5. обучение
5. обучение
Непараметрическое обучение (оценивание неизвестных плотностей вероятностей наблюдений). Источником информации о распознаваемых образах является совокупность результатов независимых наблюдений (выборочных значений), составляющих обучающие (xi(1))1m = (x1(1),
(х (2)) m =(х(2) x(2) X(2)) /
x2(1), ... , xm(1)), ^1 11 1 > 2 -■> m/и контрольную (экзаменационную) (xi)1n = (x1, x2, xn) выборки. В зависимости от характера задачи распознавания (одномерной или многомерной) хі может быть либо одномерной, либо р-мерной величиной. Основной целью обучения являются преодоление априорной неопределенности о распознаваемых классах S1 и S2 путем использования информации о них, содержащейся в обучающих выборках и построение эталонных описаний классов оценок условных плотностей вероятностей "V 1>2>---> m ^ и
wn ((1, x2,..., xm / S 2 ) ^
Решающее значение для выбора метода распознавания имеет вид априорной неопределенности, для преодоления которой используется обучение.
В наиболее общем случае отсутствия априорных сведений не только о параметрах, но и о самом виде закона распределения наблюдаемой совокупности выборочных значений, априорная неопределенность носит название непараметрической [2] , а сами методы распознавания, применяемые в этих условия, именуются непараметрическими. Таким образом случай непараметрического обучения является самым общим и его содержанием является статистическое оценивание неизвестных условных плотностей
вероятностей wn(x1,...'xm /S),i =1,2 признаков X1, ... , Хр. Наиболее распространенными методами статистического оценивания неизвестных плотностей вероятностей скалярных и векторных наблюдений являются гистограммный, полигональный методы, представление плотности вероятности линейной комбинацией базисных функцийи др.
Гистограммная оценка неизвестной плотности вероятности [7] строится в виде ступенчатой кривой: над каждым отрезком оси абсцисс, изображающим интервал значений наблюдаемой величины (значения признака Хі), строится прямоугольник, площадь которого пропорциональна частоте попаданий наблюдений в этот интервал. При равной ширине интервалов (что обычно и бывает) высоты прямоугольников пропорциональны частотам. Гистограммный метод обобщается и на многомерный случай. Так, для представления двумерного распределения строятся трехмерные фигуры. Горизонтальная плоскость делится на клетки как шахматная доска. В центре клетки восстанавливается перпендикуляр, пропорциональный по своей длине частоте, отвечающей интервалу. На нем строится прямоугольный параллелепипед, по объему пропорциональный частоте, соответствующей этой клетке. Полученная объемная фигура является двумерной гистограммой.
Полигональные оценки получают путем сглаживания гистограммы, соединяя прямыми линиями крайние левые, средние или крайние правые точки верхних столбиков, в результате получается кусочно-линейные функции (ломаные). Иногда кусочно-линейные функции состоят из отрезков прямых, проведенных с учетом разности высот соседних столбиков. Подобные аппроксимации не обязательно имеют вид обычных ломаных, концы отдельных прямых могут не совпадать, а соединяться вертикальными прямыми. Такой оценкой, в частности, является полигон Смирнова [7]. Полигональные оценки, как и гистограммные, обобщаются и на многомерный случай.
Оценивание плотности вероятности может быть также осуществлено путем представления ее линейной комбинацией базисных функций. Одномерная плотность вероятности w(x) может быть представлена разложением в ряд по базисным ортогональным функциям
{Qn(x)} с весовой функцией .
00
w(x) = (P(x)Y4 CkQk (x)
k=o (5.1)
Коэффициенты Ck можно определить, умножив обе части (5.1) на функцию Qn(x) и проинтегрировав с использованием условия ортогональности:
00
(p{x)Qk (x) Qn (x)dx = $kn
Ю (5.2),
Я =J1 'k = n где L ' n символ Кронекера (5.3).
