытается подобрать к ним несколько альтернативных моделей, прежде чем остановиться на какой-то одной из них и принять результаты, полученные для этой предпочтительной модели. Анализируя характер имеющихся статистических данных, исследователь делает определенные заключения о возможной форме теоретической модели, что помогает при построении окончательной модели. Более того, если в процессе такого анализа предложенная теоретическая модель отвергается, сами данные могут указать на то, в каком направлении следует изменить спецификацию исходной теоретической модели.
В настоящее время построение окончательной модели производится с учетом как представлений экономической теории, так и информации, содержащейся в эмпирических данных. Последняя может, например, указать на необходимость включения в модель, предлагаемую экономической теорией, дополнительных переменных или на исключение из модели тех или иных «лишних» переменных, на необходимость изменения функциональной формы связи между рассматриваемыми переменными и т.п. В процессе построения модели естественно учитывать и результаты предшествующих эконометрических исследований. Заметим только, что в основе всякого эконометриче-ского исследования лежит представление о существовании некоторого «истинного» механизма порождения эмпирических данных, о котором мы будем говорить в дальнейшем как о процессе порождения данных (ППД, или DGP — data generating process).
Рассмотрим, например, связь между располагаемым доходом домашнего хозяйства (disposable personal income) DPI и расходами домашнего хозяйства на личное потребление (personal consumption expenditures) CONS. Кейнс в своей знаменитой книге (Keynes, 1936) отметил как фундаментальный закон психологии склонность людей (как правило, и в среднем) увеличивать расходы на личное потребление по мере возрастания своих доходов, но не в той степени, в какой возрастает их доход. Это означает, что если расходы на личное потребление связаны с располагаемым доходом соотношением
CONS = f (DPI), где обе переменные измерены в одних единицах, то:
Применение математической статистики к экономическим данным для эмпирической поддержки построенных экономико-математических моделей и получения числовых оценок (англ.). — Пер. автора.
функция f(DPl) должна быть возрастающей;
скорость изменения этой функции, т.е. предельная склонность к потреблению (предельная норма потребления), должна быть меньше 1.
Вместе с тем Кейнс не указал явную форму такой функциональной связи, справедливо замечая, что она должна соответствовать реальным статистическим данным.
Простейшей моделью функциональной связи между DPI и CONS удовлетворяющей указанным требованиям, является линейная модель связи (linear relation) — модель линейной зависимости CONS от DPI:
CONS = а + ft • DPI,
где ft — постоянная величина, 0 < ft < 1, характеризующая в данном круге домашних хозяйств их склонность к потреблению (propensity to consume), связанную с традициями и привычками; а — автономное потребление (autonomy consumption).
Для подтверждения правильности выбора такой теоретической модели и для проверки гипотез о ее параметрах (например, о том, что для некоторой совокупности домашних хозяйств в определенный период склонность к потреблению не превышала значения 0.9) надо обратиться к статистическим данным.
Пусть имеем данные о размерах располагаемого дохода и о расходах на личное потребление для п домашних хозяйств, так что DPI, и CONS! — соответственно располагаемый доход и расходы на личное потребление z-ro домашнего хозяйства. (Заметим, что получение подобных статистических данных само по себе является далеко не простой задачей, поскольку требует от всех выбранных домохозяйств ежедневного учета их доходов и расходов и сообщения итоговых результатов без искажения).
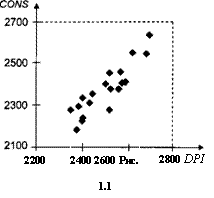
Если на плоскости в прямоугольной системе координат разместить точки {DPIi9 CONS і) с абсциссами DPI( и ординатами CONS і (такое построение называется диаграммой рассеяния — scatter plot, scatter diagram, scatter graph), то, как правило, эти точки не будут лежать на одной прямой вида CONS = а + ft DPI, соответствующей линейной модели связи. Они будут образовывать облако рассеяния (scatter cloud), вытянутое вдоль гипотетической прямой CONS = а + ftDPI.
Подобная форма облака приведена на диаграмме рассеяния (рис. 1.1), соответствующей смоделированным данным о годовых располагаемом доходе и расходах на личное потребление (в 1999 г., в условных единицах) 20 домашних хозяйств Российской Федерации (табл. 1.1).
