2.5. обобщенный метод наименьших квадратов (омнк)
2.5. обобщенный метод наименьших квадратов (омнк)
При нарушении гомоскедастичности и наличии автокорреляции ошибок рекомендуется традиционный метод наименьших квадратов (известный в английской терминологии как метод OLS Ordinary Least Squares) заменять обобщенным методом, т.е. методом GLS (Generalized Least Squares).
Обобщенный метод наименьших квадратов применяется к преобразованным данным и позволяет получать оценки, которые обладают не только свойством несмещенности, но и имеют меньшие выборочные дисперсии. Остановимся на использовании ОМНК для корректировки гетероскедастичности.
Как и раньше, будем предполагать, что среднее значение остаточных величин равно нулю. А вот дисперсия их не остается неизменной для разных значений фактора, а пропорциональна величине K,, т.е.
2 » 2
где sei дисперсия ошибки при конкретном i -м значении фактора; s постоянная дисперсия ошибки при соблюдении предпосылки о гомоскедастичности остатков; Ki коэффициент пропорциональности,
меняющийся с изменением величины фактора, что и обусловливает неоднородность дисперсии.
При этом предполагается, что s2 неизвестна, а в отношении величин Ki выдвигаются определенные гипотезы, характеризующие структуру гетероскедастичности.
В общем виде для уравнения y = a + bx{ + Є{ при &l = S2 • Ki
модель примет вид: yi = a + bxi + JlKi£i. В ней остаточные величины гетероскедастичны. Предполагая в них отсутствие автокорреляции, можно перейти к уравнению с гомоскедастичными остатками, поделив
все переменные, зафиксированные в ходе i-го наблюдения, на у[К .
2 2
Тогда дисперсия остатков будет величиной постоянной, т. е. <j£ = s .
Иными словами, от регрессии у по x мы перейдем к регрессии на новых переменных: у/\[К и xjy]~K. Уравнение регрессии примет вид:
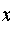
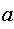 + b ■■
+ b ■■
Л/К №
а исходные данные для данного уравнения будут иметь вид:
у
| у | x1 | |
| , x = | ||
По отношению к обычной регрессии уравнение с новыми, преобразованными переменными представляет собой взвешенную
регрессию, в которой переменные у и x взяты с весами /у]~К .
Оценка параметров нового уравнения с преобразованными переменными приводит к взвешенному методу наименьших квадратов, для которого необходимо минимизировать сумму квадратов отклонений вида
n 1
S (a b)=Z к (у;a bxi )2.
i=1 Ki
Соответственно получим следующую систему нормальных уравнений:
Еа • У + Ь ■ У-, ^ К ^ К ^ K
У1^ = а■ у± + ь■ У . ^ К ^ К ^ К
Если преобразованные переменные х и y взять в отклонениях от средних уровней, то коэффициент регрессии Ь можно определить как
У — ■ x ■ y У ■ Xі
К
При обычном применении метода наименьших квадратов к уравнению линейной регрессии для переменных в отклонениях от средних уровней коэффициент регрессии Ь определяется по формуле:
Ь =
У x ■
Как видим, при использовании обобщенного МНК с целью корректировки гетероскедастичности коэффициент регрессии Ь представляет собой взвешенную величину по отношению к обычному МНК с весом 1/ К.
Аналогичный подход возможен не только для уравнения парной, но и для множественной регрессии. Предположим, что рассматривается модель вида
y = а + Ь1х1 + Ь2 x2 + e, для которой дисперсия остаточных величин оказалась пропорциональна К. Кі представляет собой коэффициент пропорциональности, принимающий различные значения для соответствующих значений факторов х1 и х2. Ввиду того, что
рассматриваемая модель примет вид
78
Уі = а + b, хи + b2 x2j + Кієі, где ошибки гетероскедастичны.
Для того чтобы получить уравнение, где остатки Єі
гомоскедастичны, перейдем к новым преобразованным переменным, разделив все члены исходного уравнения на коэффициент пропорциональности К. Уравнение с преобразованными переменными составит
К і К і 4 К і 2 К і ■
Это уравнение не содержит свободного члена. Вместе с тем, найдя переменные в новом преобразованном виде и применяя обычный МНК к ним, получим иную спецификацию модели:
Параметры такой модели зависят от концепции, принятой для коэффициента пропорциональности К . В эконометрических
исследованиях довольно часто выдвигается гипотеза, что остатки є пропорциональны значениям фактора. Так, если в уравнении
у = а + ^JC, + b2 х2 + ... + bmxm + Є
предположить, что Є = є■ хх, т.е. К = хх и (іЄ = &2 ' хх, то обобщенный
МНК предполагает оценку параметров следующего трансформированного уравнения:
У. = b, + b2 +... + + є.
