3. анализ методов распознавания с точки зрения обеспечения гарантированной его достоверности
3. анализ методов распознавания с точки зрения обеспечения гарантированной его достоверности
Детерминистские (перцептронные) методы основаны на использовании перцептрона и обучения на основе принципа подкрепления наказания. Основная модель перцептрона, обеспечивающая отнесение образа к одному из двух классов, состоит из сетчатки S сенсорных элементов, соединенных с ассоциативными элементами сетчатки А, каждый элемент которой воспроизводит выходной сигнал только, если достаточное число сенсорных элементов, соединенных с его входом, находятся в возбужденном состоянии (рис.
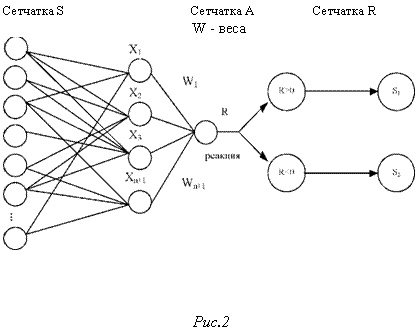 |
Реакция всей системы пропорциональна сумме взятых с определенными весами wi реакций хі элементов i ассоциативной сетчатки.
wixi =w x<
І=1 [<0^S 2. (3 1)
Разделение на несколько классов можно реализовать, добавив К элементов в R сетчатку (К число классов). Классификация проводится обычным способом: рассматриваются значения реакций R1, R2, Rк , и образ причисляется к классу Si, если Ri > Rj для всех j = i (метод «чемпиона»).
Обучение перцептрона по принципу подкрепления-наказания. Обучающий алгоритм сводится к простой схеме итеративного определения вектора весов W. Заданы два обучающих множества, представляющие классы S1 и S2 соответственно.
Пусть W (1) начальный вектор весов, выбираемый произвольно.
Тогда на k-ом шаге обучения, если x((k )є S и w (k) x(k)0, то вектор
весов w(k) заменяется вектором w(k +1) = w(k) + cx(k), где с -корректирующее приращение.
Если x (k)G S2 и w (k) x (k)" 0, то вектор w (k) заменяется вектором
w (k +1 ) = w (k)~ cx(k). В противном случае w (k) не изменяется, т. е. w (k +1) = w (k)
Таким образом, изменения в вектор весов W вносятся алгоритмом только в том случае, если образ, предъявляемый на k-ом шаге обучения, был при выполнении этого шага неправильно классифицирован, с помощью соответствующего вектора весов. Корректирующее приращение с должно быть положительным, и в данном случае предполагается, что оно постоянно.
Следовательно, алгоритм является процедурой типа "подкрепление-наказание", причем подкреплением является отсутствие наказания, т. е.
то, что в вектор весов W не вносится никаких изменений, если образ классифицирован правильно.
Если образ классифицирован неправильно, и произведение
w (k) x(k) оказывается меньше нуля, когда оно должно быть больше нуля, система "наказывается" увеличением вектора весов W(k) на величину, пропорциональную x(k. Точно так же, если произведение
w (k) x(k) оказывается больше нуля, когда оно должно быть меньше нуля, система наказывается противоположным образом.
Сходимость алгоритма наступает при правильной классификации всех образов с помощью некоторого вектора весов.
Основная задача, заключающаяся в выборе подходящего множества решающих функций, решается, в основном, методом проб и ошибок, поскольку, как указано в [4], единственным способом оценки качества выбранной системы является прямая проверка. Совершенно ясно, что отсутствие аналитических методов оценки достоверности распознавания, увязанной с параметрами распознающей процедуры, не позволяет обеспечить гарантированную достоверность распознавания в системах детерминистского распознавания, основанных на использовании перцепторных алгоритмов.
В лингвистическом (синтаксическом, структурном) подходе признаками служат подобразы (непроизводные элементы) и отношения, характеризующие структуру образа. Для описания образов через непроизводные элементы и их отношения используется «язык» образов. Правила такого языка, позволяющие составлять образы из непроизводных элементов, называются грамматикой. Грамматика определяет порядок построения образа из непроизводных элементов. При этом образ представляется некоторым предложением в соответствии с действующей грамматикой.