Значение
ех =CONSi-(a + ftDPIl)
является отклонением реально наблюдаемых расходов на потребление CONSt от значения а + ft • DPI{, предсказываемого гипотетической линейной моделью
связи для /-го домашнего хозяйства, имеющего располагаемый доход DPI{. Это отклонение отражает совокупное влияние на конкретные значения CONSt множества дополнительных факторов, не учитываемых принятой моделью связи, так что реальное соотношение между DPIt и CONSt принимает форму модели наблюдений {observation model):
CONSi={a + p-DPIi) + si, = 1, ...9п.
Соответственно о величине е{ = CONSt {а + j3 • DPIt) говорят как об ошибке наблюдений {observation error, disturbance), точнее, как об ошибке в 1-м наблюдении.
 Особенность эконометрического подхода состоит в том, что отклонения є{ рассматриваются как случайные величины (реализации случайных величин), так что связь между переменными, в данном случае между DPIt и CONSi9 является не детерминированной, а стохастической. При этом несколько расплывчатые рассуждения о теоретической (усредненной) функции связи становятся более формализованными, если предположить, что процесс порождения данных имеет вид:
Особенность эконометрического подхода состоит в том, что отклонения є{ рассматриваются как случайные величины (реализации случайных величин), так что связь между переменными, в данном случае между DPIt и CONSi9 является не детерминированной, а стохастической. При этом несколько расплывчатые рассуждения о теоретической (усредненной) функции связи становятся более формализованными, если предположить, что процесс порождения данных имеет вид:
CONS; = f{DPIt) + £*,, і = 1,..., л,
где ЄІ9
єп— случайные величины, условные математические ожидания которых при фиксированных значениях располагаемого дохода равны 0:
 ад£>р/,) = о, 1 = 1,
ад£>р/,) = о, 1 = 1,
При таком предположении имеем:
E(CONSlDPIl) = f(DPIl), i = l, п,
так что /(DPI}) можно трактовать как ожидаемую величину расходов на личное потребление домохозяйства, имеющего располагаемый доход DPlr Пусть процесс порождения данных имеет вид:
CONS і = (а + /3-ОР1,) + еп / = 1, п,
где DPIX, DPln— заданные (фиксированные) величины;
єх,...,єп—случайные величины, для которых E(ejDPIl) = 0, так
что Е (CONS і DPIf ) = а + /3DPIt;
{З — коэффициент, выражающий изменение ожидаемой величины расходов домохозяйства на личное потребление при увеличении располагаемого дохода домохозяйства на единицу.
В реальных условиях эконометрист имеет в своем распоряжении только статистические данные и не знает вида функции f(DPI). Выбирая ту или иную функцию f(DPI), он формирует соответствующую статистическую модель (statistical model)
CONSi=f(DPIi) + vi, / = 1, п,
где Vj, ..., vn — случайные величины.
Такую модель часто называют также эконометрической моделью (econometric model), имея в виду два обстоятельства:
она не является детерминированной (усредненной) моделью связи и предусматривает возможные отклонения реально наблюдаемых значений CONS} от значений /(DPI;), предсказываемых детерминированной моделью связи;
она выбирается эконометристом, и ее вид может отличаться от истинного процесса порождения данных, который эконометристу неизвестен.
Определение эконометрической модели в явном виде (т.е. задание ее в виде уравнения, с указанием задействованных переменных и функциональной формы связи между переменными, задание априорных ограничений на параметры и вероятностного описания последовательности v1? vn) называется спецификацией эконометрической модели (specification of an econometric model).
В рассмотренных условиях
vt = CONS} f(DPI} ) = (a + ftDPI}) + f(DPI,),
так что E(V}DPI}) = (a +j3DPI})-f(DPI}). При этом значение E(V}DPI}) может быть не равным нулю, и тогда E(CONS}DPI})^ f{DPIt), т.е./(DPI) уже нельзя трактовать как ожидаемую величину расходов на личное потребление домохозяйства, имеющего располагаемый доход DPIt. При подобном неправильном выборе формы функции связи говорят, что статистическая модель неправильно специфицирована (misspecified model).
Представим теперь, что выбранная статистическая модель все же специфицирована правильно и, как и процесс порождения данных, имеет линейную форму:
CONSi={a + p-DPIi)+si, i = l, и.
Однако при этом эконометрист все равно не знает значений параметров а и р процесса порождения данных. Поэтому он должен оценить эти параметры, используя имеющиеся статистические данные, т.е. наблюдаемые пары значений (DPIt, CONSt), і 1,п. При этом интерес могут представлять не только точечные оценки этих параметров, но и доверительные интервалы для них.