х, х, х,
Применение в этом случае обобщенного МНК приводит к тому, что наблюдения с меньшими значениями преобразованных переменных х/ К имеют при определении параметров регрессии относительно больший
вес, чем с первоначальными переменными. Вместе с тем, следует иметь в
79
виду, что новые преобразованные переменные получают новое экономическое содержание и их регрессия имеет иной смысл, чем регрессия по исходным данным.
Пример. Пусть y издержки производства, x1 объем продукции,
x2 основные производственные фонды, x3 численность работников, тогда уравнение
y = a + b1x1 + b2 x2 + b3 x3 + e является моделью издержек производства с объемными факторами. Предполагая, что S пропорциональна квадрату численности
работников x3 , мы получим в качестве результативного признака затраты на одного работника y/x3, а в качестве факторов следующие показатели: производительность труда x1 /x3 и фондовооруженность труда x2 /x3 . Соответственно трансформированная модель примет вид
— = b3 + b[-L + b2 — + e,
где параметры b1, b2 , b3 численно не совпадают с аналогичными
параметрами предыдущей модели. Кроме этого, коэффициенты регрессии меняют экономическое содержание: из показателей силы связи, характеризующих среднее абсолютное изменение издержек производства с изменением абсолютной величины соответствующего фактора на единицу, они фиксируют при обобщенном МНК среднее изменение затрат на работника; с изменением производительности труда на единицу при неизменном уровне фондовооруженности труда; и с изменением фондовооруженности труда на единицу при неизменном уровне производительности труда.
Если предположить, что в модели с первоначальными переменными дисперсия остатков пропорциональна квадрату объема
2 2 2
продукции, se = S ■ x1 , можно перейти к уравнению регрессии вида
У і , x2 x3
= b + b2 — + b3 — + e.
x1 x1 x1
В нем новые переменные: yjx1 затраты на единицу (или на 1 руб.
продукции), x2jx1 фондоемкость продукции, x3/x1 трудоемкость продукции.
Гипотеза о пропорциональности остатков величине фактора может иметь реальное основание: при обработке недостаточно однородной совокупности, включающей как крупные, так и мелкие предприятия, большим объемным значениям фактора может соответствовать большая дисперсия результативного признака и большая дисперсия остаточных величин.
2 2 2
При наличии одной объясняющей переменной гипотеза Ge = S x
трансформирует линейное уравнение у = a + bx + e
в уравнение
= b + — + €,
xx
в котором параметры a и b поменялись местами, константа стала коэффициентом наклона линии регрессии, а коэффициент регрессии -свободным членом.
Пример. Рассматривая зависимость сбережений у от дохода x, по первоначальным данным было получено уравнение регрессии у =-1,081 + 0,1178 ■ x.
Применяя обобщенный МНК к данной модели в предположении, что ошибки пропорциональны доходу, было получено уравнение для преобразованных данных:
У = 0,1026 0,8538 • -x x
Коэффициент регрессии первого уравнения сравнивают со свободным членом второго уравнения, т.е. 0,1178 и 0,1026 оценки параметра b зависимости сбережений от дохода.
Переход к относительным величинам существенно снижает вариацию фактора и соответственно уменьшает дисперсию ошибки. Он представляет собой наиболее простой случай учета гетероскедастичности в регрессионных моделях с помощью обобщенного МНК. Процесс перехода к относительным величинам может быть осложнен выдвижением иных гипотез о пропорциональности ошибок относительно включенных в модель факторов. Использование той или иной гипотезы предполагает специальные исследования остаточных величин для соответствующих регрессионных моделей. Применение обобщенного МНК позволяет получить оценки параметров модели, обладающие меньшей дисперсией.
2.6. Регрессионные модели с переменной структурой (фиктивные переменные)
До сих пор в качестве факторов рассматривались экономические переменные, принимающие количественные значения в некотором интервале. Вместе с тем может оказаться необходимым включить в модель фактор, имеющий два или более качественных уровней. Это могут быть разного рода атрибутивные признаки, такие, например, как профессия, пол, образование, климатические условия, принадлежность к определенному региону. Чтобы ввести такие переменные в регрессионную модель, им должны быть присвоены те или иные цифровые метки, т.е. качественные переменные преобразованы в количественные. Такого вида сконструированные переменные в эконометрике принято называть фиктивными переменными.