При этом в сумме все члены, за исключением одного при k = n, равны нулю и, следовательно
0
-Ю . (5.4)
Если {Qn(x)} совокупность ортогональных номиналов, то
Qn (x) = t aux"
"=0 , (5.5)
тогда, так как по определению момента mr случайной величины rого порядка
(5.6)
mr = J w(x)xrdx
—ад
то
n
Cn = 2 armr
r = 0
(5.7)
и, следовательно, подставляя значение Cn из (5.7) в (5.1)
ад k
w(x) = <p(xYL 2 Qk (x)armr
к=0 r=0 (5.8) при условии, что моменты mr существуют.
В качестве примера рассмотрим наблюдения \% с нулевым средним и единичной функцией (т.е. нормированные и центрированные [
переход к произвольным наблюдениям с а и * дает v * j , и произведем разложение неизвестной плотности вероятности w(x) в ряд по полиномам Эрмита Hn(x)
2 2
Нn(x) = (—1)neХ~ —є, n = 0,1,2,... Д ' К ] dxn ' " ' (5.9)
Учитывая условия нормировки (5.2), получаем из (5.1) с учетом того, что p(xx) = (l/^/2n)exp {— x 12}-нормальная плотность вероятности:
2
і x ад s-1
w(x) = -і= є S H (x) w /2п k=Wk! v^ (510)
где
1 ад 1
Ck =~m J w\%(x), Hk(x) dx = _7kT m1 iHk \%}
Vk! - Vk! , (5.11)
причем С0 = 1, а вследствие принятой нормировки случайной
величины \% имеем С1 = С2 = 0.
Используя определение полиномов Эрмита (5.9), можно (5.10) переписать в виде:
д
w\%(x ) = *x ) + S(—1)k^^ <?W(x)
•=3 Л! , (5.12)
где P k-я производная нормальной плотности распределения. Вычислим несколько коэффициентов Ck в ряду (5.12) по формуле
(5.11).
1 00 к
V3! » V3 , (5.13)
j CO
C4 =—j= I(x4 6x2 +3)w^{:x)dx=^Y=
V4 -Y V4 , (5.14)
где k и Y соответственно коэффициенты асимметрии и эксцесса
к = ~Tf
(5.15)
^4 о
, (5.16)
а , , соответственно второй, третий, четвертый центральный моменты распределения, в качестве которых можно использовать
выборочные центральные моменты ^2' ^3' ^4, полученные по выборке наблюдений. Подставляя (5.13) и (5.14) в (5.12), получаем в результате
приближенную оценку неизвестной плотности вероятности w^(x):
w£(x) = cp(x) (p(4x) + ?-q>(4x)... n; v ; 3 w 4 w (517)
Оценивание неизвестной плотности вероятности линейной комбинацией базисных функций обобщается и на многомерные плотности вероятности. Однако, в этом случае, отыскание универсальной системы базисных функций и вычисление коэффициентов разложения становится трудной задачей. Одним из методов нахождения коэффициентов разложения является метод последовательных приближений, известный под названием метода потенциальных функций.
Существуют и другие методы оценивания плотности вероятности, в том числе метод Парзена и метод k ближайших соседей, основанные на суммировании наблюдений с некоторыми весовыми функциями, называемыми обычно ядром и выбираемыми таким образом, чтобы возможно больше "размазать" столбики и в итоге получить более гладкую аппроксимацию неизвестной плотности вероятности.
Представляется более обоснованным исходить при оценивании
плотности вероятности w(x из ее определения как производной от функции распределения F(x) с использованием известных методов численного дифференцирования [2, 8]. В настоящее время достаточно хорошо развиты методы оценивания функций распределения эмпирическими ступенчатыми функциями, определена точность оценивания для конечных объемов выборок при различных способах
задания расстояния между F(x) и ее оценкой F( x) [2].
Нахождение производной представляет собой линейную операцию с последующим переходом к пределу. Ввиду этого можно попытаться построить линейную комбинацию значений эмпирической функции, которая при асимптотическом росте объемов обучающих выборок m —» со сходилась бы по вероятности к F(x), а при конечных фиксированных m позволяла оценить погрешность аппроксимации плотности по известным характеристикам эмпирической функции распределения. При этом мы можем пользоваться значениями эмпирической функции
распределения F(X во всех точках х области ее определения. Если раньше при оценивании плотности мы могли использовать в формулах только конечное множество обучающих наблюдений, то теперь
получаем в свое распоряжение бесконечную выборку значений F(Х). Таким путем ликвидируется основной источник трудностей непараметрического оценивания плотности вероятности w(x): в отличие
{w(x)} {F(x)}
от множество исходных данных становится равномощным
множеству значений оцениваемой функции распределения F(x).