Если модель специфицирована правильно и оценки а для а и Ъ для /? каким-то образом получены, то подобранная модель (fitted model)
CONS = a + bDPI
может использоваться для прогнозирования объема расходов на личное потребление для домохозяйства, имеющего располагаемый доход DPI. Разумеется, такой прогноз может иметь смысл:
если полученные оценки достаточно близки к истинным значениям параметров а и /?;
для домохозяйств, имеющих ту же (или хотя бы близкую к ней) склонность к потреблению, что и у домохозяйств, по которым производилось оценивание параметров модели.
После оценивания эконометрической модели обычно проверяют адекватность модели имеющимся статистическим данным, а также те или иные гипотезы о значениях параметров модели.
Может оказаться, например, что наблюдаемое облако рассеяния больше соответствует модели, в которой «теоретическая» (усредненная) функция связи CONS =f(DPI) имеет вид CONS = у+ SlnDPI, y>0,S>0. Заметим, что в такой модели предельная склонность к потреблению уже не является постоdCONS 8
яннои величиной, а зависит от уровня располагаемого дохода: = ,
убывая с возрастанием располагаемого дохода. (При этом условие DPI > 5 обеспечивает выполнение предположения о том, что предельная склонность к потреблению положительна и принимает значения меньше единицы.) Подобные ситуации более характерны для описания связи между располагаемым личным доходом и расходами на потребление отдельных продуктов или группы продуктов (например, молочных продуктов).
Подобранная модель, прошедшая проверку на адекватность имеющимся статистическим данным, может использоваться как для прогнозирования, так и для управления (для проведения определенной экономической политики).
Таким образом, эконометрический анализ представляет собой совокупность следующих действий:
получение на основе экономической теории исходных представлений о существовании связей между определенными экономическими факторами (экономическая гипотеза);
выражение этих представлений в математической форме в виде соответствующих уравнений или систем уравнений (математическая модель);
сбор необходимых (и доступных) статистических данных;
согласование выбранной математической модели с имеющимися в распоряжении статистическими данными (модель наблюдений), спецификация статистической (эконометрической) модели;
оценивание статистической (эконометрической) модели;
проверка гипотезы о правильности выбранной спецификации статистической (эконометрической) модели (проверка адекватности подобранной модели имеющимся статистическим данным); сохранение или изменение этой спецификации по результатам проверки гипотезы адекватности;
уточнение математической модели связи путем проверки тех или иных гипотез о значениях параметров выбранной модели (с учетом результатов проверки эконометрической модели на адекватность имеющимся данным); проверка возможности упрощения модели; проверка экономических гипотез (единичная эластичность и т.п.);
использование подобранной модели для прогнозирования или управления.
В процессе эконометрического анализа исследователи часто придерживаются принципа парсимонии (экономичности, простоты parsimony principle): модель должна быть простой, насколько это возможно, пока не доказана ее неадекватность имеющимся статистическим данным. Исследователи используют также принцип охвата (encompassing principle): модель должна быть в определенном смысле «неулучшаемой» и объяснять результаты, получаемые по конкурирующим с ней моделям (в конкурирующих моделях не должно содержаться информации, которая позволила бы улучшить выбранную модель). При проведении исследования рекомендуется также придерживаться метода «от общего к частному» (general-to-specific approach), т.е. в качестве первоначальной брать более полную модель, а затем пробовать редуцировать ее к более простой модели.
Две переменные: меры изменчивости и связи
В табл. 1.2 приведены уровни безработицы среди белого (BEL) и цветного (ZVET) населения США с марта 1968 г. по июль 1969 г. (месячные данные).
Рассмотрим графики изменения уровней безработицы в обеих группах в течение указанного периода (рис. 1.2). Первое впечатление: уровень безработицы среди цветного населения существенно выше и изменяется со временем со значительными колебаниями, уровень безработицы среди белого населения изменяется плавно и в довольно узком диапазоне.