Рассмотрим применение фиктивных переменных для функции спроса. Предположим, что по группе лиц мужского и женского пола изучается линейная зависимость потребления кофе от цены. В общем виде для совокупности обследуемых уравнение регрессии имеет вид:
y = a + bx + e, где y количество потребляемого кофе; x цена.
Аналогичные уравнения могут быть найдены отдельно для лиц мужского пола: y = a1 + b1 x1 + є1 и женского пола: y2 = a2 + b2 x2 + e2.
Различия в потреблении кофе проявятся в различии средних y и
y2. Вместе с тем сила влияния x на y может быть одинаковой, т.е.
b» b» b2. В этом случае возможно построение общего уравнения регрессии с включением в него фактора «пол» в виде фиктивной переменной. Объединяя уравнения y и y2 и, вводя фиктивные переменные, можно прийти к следующему выражению: y = a1 zx + a2 z2 + bx + e,
где z и z2 фиктивные переменные, принимающие значения:
[1 мужской пол, [ 0 мужской пол,
Z = z2 = <
[0 женский пол; [1 женский пол.
В общем уравнении регрессии зависимая переменная y рассматривается как функция не только цены x но и пола (z1, z2). Переменная z рассматривается как дихотомическая переменная, принимающая всего два значения: 1 и 0. При этом когда z1 = 1, то z2 = 0, и наоборот.
Для лиц мужского пола, когда z = 1 и z2 = 0, объединенное
,*ч
уравнение регрессии составит: y = а1 + Ьх, а для лиц женского пола,
✓ч
когда z1 = 0 и z2 = 1: y = а2 + Ьх. Иными словами, различия в потреблении для лиц мужского и женского пола вызваны различиями свободных членов уравнения регрессии: а1 Ф а2. Параметр Ь является общим для всей совокупности лиц, как для мужчин, так и для женщин.
Однако при введении двух фиктивных переменных z и z2 в
модель y = а1 zx + а2 z2 + Ьх +Є применение МНК для оценивания параметров а1 и а2 приведет к вырожденной матрице исходных данных,
а следовательно, и к невозможности получения их оценок. Объясняется это тем, что при использовании МНК в данном уравнении появляется свободный член, т.е. уравнение примет вид
y = A + а1 z + а2 z2 + Ьх + e.
Предполагая при параметре A независимую переменную, равную 1, имеем следующую матрицу исходных данных:
| " 1 | 1 | 0 | х1 |
| 1 | 1 | 0 | |
| 1 | 0 | 1 | хз |
| 1 | 1 | 0 | |
| 1 | 0 | 1 |
В рассматриваемой матрице существует линейная зависимость между первым, вторым и третьим столбцами: первый равен сумме второго и третьего столбцов. Поэтому матрица исходных факторов вырождена. Выходом из создавшегося затруднения может явиться переход к уравнениям
y = A + Az1 + Ьх +e
или
у = A + A2 z2 + Ьх +є, т.е. каждое уравнение включает только одну фиктивную переменную z, или z2.
Предположим, что определено уравнение у = A + Alzl + Ьх +є, где z, принимает значения 1 для мужчин и 0 для женщин.
Теоретические значения размера потребления кофе для мужчин будут получены из уравнения
у = A + A + Ьх. Для женщин соответствующие значения получим из уравнения
у = A + Ьх.
Сопоставляя эти результаты, видим, что различия в уровне потребления мужчин и женщин состоят в различии свободных членов данных уравнений: A для женщин и A + A для мужчин.
Теперь качественный фактор принимает только два состояния, которым соответствуют значения 1 и 0. Если же число градаций качественного признака-фактора превышает два, то в модель вводится несколько фиктивных переменных, число которых должно быть меньше числа качественных градаций. Только при соблюдении этого положения матрица исходных фиктивных переменных не будет линейно зависима и возможна оценка параметров модели.
Пример. Проанализируем зависимость цены двухкомнатной квартиры от ее полезной площади. При этом в модель могут быть введены фиктивные переменные, отражающие тип дома: «хрущевка», панельный, кирпичный.
При использовании трех категорий домов вводятся две фиктивные переменные: z, и z2. Пусть переменная z, принимает значение 1 для
панельного дома и 0 для всех остальных типов домов; переменная z2
85
принимает значение , для кирпичных домов и 0 для остальных; тогда переменные z и z2 принимают значения 0 для домов типа «хрущевки».
Предположим, что уравнение регрессии с фиктивными переменными составило:
у = 320 + 500х + 2200z +, 600z2. Частные уравнения регрессии для отдельных типов домов, свидетельствуя о наиболее высоких ценах квартир в панельных домах,
будут иметь следующий вид: «хрущевки» у = 320 + 500х; панельные
у = 2520 + 500х; кирпичные у = ,920 + 500х.