Пусть для обучения используются одномерные (р = 1)
классифицированные обучающие выборки 1 m / и w m /.
Для получения оценок условных функций распределения F (x / Sl) и
F(Х/S ) Е(1)(А
Al^2j рассмотрим одномерные условные случайные процессы ^ и
^ ((), относительно которых мы будем полагать (в некоторых случаях, быть может, с определенным приближением), что они удовлетворяют условию эргодичности [2,3]. Эти процессы представляют собой случайные изменения во времени значений признака Х при условии, что наблюдаемая совокупность принадлежит одному из классов соответственно S1 или S2. Тогда отношение суммарного времени
k пребывания реализации случайного процесса £,(t) под некоторым уровнем х к длительности реализации Т (0 < T < оо).
k
(5.18)
(здесь tk длительность k-го выброса £,(t) под уровнем х) может
рассматриваться как оценка F(x) функции распределения F(x) случайного процесса £,(t), которая является несмещенной и состоятельной [2].
Пусть теперь для обучения используются р-мерные классифицированные обучающие выборки,
(Х О) Х fХ <2) Х <2)Л1
х о х о
лр1 > лрп
и
Х Х
лр1 ' лрш j
Для получения оценок условных многомерных функций
F (Х Х Х / S ) F (Х Х Х / S ) распределения pV и 2'"'' p и и pV С 2'"'' p 2> рассмотрим векторные
- (А i(2) (А
р мерные условные случайные процессы s py' и s p"f, которые, как и в рассмотренном выше одномерном случае, мы будем полагать, хотя бы приближенно, эргодическими [2, 3].
Тогда отношение суммарного времени k пребывания реализации
\% (t)
р-мерного векторного случайного процесса pW внутри области, ограниченной некоторой гиперплоскостью Q(x1, x2, ... , xp) (т.е. пребывания процесса \%1(t) ниже уровня х1, процесса \%2(t) ниже х2, ... , процесса \%p(t) ниже хр) к длительности реализации Т(0<Т<ад),
Fp ((1,x2r.., xp ^ S *k
T k (5.19)
может рассматриваться как оценка Fp (x1' x2v..'xp) р-мерной функции
распределения случайного процесса p , которая является несмещенной и состоятельной [2].
Функции распределения F (x/Sk )=Fk (x ),k =1,2; содержат всю информацию о классах образов. Поэтому наиболее естественным было бы построение правила принятия решения на основе эмпирических функций распределения Fk (х). Указанные функции концентрируют всю
информацию, содержащуюся в обучающих выборках ^m(k)}, и позволяют оценивать точность аппроксимации функций Fk(x) при любых объемах m. Однако на сегодняшний день все правила принятия решений в статистическом распознавании строятся с использованием плотностей вероятностей.
Для приведения в соответствие структуры решающего правила, использующего плотности вероятностей признаков, и вида исходных данных, представленных выражениями эмпирических функций распределения, необходимо по эмпирическим функциям распределения
Fk (x) сформировать оценки плотностей wk (x) и подставить их в решающее правило вместо априорно неизвестных плотностей wk(x).
При этом требуется, чтобы оценки wk (x) сходились к априорно неизвестным плотностям wk(x) при асимптотическом увеличении объемов обучающих выборок. В результате мы приходим к двухэтапной процедуре обучения. На первом этапе по обучающим выборкам строятся эмпирические функции распределения для всех классов образов. На втором этапе по эмпирическим функциям распределения формируют оценки плотностей вероятностей с использованием известных методов численного дифференцирования [8] и известных соотношений:
x
w(x )=dF (x )/dx,F (x )= J w(y )dy
—ад . (5.20)
( ) д PFP (x1,x2,...,xp )
w^x1 ,x2 ,...,xp )= —
д x1д x2...d xp (5 21)
-ад -ад
В качестве примера можно привести полученную с использованием
методов численного дифференцирования оценку Розенблатта [2] ®(x) одномерной плотности вероятности co(x) со (x) = F (x + h)F (x h)/2h
где h > 0 некоторый параметр.