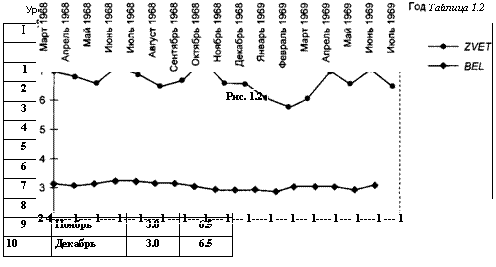 Обозначим через xl9 х17 последовательно наблюдаемые уровни безработицы среди цветного населения, а через yl9 у17 — соответствующие им уровни безработицы среди белого населения США. Таким образом, можно говорить о наблюдаемых значениях двух переменных: х уровня безработицы среди цветного населения, и у — уровня безработицы среди белого населения. Всего имеем п = 17 наблюдаемых пар значений переменных х и у: (xl9yx)9(хп,уп).
Обозначим через xl9 х17 последовательно наблюдаемые уровни безработицы среди цветного населения, а через yl9 у17 — соответствующие им уровни безработицы среди белого населения США. Таким образом, можно говорить о наблюдаемых значениях двух переменных: х уровня безработицы среди цветного населения, и у — уровня безработицы среди белого населения. Всего имеем п = 17 наблюдаемых пар значений переменных х и у: (xl9yx)9(хп,уп).
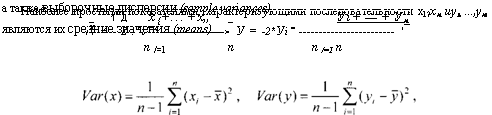 характеризующие степень разброса значений хь хп (у,, ...,>>„) вокруг своего среднего х (или у соответственно), или вариабельность (изменчивость — variability) этих переменных на множестве наблюдений. Отсюда обозначение Var (variance). Впрочем, более естественным было бы измерение степени разброса значений переменных в тех же единицах, в которых измеряется и сама переменная. Эту задачу решает показатель, называемый стандартным отклонением1 (Std.Dev. — standard deviation) переменной х (переменной у), который определяется соотношением
характеризующие степень разброса значений хь хп (у,, ...,>>„) вокруг своего среднего х (или у соответственно), или вариабельность (изменчивость — variability) этих переменных на множестве наблюдений. Отсюда обозначение Var (variance). Впрочем, более естественным было бы измерение степени разброса значений переменных в тех же единицах, в которых измеряется и сама переменная. Эту задачу решает показатель, называемый стандартным отклонением1 (Std.Dev. — standard deviation) переменной х (переменной у), который определяется соотношением
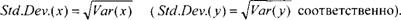
Определяя выборочную дисперсию, сумму квадратов отклонений наблюдаемых значений переменной от их среднего значения делим не на количество наблюдений п, а на п 1. Именно такое определение используется в математической статистике по следующей причине. Если предполагать, что х1? хп — случайная выборка из распределения с математическим ожиданием ju и дисперсией сг2, то, как известно из курса математической статистики,
х = — У]хі является несмещенной оценкой для /и, a Var(x) = У](хі -х)2
является несмещенной оценкой для а2. Задания для практических занятий ориентированы на применение специализированного пакета прикладных программ Econometric Views (Е Views), и в этом пакете принято именно такое определение выборочной дисперсии.
Вычисления по указанным выше формулам приводят в нашем примере к значениям: х = 6.576, StdDev.(x) = 0.416, у = 3.118, Std.Dev.iy) = 0.113. Иными словами, средний уровень безработицы среди цветного населения более чем в 2 раза превышает средний уровень безработицы среди белого населения. Стандартные отклонения соответственно относятся приблизительно как 4:1, что указывает на гораздо более сильную изменчивость (вариабельность) уровня безработицы среди цветного населения. Размах колебаний уровней соответственно равен: 7.3 5.7 = 1.6 и 3.3 2.9 = 0.4.
Здесь мы следуем терминологии словаря статистических терминов (The Oxford dictionary of statistical terms, 2003).
3,2 -♦ ♦ ♦
♦ ♦ ♦ ♦
♦ ♦
♦ ♦
3,0 -Удобным графическим средством
анализа данных является, как говорилось ранее, диаграмма рассеяния, на которой в прямоугольной системе координат располагаются точки хі9 уі9 і = 1,п,
где п — количество наблюдаемых пар
значений переменных х и у (иногда эту
диаграмму называют корреляционным
^ полем — correlation diagram). Диа5,5 6,0 6,5 7,0 7,5 zvet грамма рассеяния для нашего примера
приведена на рис. 1.3.
Рис-13 Вытянутость облака точек на диаграмме рассеяния вдоль наклонной прямой позволяет сделать предположение о том, что существует некоторая объективная1 тенденция линейной связи между значениями переменных х и у, определяемая соотношением
у=а + /3х, /3*0.