Параметры при фиктивных переменных z, и z2 представляют собой разность между средним уровнем результативного признака для соответствующей группы и базовой группы. В рассматриваемом примере за базу сравнения цены взяты дома «хрущевки», для которых z, = z2 = 0 .
Параметр при z, , равный 2200, означает, что при одной и той же
полезной площади квартиры цена ее в панельных домах в среднем на 2200 долл. США выше, чем в «хрущевках». Соответственно параметр при z2 показывает, что в кирпичных домах цена выше в среднем на ,600
долл. при неизменной величине полезной площади по сравнению с указанным типом домов.
В отдельных случаях может оказаться необходимым введение двух и более групп фиктивных переменных, т.е. двух и более качественных факторов, каждый из которых может иметь несколько градаций. Например, при изучении потребления некоторого товара наряду с факторами, имеющими количественное выражение (цена, доход на одного члена семьи, цена на взаимозаменяемые товары и др.), учитываются и качественные факторы. С их помощью оцениваются различия в потреблении отдельных социальных групп населения, дифференциация в потреблении по полу, национальному составу и др.
При построении такой модели из каждой группы фиктивных переменных следует исключить по одной переменной. Так, если модель будет включать три социальные группы, три возрастные категории и ряд экономических переменных, то она примет вид:
y = а + ^ + Ь2 S2 + Ьз z1 + Ь4 z2 + Ь5 х1 + Ь6 х2 + ... + Ьт+4 хт + ^
где y потребление;
[1 если наблюдения относятся к і-й социальной группе (і = 1, 2), [0 в остальных случаях;
[1 если наблюдения относятся кj-й возрастной группе (j = 1, 2), [0 в остальных случаях;
х1, х2, хт экономические (количественные) переменные.
До сих пор мы рассматривали фиктивные переменные как факторы, которые используются в регрессионной модели наряду с количественными переменными. Вместе с тем возможна регрессия только на фиктивных переменных. Например, изучается дифференциация заработной платы рабочих высокой квалификации по регионам страны. Модель заработной платы может иметь вид:
y = а + Ь z1 + Ь2 z2 + ... + bmzm,
где y средняя заработная плата рабочих высокой квалификации по
отдельным предприятиям;
[1 если предприятие находится в Северо-Западном районе; z = 1
[0 если предприятие находится в остальных районах;
[ 1 если предприятие находится в Волго-Вятском районе;
z2 = 1
[ 0 если предприятие находится в остальных районах;
[ 1 если преприятие находится в Дальневосточном районе;
zm = 1 0 .
[ 0 если предприятие находится в остальных районах.
Поскольку последний район, указанный в модели, обозначен zm, то
в исследование включено m + , район.
Мы рассмотрели модели с фиктивными переменными, в которых последние выступают факторами. Может возникнуть необходимость построить модель, в которой дихотомический признак, т.е. признак, который может принимать только два значения, играет роль результата. Подобного вида модели применяются, например, при обработке данных социологических опросов. В качестве зависимой переменной у
рассматриваются ответы на вопросы, данные в альтернативной форме: «да» или «нет». Поэтому зависимая переменная имеет два значения: ,, когда имеет место ответ «да», и 0 во всех остальных случаях. Модель такой зависимой переменной имеет вид:
у = а + b х, + ... + Ьтхт +є.
Модель является вероятностной линейной моделью. В ней у принимает значения , и 0, которым соответствуют вероятности p и , — p. Поэтому при решении модели находят оценку условной вероятности события у при фиксированных значениях х. Для оценки параметров линейно-вероятностной модели применяются методы Logit-, Probitи Tobit-анализа. Такого рода модели используют при работе с неколичественными переменными. Как правило, это модели выбора из заданного набора альтернатив. Зависимая переменная у представлена дискретными значениями (набор альтернатив), объясняющие переменные характеристики альтернатив (время, цена), характеристики
индивидов (возраст, доход, уровень образования). Модель такого рода позволяет предсказать долю индивидов в генеральной совокупности, которые выбирают данную альтернативу.
Среди моделей с фиктивными переменными наибольшими прогностическими возможностями обладают модели, в которых зависимая переменная у рассматривается как функция ряда
экономических факторов хі и фиктивных переменных zj. Последние
обычно отражают различия в формировании результативного признака по отдельным группам единиц совокупности, т.е. в результате неоднородной структуры пространственного или временного характера.

Обсуждение Эконометрика. Учебно-методическое пособие
Комментарии, рецензии и отзывы