ПРИБЛИЖЕННЫЙ МЕТОД СВЕДЕНИЯ НЕПАРАМЕТРИЧЕСКОЙ АПРИОРНОЙ НЕОПРЕДЕЛЕННОСТИ К ПАРАМЕТРИЧЕСКОЙ. Если в результате предварительного анализа наблюдаемой совокупности выборочных значений можно хотя бы с некоторым приближением установить вид закона их распределения, то априорная неопределенность относится лишь к параметрам этого распределения, так что целью обучения в этом случае становится получение оценок этих параметров. Подобная априорная неопределенность носит название параметрической, а методы распознавания, применяемые в этих условиях, именуются параметрическими. Хотя с формальной точки зрения закон распределения выборочных значений может быть произвольным, на практике в параметрическом распознавании почти всегда используется нормальный закон. Дело в том, что если при распознавании одномерных совокупностей их распределение всегда может быть описано одним (например, нормальным, биноминальным, экспоненциальным, пуассоновским и др.) законом, то при распознавании многомерных совокупностей каждая компонента вектора выборочных значений (т. е. наблюдаемые значения каждого признака) может иметь свой отличный от других компонент закон распределения (что не может рассматриваться как аномалия, поскольку сам ансамбль признаков формируется, таким образом, чтобы возможно полнее охарактеризовать различные свойства распознаваемых явлений). Но тогда многомерное совместное распределение совокупности выборочных значений должно описываться некоторым многомерным законом, включающим в себя компоненты с различными законами распределения.
В литературе аналитические выражения подобных «разнокомпонентных» законов отсутствуют. К этому следует добавить, что, как указано в [8], «современный уровень знаний таков, что пока точному многомерному анализу, за редкими исключениями, поддаются лишь задачи, где рассматривается нормальный случай» и, следовательно, как указывается в [9], «почти все выводы многомерной статистики опираются на предположения о нормальности рассматриваемых распределений». Отсюда следует, что на сегодняшний день параметрические методы распознавания, по-существу, являются методами распознавания нормально распределенных совокупностей, так что задачей параметрического обучения в этих условиях является оценивание параметров (средних, дисперсий, ковариационных матриц) нормальных плотностей вероятностей, используемых в решающем правиле.
Большие вычислительные сложности и трудности математического порядка, связанные с вычисление непараметрической оценки плотностей вероятностей делает целесообразными попытки сведения непараметрической априорной неопределенности к параметрической.
Если для обеспечения достоверности, равной 1 а = 0,9 требуемая сумма объемов обучающей и контрольной выборки составляет при расстоянии между совокупностями as = 0,1 m + n = 2200, то при применении непараметрического подхода для достижения такой же достоверности необходимо располагать объемом m + n = 9000 11600, т. е. « в 5 раз больше [1]. Следовательно, если бы мы смогли ограничивать затраты на переход от непараметрической к параметрической неопределенности 5-кратным увеличением выборок, это было бы вполне оправданно.
Пусть \%1, \%q последовательность независимых одинаково распределенных случайных величин, имеющих конечные средние m1{\%k} = а и дисперсии u2{\%k} = *2. Тогда последовательность нормированных и центрированных сумм 1 q
°Vq k=1 (5.22) сходится по распределению к стандартной гауссовской нормальной величине, что равносильно утверждению
-V s(\% k—a ^ 4=-/== J exp|—v ldu=f (x)
4q k=1 J v2n —ад v 2 J (5 23)
т. е. последовательность функций распределения сумм nq независимых одинаково распределенных случайных величин \%k при q ^ ад сходится к гауссовской (нормальной) функции распределения с параметрами (0; 1). Эта формула является аналитическим выражением центральной предельной теоремы теории вероятностей, которая легко
обобщается на многомерный случай. Пусть S1' 'Sqпоследовательность р-мерных независимых векторных случайных величин с одинаковыми р-мерными функциями распределения, компоненты которых могут быть распределенными по разным законам (разнораспределенными) с вектором средних a и ковариационными матрицами M. Тогда последовательность р-мерных функций распределения сумм
nq =-q S((k — a)
Vq k=1 (5.24)
при q —» ад сходится к р-мерной гауссовской (нормальной) функции распределения с нулевым вектором средних и ковариационной матрицей
М.