В то же время такое соотношение выражает всего лишь тенденцию: реально наблюдаемые значения у. отличаются от значений а + fixt на величину
так что
уі=(а + Рхі) + єі, / = 1,..., л.
Последнее соотношение определяет линейную модель наблюдений (linear observation model), тогда как соотношение
у=а+fix
определяет линейную модель связи (linear relation) между рассматриваемыми переменными (математическая модель — mathematical model, dependence model), в которой у — зависимая (dependent) переменная, ах — независимая (independent) переменная.
Заметим, однако, что видимая степень проявления вытянутости облака точек на диаграмме рассеяния существенно зависит от выбора единиц измерения переменных хну.
Поэтому, во-первых, желательно при построении диаграммы выбирать масштаб и интервалы изменения переменных таким образом, чтобы окно диаграммы имело вид квадрата и чтобы на диаграмме имелись точки, достаточно близко расположенные к каждой из 4 границ этого квадрата (как на рис. 1.3). Это автоматически реализуется при построении диаграмм рассеяния в пакете Econometric Views.
Впрочем, достаточно хорошо выраженная вытянутость облака точек вдоль наклонной прямой может возникать и в случае так называемой ложной (паразитной) линейной связи, не имеющей содержательной экономической интерпретации (см. пример 1.3.4, тема 1.3).
Во-вторых, желательно иметь какие-то числовые характеристики, которые отражали бы действительное наличие вытянутое™ облака точек вдоль некоторой наклонной прямой и не зависели от шкал, в которых представлены значения переменных.
Одна из возможных характеристик такого рода связана с разбиением диаграммы рассеяния горизонтальной и вертикальной прямыми на 4 прямоугольника (рис. 1.4).
♦ ♦
—
BEL 3.4
3,2
3,0
2,8
н-Н ►
7,5 ZVET
—Ь-5,5 6,0
6,5 7,0 Рис. 1.4
Разбивающие диаграмму прямые (секущие) проводятся через точку (х, у) так что если точка (х;, yt) лежит правее вертикальной секущей, то отклонение X; х имеет знак «плюс», а если левее — то знак «минус». Аналогично, если точка (х{,у;) лежит выше горизонтальной секущей, то отклонение у, у имеет знак «плюс», а если она расположена ниже этой секущей — знак «минус».
В нашем примере т4, т+_ = 4, w_+ = 3 (точки, соответствующие наблюдениям с номерами 6 и 17, имеют совпадающие координаты), т__ = 6 (точки, соответствующие наблюдениям с номерами 9 и 10, имеют совпадающие координаты), так что количество точек с совпадающими знаками отклонений Xj х wyl■ у равно т++ + т__ = 10, а количество точек, у которых знаки отклонений различны, равно т+_ + т_+ = 7.
Количество точек с совпадающими знаками отклонений от средних значений (для таких точек произведение (х, х)(у! -у) положительно) составляет 10/17 = 0.59, т.е. около 59\% общего числа точек, и это служит некоторым указанием на наличие вытянутости облака точек в направлении прямой, имеющей положительный угловой коэффициент. Если бы большинство составляли точки с противоположными знаками отклонений от средних значений (для таких точек произведение (х, х)(v, у) отрицательно), то это служило бы некоторым указанием на наличие вытянутости облака точек в направлении прямой, имеющей отрицательный угловой коэффициент. Последняя ситуация часто наблюдается при рассмотрении зависимости спроса на товар от его цены.
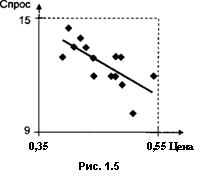
В качестве примера приведем диаграмму рассеяния (рис. 1.5) для статистических данных о еженедельных закупках куриных яиц 7 домохозяйст-вами у одного и того же розничного продавца в течение 15 недель при общем снижении цен на этот продукт в течение этого времени (статистические данные приведены в табл. 1.4; спрос измерялся в дюжинах, цена — в долларах).