| Объекты, | Предв. | Построение | ||
| подлежащие | | | обработка | описания | | |
| растаиванию | w | объекта 9 |
Объекты
обучающей
выборки
Подсистема
вывода грамматики
Обучение (восстановление
грамматики класса)
Рис. 3
Распознавание состоит из двух этапов (рис.3):
определение непроизводных элементов и их отношений для конкретных типов объектов и обучение;
проведение синтаксического анализа предложения, представляющего объект, чтобы установить какая из имеющихся фиксированных грамматик могла породить имеющееся описание объекта (грамматический разбор) .
Грамматики часто удается определять на основе априорных сведений об объекте, в противном случае грамматики всех классов восстанавливаются в ходе обучения, которое использует априорные сведения об объектах и обучающую выборку. Объект после предварительной обработки (например, черно-белое изображение можно закодировать с помощью сетки, или матрицы нулей и единиц) представляется некоторой структурой языкового типа (например, цепочкой или графом). Затем он разбивается (сегментируется), определяются непроизводные элементы и отношения между ними. Так, при использовании операции соединения объект получает представление в виде цепочки соединенных непроизводных элементов.
Решение о синтаксической правильности представления объекта, т.е. о его принадлежности к определенному классу, задаваемому определенной грамматикой, вырабатывается синтаксическим анализатором (блоком грамматического разбора). Цепочка непроизводных элементов, представляющая поданный на вход системы объект, сопоставляется с цепочками непроизводных элементов, описывающими классы. Распознаваемый объект с помощью выбранного критерия согласия (подобия) относится к тому классу, с которым обнаруживается наилучшая близость.
Обучение: по заданному набору обучающих объектов, представленных описаниями структурного типа, делается вывод грамматики, характеризующей структурную информацию об изучаемом классе объектов. Структурное описание соответствующего класса формируется в процессе обучения на примере реальных объектов, относящихся к этому классу. Это эталонное описание в форме грамматики используется затем для синтаксического анализа. В более общем случае обучение может предусматривать определение наилучшего набора непроизводных элементов и получение соответствующего структурного описания классов.
Для распознавания двух классов объектов S1 и S2 необходимо описать их объекты с помощью признаков V (непроизводных элементов, подобразов). Каждый объект может рассматриваться как цепочка или предложение из V . Пусть существует грамматика Г1 такая, что порождаемый ею язык Ь(Г1) состоит из предложений (объектов), принадлежащих исключительно одному из классов (например, S1). Предъявляемый неизвестный объект можно отнести к S1, если он является предложением языка L (Г1), и к S2, если он является предложением языка L (Г2).
Выбор непроизводных элементов:
отрезок горизонтальной линии
b' 90°
отрезок вертикальной линии
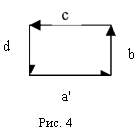 Пример. Распознавание прямоугольников на фоне других фигур (рис. 4) отрезок горизонтальной линии
Пример. Распознавание прямоугольников на фоне других фигур (рис. 4) отрезок горизонтальной линии
отрезок вертикальной линии
Множество всех возможных прямоугольников задается с помощью одного предложения цепочки ab с d . Составляем грамматику Г для прямоугольников, все другие грамматики не прямоугольников, наблюдаемый объект сопоставляется с грамматиками и принимается решение о его принадлежности.
Если же требуется различение прямоугольников разных размеров, то приведенное описание не адекватно. В качестве непроизводных элементов необходимо использовать отрезки единичной длины. Тогда множество прямоугольников различных размеров можно описывать с
помощью языка: L={a 'b 'с 'd 'n'т =1'2'-}.
Как указано в [5], структурный подход к распознаванию не располагает еще строгой математической теорией и рассматривается как комплекс практически работающих эвристических приемов. Это не позволяет увязать главный показатель качества распознавания -достоверность другими параметрами распознавания и, следовательно, не позволяет осуществить синтез распознающей системы, обеспечивающей гарантированную достоверность распознавания.