Приближенное выражение плотности распределения суммы nq с точностью до малых порядка О (1/q3/2) получается с использованием оценки (5.17) [1]:
x2
^(x ^ expl
.^и 3 (x ) + JL H 4 (x ) + -*H 6
6^1 q 24q 72q
J, (5.25)
где к и у коэффициенты асимметрии и эксцесса, вычисляемые по формулам (5.15) и (5.16), а Hk(x) полиномы Эрмита (см. формулу
(5.9)).
Как видно из анализа формулы (5.25) приближенное выражение плотности вероятности суммы nq представляет собой очень быстро сходящийся ряд, что свидетельствует о том, что приближенная нормализация суммы nq наступает уже при достаточно малых значениях q, в особенности, если исходное распределение W£,(x) является симметричным (в этом случае коэффициент асимметрии k, как известно, равен нулю и, следовательно вносящие ощутимый вклад в значение
q второй и четвертый члены суммы исчезают).
Детальный анализ влияния числа q членов суммы nq на скорость ее нормализации осуществлен в работе [1], в результате чего установлено, что для наиболее распространенных в практических приложениях законов распределения приближенная нормализация суммы nq наступает при q = 3 5. Рассмотрим два наиболее сильно отличающихся как от нормального закона, так и друг от друга закона распределения: равномерный
b 1 при 0 <С< b;
(С.) :
рк" [ 0 приС< 0,С> b, (526)
и экспоненциальный
= <
fp-1exp(-C/p) при С> 0;
0 при С< 0;
p > 0.
(5.27)
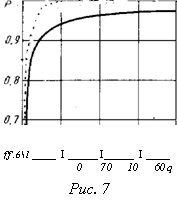
На рис. 7 представлена полученная в[1] зависимость уровня
нормальности суммарных распределений (x) суммы nq независимых равномерно (точечная кривая) и экспоненциально (сплошная кривая) распределенных случайных величин от количества суммарных членов q. Как видно из рисунка, допустимый уровень нормальности р = 0,85 достигается в случае равномерного распределения уже при q = 2 (это объясняется тем, что оно является симметричным), а в случае чрезвычайно асимметричного (и, следовательно, наиболее трудного для осуществления нормализации) экспоненциального распределения при вполне допустимом в практических приложениях значении q = 5.
 |
При нормальном распределении признака для построения эталонных описаний классов достаточно вычислить выборочные средние и дисперсии по классифицированным обучающим выборкам
m
1 m 1
m,=1 m~ , (5.28)
которые представляют собой [2] оценки максимального правдоподобия указанных параметров.
Как известно [1], выборочные среднее и дисперсия (5.28) являются
состоятельными оценками среднего и дисперсии, а ак является к тому же и несмещенной оценкой среднего. Для устранения небольшого смещения оценки (5.28) дисперсии достаточно умножить ее на m/(m 1) и получить следующее выражение выборочной дисперсии: m , ч „
А2 1
* m -, (5.29) которое дает не только состоятельную, но и несмещенную оценку дисперсии нормального распределения [2].
В многомерном случае процесс построения эталонных описаний классов при нормальном распределении совокупности признаков X1, Х2, Хр также упрощается, так как вместо весьма громоздких и трудоемких процедур формирования оценок условных р-мерных
плотностей вероятности достаточно лишь вычислить по выборке v 1 h из sk выборочный вектор средних
Кк = — £ XT = [ХП , Х2г, ХРг k = 1 2
m i=i (5.30) и выборочную ковариационную матрицу
i=i (5.31) которые являются оценками максимального правдоподобия вектора
средних К и ковариационной матрицы Mk рассматриваемой нормальной совокупности [2]. Здесь и далее знак Т означает операцию транспонирования.