 Более распространенным является определение степени выраженности линейной связи между произвольными переменными х и у, принимающими значения xt иуі9 і = 1, п, посредством выборочного коэффициента корреляции (sample correlation coefficient)
Более распространенным является определение степени выраженности линейной связи между произвольными переменными х и у, принимающими значения xt иуі9 і = 1, п, посредством выборочного коэффициента корреляции (sample correlation coefficient)
JVar(x) ^Var(y) '
Cov(x,y)
r*y =
учитывающего не только знаки произведений (х, x)(yt у), но и абсолютную величину этих произведений. Величина Cov(x, у) определяется соотношением
1
/=1
Cov(x,y) = ]Г (х. x)(yi у)
Пи
и называется выборочной ковариацией (sample covariance) переменных х и у. Так что формально
Cov(x, х) = Var(x), Cov(y, у) = Var(y). Заметим также, что Cov(x,у) = Cov(y, х)игху = гух.
Свойства выборочной ковариации, выборочной дисперсии и выборочного коэффициента корреляции
Пусть а — некоторая постоянная, х, у, z — переменные, принимающие в z'-м наблюдении значения xi9 yi9 zi9 і = 1, п (п — количество наблюдений). Тогда а можно рассматривать как переменную, значение которой в z-м наблюдении равно at = а,и
Cov(x,а) = £(х,. x)(at -а) = £(х, х)(а а),
так что Cov(x,a) = 0. Далее очевидно, что
Cov(x, а) = Cov(a, х) и Cov(x, х) = Var(x).
Кроме того,
1 п 1 п
Cov(ax9y) = £(ах, ax)(yt -у) = а £(х,. х)(у. у),
так что
Cov(ax, у) = а Cov(x, у).
Наконец,
1 п
Cov(x,y + z) = X(*,■ ~ хХ(Уі + *,-)(j> + z)) =
n/=1
=-Ч ї>,^x^i л+ X (*/ * )(*/ -?)>
л-1 /=i n /=1
так что
Cov(x, y + z) = Cov(x, jy) + Co v(x, z).
Исходя из этих свойств находим, в частности, что
Var(a) = О, Var(ax) = a2Var(x), Std.Dev.(ax) =| а | Std.Dev.(x)
(при изменении единицы измерения переменной в а > 0 раз во столько же раз изменяется и величина стандартного отклонения этой переменной),
Var{x + а) = Var(x)
(сдвиг начала отсчета не влияет на изменчивость переменной). Наконец,
Var(x + у) = Cov(x + у, х + у) = Cov(x, х) + Cov(x, у) + Cov(y, х) + Cov(y, у),
т.е.
Var(x + у) = Var(x) + Var(y) + 2Cov(x,>>)
(дисперсия суммы двух переменных отличается от суммы дисперсий этих переменных на величину, равную удвоенному значению ковариации между этими переменными).
Что касается выборочного коэффициента корреляции г^, то если изменяются начало отсчета и единица измерения, скажем, переменной х, так что вместо значений хх, хп получаем значения
Xi=a + bxi9 i-,...,n, (b>0)
переменной х = а + bx, тогда
_ Cov(x,y) _ Cov(a + bx,y) _ bCov(x,y) _^ xy ^Var{x) y]Var(y) ^Var(a + bx) ^Var(y) jb2Var(x) ^Var(y)
Иными словами, выборочный коэффициент корреляции инвариантен относительно выбора единиц измерения и начала отсчета переменных хиу.
Значения выборочного коэффициента корреляции не могут быть больше 1 по абсолютной величине, что непосредственно вытекает из применения известного неравенства Коши — Буняковского в виде:
■у)2.
i=l
/=1
Если линейная тенденция выражена на диаграмме рассеяния довольно ясно, то значения г будут по абсолютной величине близки к 1 (значения г,
близки к +1, если облако существенно вытянуто вдоль прямой, имеющей положительный угловой коэффициент, или к -1, если облако существенно вытянуто вдоль прямой, имеющей отрицательный угловой коэффициент). Значение г равно +1 тогда и только тогда, когда все точки (хх, ух),(х„, уп) лежат на прямой, имеющей положительный угловой коэффициент. Значение равно -1 тогда и только тогда, когда все точки (хх, ух), (хп, уп) лежат на прямой, имеющей отрицательный угловой коэффициент.
В нашем примере Var(x) = 0.1732, Var(y) = 0.0128, Cov(x, у) = 0.0217, откуда находим:
00217 =0.4608,
Гху V0.1732 V0.0128
т.е. получаем положительное значение г , расположенное приблизительно посередине между 0 и 1.
В примере с закупками куриных яиц получаем отрицательное значение выборочного коэффициента корреляции: г^ = -0.717. Соответственно в первом случае говорят о положительной корреляционной связи (positive correlation), а во втором — об отрицательной корреляционной связи (negative correlation) между переменными.