В логических системах распознавания [5] классы и признаки объектов рассматриваются как логические переменные. Все априорные
сведения о классах S1, S2 и признаках X1, X2, ... , Xp, присущих объектам классов S1, S2, полученные в результате проведения ряда экспериментов (обучения), также выражаются в виде булевых функций. Основным методом решения задач логического распознавания является метод построения сокращенного базиса с помощью алгоритмов получения произведения для булевых функций и отрицания булевой функции и приведения последней к тупиковой дизъюнктивной нормальной форме. Как указывается в [5], логические алгоритмы распознавания в ряде случаев не позволяют получить однозначное решение о принадлежности распознаваемого объекта к классу, а в тех случаях, когда такое решение удается найти, получить в аналитическом виде оценку достоверности распознавания через параметры распознающей системы оказывается невозможно, что делает необходимым использование метода Монте-Карло [5]. К тому же в системах логического распознавания основной упор делается на использование априорных знаний в ущерб процедуре обучения, количественная связь которой с достоверностью распознавания никак не установлена.
Дальнейшим развитием логических методов распознавания являются разработанные Ю. И. Журавлевым алгоритмы логического распознавания, основанные на вычислении оценок (АВО) [6] , которые, в отличие от указанных методов, обеспечивают возможность получения однозначного решения о принадлежности распознаваемых объектов к определенному классу. АВО основаны на вычислении оценок сходства, количественно характеризующих близость распознаваемого объекта к эталонным описаниям классов, построенным на основе использования обучающей и априорной информации, задаваемой в виде таблицы обучения.
Пусть множество объектов поделено на классы S1 , S2 , и объекты описаны одним и тем же набором признаков x1, x2, xp,
каждый из которых может принимать значения из множества (I0,1'--'d)),
для простоты из {0,1}.
Априорная информация представляется в виде таблицы обучения,
содержащей описания на языке признаков <■ 1 p> всех имеющихся объектов, принадлежащих различным классам (табл. 1).
Пример: Задана таблица обучения (табл. 1)
 |
Алгоритм распознавания сравнивает описание распознаваемого объекта w' с описанием всех объектов w1, w6 и по степени похожести (оценки) принимается решение, к какому классу (S1 или S2) относится объект. Классификация основана на вычислении степени похожести (оценки) распознаваемого объекта w' на объекты, принадлежность которых к классам известна. Эта процедура включает в себя три этапа: сначала подсчитывается оценка для каждого объекта w1, ... , w6 из таблицы, а затем полученные оценки используются для получения суммарных оценок по каждому из классов S1 и S2. Чтобы учесть взаимосвязь признаков, степень похожести объектов вычисляется не последовательным сопоставлением признаков, а сопоставлением всех возможных (или определенных) сочетаний признаков, входящих в описание объектов.
X = ix x }
Из полного набора признаков l р> выделяется система подмножеств множества признаков Z1, Zl (система опорных множеств признаков, либо все подмножества множества признаков фиксированной длины k, k = 2, p 1, либо вообще все подмножества множества признаков).
Для вычисления оценок по подмножеству Z1 выделяются столбцы, соответствующие признакам, входящим в Z1, остальные столбцы
вычеркиваются. Проверяется близость строки Z w' со строками
7 ' 7 '
Z W1 Z1 wr , принадлежащими объектам класса S1. Число строк этого класса, близких по выбранному критерию классифицируемой строке Z1
w' обозначается z^ ' оценка строки w' для класса S1 по опорному множеству Z1.
Аналогичным образом вычисляются оценки для класса S2:
z^ 2>, ... . Применение подобной процедуры ко всем остальным опорным множествам алгоритма позволяет использовать систему оценок
rz2 (w' ,S1 ),rz2 (w',S2 ),...,rzl (w',S1 ),rZl (W',S2 )
Величины
r(w, S1 )=r , S1 )+r , S1)+...+r2i(w, S1 )=Sr(w, S1)
za (3.2)
r(w', S2 ) = ^ (w', S2 )+Г22 (w', S2) +... + Г>', S 2 ) = ^r(W, S2)
представляют собой оценки строки w' для соответ-ствующих классов по системе опорных множеств алгоритма ZA. На основе анализа этих величин принимается решение об отнесении объекта w к классам S1 или S2 (например, к классу, которому соответствует максимальная оценка, либо эта оценка будет превышать оценку другого класса на определенную пороговую величину п и т. д.).
