Приложение п-7
Приложение п-7
ПРОВЕРКА ГИПОТЕЗЫ СЛУЧАЙНОСТИ
В практических исследованиях реальных временных рядов, особенно на первом этапе исследования, обычно нет никаких предварительных данных о вероятностной модели, порождающей наблюдения. Поэтому естественным будет начать анализ с проверки гипотезы о том, что наблюдаемый ряд следует модели случайной выборки — простейшей модели временного ряда. Для краткости эту гипотезу будем называть гипотезой случайности (randomness test), хотя более точно ее следовало бы именовать гипотезой случайной выборки. В рамках этого приложения такую гипотезу сделаем исходной (основной) и будем обозначать ее, следуя традиции, символом Я0 (нулевая гипотеза) (null hypothesis).
На практике используется целый ряд критериев проверки этой гипотезы, отличающихся мощностью при различных альтернативных гипотезах. Рассмотрим некоторые из таких критериев, предполагая непрерывность распределения, из которого извлекается выборка.
Критерий серий (runs test) основан на следующем соображении. Пусть М —
медиана распределения F , так что F(M) Р{Х < М} Р{Х> М) = 1 F(M) = .
Тогда последовательные значения jc, ,хп не должны «слишком долго» задерживаться по одну сторону от уровня М.
Если не известно распределение F, то не известна и его медиана, поэтому приходится использовать ее выборочный аналог — выборочную медиану. Для ее вычисления расположим значения х19 хп в порядке возрастания, т.е. образуем вариационный ряд (ряд порядковых статистик): дс(1),х{п). Выборочная медиана вычисляется по формуле:
х, +1 ч, если п нечетно,
~)
Xf„+Xf
v
med med(xx,...,хя) = 1 ^(
если п четно.
"ЙПН
По исходному временному ряду построим последовательность из плюсов и минусов следующим образом: вместо xt ставится «+», если xt > med, и «-», если xt < med. Под серией (run) понимается последовательность идущих подряд плюсов или идущих подряд минусов.
Пусть в полученной последовательности имеется пх плюсов и п2 минусов, пх + п2 = п, и при этом имеется Z] серий плюсов и z2 серий минусов — всего z = z, + z2 серий. Значения Zj и z2 можно рассматривать как реализации соответствующих случайных величин Zj и Z2. Если гипотеза Н0 верна, то для случайной величины Z = Z, + Z2
п
= 2и,и2(2и,и2-и) пп-)
и если при этом числа и, и п2 велики, то для случайной величины
Z. = Z-E(Z)
можно использовать нормальное приближение N(0, 1), отвергая гипотезу Н0 при «слишком больших» отклонениях наблюдаемого числа серий от ожидаемого.
Критерий поворотных точек (turning points test) особенно удобен при графическом представлении данных, так как значение его тестовой статистики S непосредственно определяется по графику ряда xt и представляет собой суммарное количество «пиков» и «впадин» на этом графике.
«Пик» — это наблюдаемое значение, которое больше двух соседних, «впадина» — наблюдаемое значение, которое меньше двух соседних. Каждое из таких наблюдений называется поворотной точкой (turning point). Начальное jc, и конечное хп значения не могут входить в число поворотных точек, так как у jc, нет соседнего наблюдения слева, а у хп нет соседнего наблюдения справа.
Для /=1,2,п 2 определим «считающую переменную»
^ _ jl если х{ < xt+l и xt+l > xt+2 или если Jt, >дс,+1 и xt+l<xt+2, — в противном случае.
При этом Z, = 1 тогда и только тогда, когда хп+1 — поворотная точка, и суммарное
п-2
число поворотных точек в ряду наблюдений равно S = J]Zr Математическое ожидание случайной величины S равно: E(S) = "fdE(Z,) = 2ZP{Zl=l}.
/=1 t =
Если гипотеза Я0 верна, а распределение F непрерывно, то P{Zt =l} = |, / = 1,2,. ..,«-2,
так что
£(5) = (л-2)|. Дисперсия случайной величины 5 при гипотезе Н0 равна
Z)(5) = l^. 90
При больших п стандартизованная случайная величина
S. = S-E(S) л/ад
имеет при гипотезе Я0 распределение, близкое kN(0, 1).
Гипотеза Я0 отвергается, если наблюдаемое количество поворотных точек значимо отличается от ожидаемого.