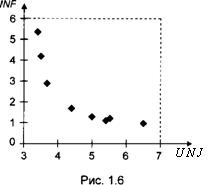 Однако не следует считать, что большое положительное или большое отрицательное значение коэффициента корреляции обязательно свидетельствует именно о линейном характере связи между переменными. Даже при достаточно большом по абсолютной величине значении выборочного коэффициента корреляции построенная по конкретным статистическим данным диаграмма рассеяния может указывать скорее на нелинейную связь между переменными. Обратимся, например, к статистическим данным об уровне безработицы UNJOB и темпах инфляции INF в США за период с 1961 по 1969 г. (эти данные приведены в табл. 1.23 и подробно анализируются при рассмотрении темы 1.4). Значение выборочного коэффициента корреляции между этими переменными равно -0.848. Соответствующая статистическим данным диаграмма рассеяния (рис. 1.6) имеет вид, который вряд ли может указывать на линейный характер связи между этими переменными.
Однако не следует считать, что большое положительное или большое отрицательное значение коэффициента корреляции обязательно свидетельствует именно о линейном характере связи между переменными. Даже при достаточно большом по абсолютной величине значении выборочного коэффициента корреляции построенная по конкретным статистическим данным диаграмма рассеяния может указывать скорее на нелинейную связь между переменными. Обратимся, например, к статистическим данным об уровне безработицы UNJOB и темпах инфляции INF в США за период с 1961 по 1969 г. (эти данные приведены в табл. 1.23 и подробно анализируются при рассмотрении темы 1.4). Значение выборочного коэффициента корреляции между этими переменными равно -0.848. Соответствующая статистическим данным диаграмма рассеяния (рис. 1.6) имеет вид, который вряд ли может указывать на линейный характер связи между этими переменными.
В то же время близость выборочного коэффициента корреляции к нулю вовсе не означает отсутствия какой-либо другой — отличной от линейной — зависимости между данными переменными. Рассмотрите самостоятельно пример, в котором переменные у и х связаны квадратичной зависимостью у = х2, но значения у наблюдаются только при х = -2, -1,0, 1,2. Постройте для этих данных диаграмму рассеяния и определите выборочный коэффициент корреляции.
J Замечание 1.1.1. Мы определили Var и Cov путем деления соответствующих сумм квадратов на п 1. Вместе с тем, например, в учебнике (Доугерти, 2004) соответствующие суммы квадратов делятся не на п 1, а на п. К счастью, Var и Cov у нас играют лишь вспомогательную роль, а величина более существенного для нас коэффициента корреляции не зависит от того, каким из двух способов определяют Var и Cov, лишь бы только при определении обеих этих характеристик использовался один и тот же способ.
/ Замечание 1.1.2. Выборочный коэффициент корреляции, определенный указанным выше способом, более точно называется выборочным коэффициентом парной линейной корреляции Пирсона.
КОНТРОЛЬНЫЕ ВОПРОСЫ
Почему наряду с теоретическими моделями связи между переменными приходится рассматривать модели наблюдений? Чем различаются эти типы моделей? В чем состоит особенность эконометрического подхода к исследованию связей между экономическими переменными?
Что понимается под процессом порождения данных? Что понимается под эконо-метрической (статистической) моделью? Чем отличается эконометрическая модель от процесса порождения данных?
Каковы основные элементы эконометрического анализа?
В чем состоит принцип экономичности, используемый при подборе модели?
В чем состоит принцип охвата, используемый при подборе модели?
В чем заключается метод «от общего к частному», используемый при подборе модели?
Может ли совпадать подобранная модель связи с теоретической?
Какое графическое средство полезно использовать для выяснения характера теоретической (усредненной) связи между двумя экономическими показателями?
Какая числовая характеристика измеряет степень выраженности линейной связи между двумя экономическими показателями в имеющихся наблюдениях?
В каких случаях говорят о положительной (отрицательной) корреляционной связи между экономическими переменными?
Инвариантна ли выборочная ковариация Cov(x, у) относительно выбора единиц измерения и начала отсчета переменных х и yl
Инвариантен ли выборочный коэффициент корреляции относительно выбора единиц измерения и начала отсчета переменных х и yl
Всегда ли высокое значение коэффициента корреляции указывает на линейный характер связи между экономическими переменными?

Обсуждение Эконометрика Книга первая Часть 1
Комментарии, рецензии и отзывы