Так, в примере введем подмножества
Z1 = < x1,x2 >, Z2 = < x3,x4 >, Z3 = < x5 , x6 >
Строки будем считать близкими, если они полностью совпадают.
Тогда
Z1: (w', S1 ) = 1 (w' ,S 2 ) = 2
Z2: (w', S1 )= 2 (w',S 2 ) = 1 (33)
Z3: (wS1 ) = 1 (w ',S 2 ) = 0
Ггд (w',S1) = (w',S1) + (w', S1) + (w',S1) = 1 + 2 +1 = 4
Гг>', S 2 ) = Г21 (w', S 2 ) + Г22 (w', S 2 ) + Г23 (w', S 2 ) = 2 +1 + 0 = 3
Согласно решающему правилу, реализующему принцип простого большинства голосов, объект w' относится к классу S1, так как r(wS )>Г( wS 2) ^
Дальнейшим обобщением АВО является алгебраический подход к решению задач распознавания и классификации [6], позволяющий преодолеть ограниченные возможности существующих алгоритмов распознавания путем расширения их семейства с помощью алгебраических операций, введения алгебры на множестве решаемых и близких к ним задач распознавания и построения алгебраического замыкания семейства алгоритмов решения указанных задач. К сожалению, методы количественной оценки достоверности распознавания при использовании АВО и алгебраического подхода к решению задач распознавания, позволяющие в аналитическом виде увязать вероятности ошибок распознавания с параметрами распознающей системы (временем обучения и принятия решения, межклассовым расстоянием и размерностью признакового пространства), в настоящее время отсутствуют [6], что не позволяет обеспечить гарантированную достоверность в указанных системах распознавания.
- (в (x 1 ,... , x/S 2 )
■ Ll = ~г~? ч" — C
а> (x 1,... , xn /S1 )
Блок принятия решения
-атчик —
/S1)
./S1)
 |
М> [Xj,... ,xn/Sj ) (3.4)
представляющая неотрицательную случайную величину,
получаемую функциональным преобразованием Z=L(Xl'---'Xn), которое отображает точки n-мерного пространства выборок на действительную полуось. Таким образом, для вынесения решения, достаточно использовать значение одной случайной величины статистики
L (x x )
отношения правдоподобия v 1v"' n>, а не значения каждого элемента выборки (x1, x2, xn) по отдельности. То есть отношение
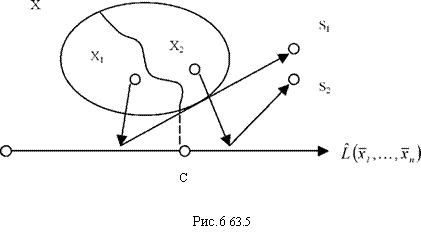 |
правдоподобия несет всю статистическую информацию о классах, содержащуюся в данной выборке. Подобная статистика называется достаточной и приводит к редукции наблюдаемых данных: отображению выборочного n-мерного пространства X на действительную положительную полуось (рис. 6).
Поверхность в n-мерном выборочном пространстве, разделяющая пространство X на подпространства X1 и X2, Поверхность в n-мерном выборочном пространстве, разделяющая пространство X на подпространства X1 и X2 , отображается в точку С на оси L > 0. Принятие решения теперь состоит в отображении интервала 0 < L < C в точку S1 и интервала L > С в точку S2. Сводим векторную задачу к скалярной.
Любое монотонное преобразование x^[Lj(xi )J достаточной статистики отношения правдоподобия также представляет достаточную
Wl )= InL (x x )
статистику. Например, v / v 1V''' n>. Если элементы выборки независимы, то имеем сумму
lnL(x) = lnL(xi,...,xn) = £lnL(xі)=£ln W(Xl/SS2)
Для нахождения вероятности ошибок распознавания достаточно располагать распределением отношения правдоподобия (или его логарифма), которое в свою очередь определяется по правилам нахождения функций от случайных величин.