J Замечание П-7-1. При практическом применении критерия поворотных точек, когда данные являются округленными, возникают трудности, связанные с тем, что некоторые соседние значения оказываются совпадающими. В таких ситуациях можно рекомендовать следующий подход. По имеющимся данным анализируются последствия возможного (хотя бы и гипотетически) уточнения совпадающих значений. Исследуются все потенциальные возможности увеличения или уменьшения округленных значений при их уточнении («разокруглении»). В результате можно найти верхнюю и нижнюю границы для «истинного» количества поворотных точек, соответствующего исходному «неокругленному» ряду. Для этих граничных значений применяется критерий, указанный выше, и делаются соответствующие выводы относительно гипотезы случайности.
Критерий Кендалла (Kendall test) основан на попарном сравнении всех наблюдений. Для каждой пары индексов(/,у), 1 <i<j<n, положим
ГО если дс. < х,, J II если X. > Xj ,
т.е. Htj = 1 тогда и только тогда, когда значения xt, Xj расположены в порядке, обратном порядку их индексов, т.е. образуют инверсию. Случайная величина
1</</<и
равна суммарному количеству инверсий в ряду дс,,хп. Минимальное значение Q = О
„ „2 п(п-) „ достигается при х, < ... < хп, а максимальное Q = Сп = —^—при х, > ... > хп. Среднее значение Q = Cl = —— соответствует «наибольшему беспорядку» среди зна-
чении ряда, при этом
40
= 1
Критерий Кендалла использует статистику
40
г = 1 —
в литературе ее часто называют «тау Кендалла». При гипотезе Я0 распределение случайной величины г имеет симметричную относительно нуля плотность с нулевым математическим ожиданием и дисперсией
9и(и-1)
а стандартизованная величина
4Ш
имеет распределение, которое уже при п > 11 хорошо аппроксимируется стандартным нормальным распределением. Гипотеза Н0 отвергается при значениях г, значимо отличающихся от нуля.
J Замечание П-7-2. Как и в случае критерия поворотных точек, при применении критерия Кендалла возникают трудности, связанные с наличием у ряда двух или нескольких совпадающих наблюдений. Обойти эти трудности можно двумя способами:
в первом производится прореживание ряда, в процессе которого удаляются «дублирующие» значения. При этом ряд становится короче, но если гипотеза Н0 верна для всего ряда, то она верна и для «укороченного» ряда, а для последнего она проверяется без проблем;
во втором сначала каждой паре совпадающих значений сопоставляется нулевой вклад Hfj = О, при этом получается нижняя граница для значения Q, соответствующего «истинному» (разокругленному) ряду. Затем каждой паре совпадающих значений сопоставляется единичный вклад
Htj=, при этом получается верхняя граница для Q. Полученные два граничных значения используются для вычисления соответствующих им значений г*, и на основании этих значений делается заключение относительно справедливости гипотезы #0.
Критерий Кендалла чувствительнее критерия поворотных точек при наличии в данных линейного тренда. Однако в случае если исследуемая характеристика подвержена сезонным изменениям, критерий Кендалла оказывается бесполезным, поскольку он, как правило, не отвергает гипотезу случайности Н0 даже при наличии выраженного периодического тренда. Напротив, критерий поворотных точек может помочь в выявлении такого тренда, отвергая в такой ситуации гипотезу случайности.
Общий принцип состоит в том, что каждый конкретный критерий наилучшим образом работает при вполне определенных альтернативах, так что не существует одного универсального критерия проверки гипотезы случайности, эффективно работающего абсолютно во всех ситуациях. В связи с этим полезно иметь на вооружении арсенал критериев проверки случайности, которые в совокупности помогают либо принять модель случайной выборки либо отказаться от нее в пользу той или иной более сложной модели временного ряда.
Критерии согласия (goodness of fit tests). В приложениях интерес представляет проверка не только гипотезы о том, что наблюдаемый ряд значений следует модели случайной выборки, но и гипотез о том, что это случайная выборка из вполне определенного распределения F или что это случайная выборка из распределения, принадлежащего некоторому параметрическому семейству распределений, без уточнения параметров этого распределения.
В пакете EViews б для таких проверок предусмотрены встроенные процедуры, реализующие критерии, основанные на сравнении эмпирической функции распределения и специфицированной теоретической функции распределения и на использовании той или иной меры расхождения между этими функциями.
Для случайной выборки^, Хп эмпирическая функция распределения определяется формулой
"ГГЇ
где 1х <х — индикаторная функция, равная 1, если Xt < х, и равная 0 в противном случае.
Критерий Колмогорова (критерий Колмогорова — Смирнова) (Kolmogorov test, Kolmogorov-Smirnov test). Пусть эмпирическая функция распределения Fn(x) построена по случайной выборке объема п из непрерывного распределения с функцией распределения G(x). Пусть F(x) — заданная функция распределения. Проверяется гипотеза Н0 : G(x) = F(x).