Редукция данных позволяет преодолеть трудности, связанные с вычислением n-кратных интегралов, возникающие при прямом (без введения отношения правдоподобия) вычислении вероятностей ложных тревог а и пропуска цели р.
а =| w (x / S} )dx=jj w (x} ,...,xn / S} ^)dx1dxn, р =| w (x / S2 )dx
X2 X2 X1 (3.6)
Так как событие x gx-2 эквивалентно событию L(x)~ C, а событие
x событию L(x) < C, то вероятности ошибок распознавания а и в представляются однократными интегралами.
ад
a = ?L(x)>c/ S1}= fwL (z /S1 )dz = 1 -F-(c/ S1)
c ~ , (3.7)
в = р/(x)c / S2 }=j ((/ S2 )z=Fl (c / S2)
° , (3.8) $
или, переходя к логарифмам отношения правдоподобия ln L(x) [(см. (3.5)]:
ад
а =P//n L(x)> /no / S1}= j wn L (z / S1 )dz=1-Fn L (in c / S1)
ln c , (3.9)
in c
e = P{/n L(x)< inc / S2 }= j w/nl (z / S2)dz=F/nl (in c / S2 )
0 , (3.10)
где
wLL(z/S1)FL(z/S1)wLL(z/S2)FL((/ S2)(w/nL(z/S1)'F/nL(z/S1)w/nL(z/ S2),F/nL(z/ S2)) соответственно
плотности вероятности и функции распределения статистики отношения
правдоподобия L (или его логарифма ln L) при наличии классов S1 и S2.
Таким образом вероятности ошибок распознавания аналитически выражаются через объемы обучающей и контрольной выборок, размерность признакового пространства (размерность вектора x) и межклассовые расстояния (в отношении правдоподобия), что позволяет выбрать параметры, гарантируя достоверность распознавания и используя всю информацию о классах, содержащуюся в измерениях.
Важнейшей особенностью реальных систем распознавания, которая практически не учитывается в других рассмотренных (кроме статистического) детерминистских (перцептронных), синтаксических (лингвистических), логических, в том числе с использованием АВО, алгебраических системах распознавания, является то, что наблюдения
і і,---, л неизбежно подвержены многочисленным случайным возмущениям, непредсказуемый, вероятностный характер которых проявляется на всех этапах, начиная с процесса получения самих наблюдений и кончая процессом принятия решения, который всегда является случайным. Дестабилизирующие факторы выступают в распознавании как погрешности измерительных приборов, неточности регистрации, шумы в каналах связи при передаче данных измерений, аппаратурные шумы, наконец, как ошибки округления при вычислениях, являющиеся следствием ограниченности разрядной сетки ЭВМ. Взаимодействуя между собой, указанные возмущения приводят к тому, что наблюдения неизбежно оказываются реализациями случайных величин. Отсюда видно, что разработка адекватных исследуемым процессам методов распознавания неизбежно связана с исследованием случайных отображений, что оказывается возможным только на основе статистических методов. Следовательно, только статистические методы распознавания [1, 2] позволяют в полной мере отразить тонкую структуру и все особенности проявления распознаваемых объектов через описывающие их признаки как при обучении, так и при принятии решений с учетом всех дестабилизирующих факторов, и количественно описать указанные процессы, используя хорошо развитые методы математической статистики. Это создает основу для количественного выражения основных параметров распознающего процесса -размерности признакового пространства, времени обучения и принятия решения через главный показатель качества системы достоверность распознавания, что в свою очередь позволяет реализовать в системах статистического распознавания гарантированную достоверность распознавания.
Таким образом, проведенное сопоставление наиболее распространенных методов распознавания с точки зрения гарантированной достоверности распознавания показывает, что единственным методом, обеспечивающим полное адекватное описание исследуемых объектов с учетом всех дестабилизирующих факторов и на этой основе позволяющим количественно выразить главный показатель качества достоверность распознавания через все основные параметры распознающей системы: время обучения и распознавания, размерность признакового пространства и межклассовые расстояния, является статистический метод распознавания, на основе которого и будет строиться все дальнейшее изложение.

Обсуждение Диагностика кризисного состояния предприятия
Комментарии, рецензии и отзывы