Статистика Колмогорова определяется соотношением
D„=sUpF„(x)-F(x).
При гипотезе Н0 распределение случайной величины Dn не зависит от того, каково истинное распределение выборки. При гипотезе Н0 и п —» со статистика Dn —» О
с вероятностью 1. Поэтому чаще используют статистику 4п Dn, распределение которой имеет невырожденный предел. При гипотезе Я0 и п -> со функция распределения случайной величины yfn Dn сходится к функции некоторого специального распределения, которое называется распределением Колмогорова. Если условие G(x) = F(x) не выполняется, то при п —» со
Dn-+supG(x)-F(x)\>0,
х
так что <Jn Dn —» со. Отсюда вытекает правило: гипотезу Н0 следует отвергать, если наблюдаемое значение Dn слишком велико.
Нулевая гипотеза о том, что набор х19 хп соответствует случайной выборке из заранее специфицированного распределения F, отвергается на уровне значимости а, если
4^Dn>Kx_a,
где Кх_а — квантиль уровня (1 а) распределения Колмогорова.
При практическом вычислении значения статистики Dn можно воспользоваться соотношением
Z) = max
" \<Lk<n
n
в котором х{п) — вариационный ряд для х19 хп, полученный путем упорядочивания элементов рядах15хп по возрастанию.
Критерий Купера (Kuiper test). В отличие от статистики Колмогорова, статистика критерия Купера определяется соотношением
V„ = max
\<,k<,n
п
— F(X(k)) +max F(x(k))
M v ' \<k<n v '
k-l
Критерий Лиллиефорса (Lilliefors test) предназначен для проверки гипотезы о том, что набор х15 хп соответствует случайной выборке из нормального распределения, но значения параметров этого распределения (математического ожидания и дисперсии) не специфицируются заранее.
В данном случае сначала производится оценивание по имеющейся выборке математического ожидания и дисперсии распределения, а затем производится сравнение эмпирической функции распределения с функцией нормального распределения, имеющего в качестве параметров оцененные значения математического ожидания и дисперсии. Поскольку сравнение производится не с заранее заданной функцией распределения, а с функцией, параметры которой оценены по выборке, максимальное расхождение этих функций оказывается меньшим, и распределение статистики критерия будет другим (распределение Лиллиефорса).
Критерий Крамера — фон Мизеса (критерий омега-квадрат) (Cramer-von Mises, W2-test). Здесь в качестве меры расхождения между эмпирическим распределением Fn и теоретическим распределением F берется величина
00
W2=n \Fn(x)-F(xfdF(x).
Можно показать, что
і п
w2=—+Y
2п tx
2к2п
Критерий Андерсона — Дарлинга {Anderson-Darling test) является одним из наиболее мощных критериев для проверки нормальности, его можно использовать при малых выборках, п < 25. В качестве меры расхождения между эмпирическим распределением Fn и теоретическим распределением F берется величина
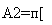 1
1
_iF(x)(l-F(x))
Fn(x)-F(x)2dF(x).
Пусть данные хх, ...,хп упорядочены по возрастанию. Эти данные стандартизуются на выборочное среднее и выборочную дисперсию:
Статистика критерия вычисляется по формуле
А2=-п-± — [in Ф{Гк) + In (1 Ф(7„+1_,))],
где Ф(х) — функция стандартного нормального распределения. Статистика, скорректированная на размер выборки, имеет вид:
А*2=А:
1 +
0.75 2.25
п п
Уровню значимости 0.05 соответствует отвержение нулевой гипотезы при А*2> 0.752.
Критерий Ватсона (Уотсона) (Watson test). В качестве меры расхождения между эмпирическим распределением Fn и теоретическим распределением F берется величина
оо Г оо ~) 2
U2=n UFn(x)-F(x)\[Fn(x)-F(x)]dF(x)dF(x).
При рассмотрении финансовых рядов отклонение от нормальности распределения часто проявляется в наличии у распределения F тяжелых (длинных) «хвостов», в более медленном убывании функции плотности при удалении от центра распределения по сравнению с плотностью нормального распределения. Такие отклонения улавливает статистика Харке — Бера:
JB = n
6 24
где у — выборочный коэффициент асимметрии рассматриваемого рядахх,хп; к — его выборочный эксцесс (к = выборочный куртозис 3),
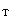 У =
У =
(и12)
3/2
, выборочный куртозис = —у, к = —у 3,
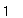 тк = — ^(х, х)к — выборочный центральный момент порядка к.
тк = — ^(х, х)к — выборочный центральный момент порядка к.
п —

Обсуждение Эконометрика Книга первая Часть 2
Комментарии, рецензии и отзывы