Выборочные вектор средних (5.30) и ковариационная матрица (5.31) являются состоятельными оценками, причем (5.30), кроме того, несмещенная, тогда как оценка (5.31) ковариационной матрицы смещенная, поскольку ее среднее значение
mi }=[(m -1)) mR. (5 32)
Несмещенная оценка ковариационной матрицы получается умножением (5.31) на m /( m — 1): 1
M = £fe(k)-К )(*?)-К ), k = 1,2
m 1i==1 (5.33) 6. Принятие решений
Выбор оптимального решающего правила, позволяющего наилучшим образом относить контрольную выборку наблюдений к одному из взаимоисключающих классов s1 и s2, производится в соответствии с теорией статистических решений [2, 8] с использованием характеристик, полученных в процессе обучения. В рамках этой теории все виды решающих правил основаны на формировании отношения правдоподобия L (или его логарифма ln L) и его сравнении с определенным порогом с, (или ln с) (значение которого определяется выбранным критерием качества [2])
У 2 У 2
ГО n (Xj , x2 , x„S2 )> . т . И n iXJ , x2 , ■■■ , xnS2 )>,
L = -, —г с, ln L = ln -, —г ln с,
ГО n , x2 , K , xn|SJ ) < ГО n [Xj , x2 , к , x„Sj ) <
yj yj (6.1)
где ron (x1, x2, xn I sj) условная совместная плотность вероятности векторов выборочных значений x1, x2, ... , xn (функция правдоподобия) при условии их принадлежности к классу Sj, j = 1, 2. Однако если в теории статистических решений указанные плотности ron (x1, x2, ... , xn sj) являются априорно известными, то в статистическом распознавании они в принципе не известны, вследствие чего в решающее правило подставляются не сами плотности вероятности ron
(x1, x2, xn I sj), а их оценки "ч 1 л' "і ", получаемые в процессе обучения, поэтому в решающем правиле с порогом с сравнивается уже не само отношение
правдоподобия L, а его оценка L:
72
L = ®n (х1' x2 • K > xns2 ) > c ®n (x1' x2' K' xns1 ) <
7i (6.2)
При L — с принимается решение y2: контрольная выборка
принадлежит классу s2, в противном случае (при L <с) она считается принадлежащей классу s1 и, следовательно, принимается решение у1.
На практике помимо обучающих выборок иногда имеется и другая дополнительная информация о классах образов, могут выдвигаться различные требования к продолжительности, стоимости обучения и распознавания, достоверности решений и т. д. Дополнительные сведения влияют на выбор порога и способ сравнения оценок отношений правдоподобия с порогами. Так, в ряде случаев известно, что некоторый класс sk чаще предъявляется для распознавания, чем другие. Целесообразно тогда при формировании отношений правдоподобия L
го x x x s )
придать больший вес функции правдоподобия nV 1 2,"": ^ к' по сравнению с другими.
Указанная дополнительная информация учитывается путем выбора наиболее подходящего решающего правила из имеющегося в теории статистических решений широкого ассортимента критериев: байесовского, Неймана-Пирсона, минимаксного, Вальда, максимума апостериорной вероятности, максимального правдоподобия и др.
В теории статистических решений полный комплект априорных данных включает в себя априорные вероятности P1 = P(S1) и P2 = P(S2) классов S1 и S2 и матрицу потерь (платежную матрицу) П:
п = | 11 12 п21 п22
(6.3)
где Пк1 потери от принятия решения о том, что имеет место класс k, тогда как на самом деле имеет место класс 1 (k, 1 = 1, 2).
В качестве ориентировочных прикидочных значений априорных вероятностей P1 и P2 классов S1 и S2 можно в первом приближении принять к примеру соответственно отношение числа процветающих р и убыточных г фирм к общему числу p + г рассматриваемых фирм в отрасли. При рассмотрении функций потерь Пк1 можно учесть то очевидное обстоятельство, что потери П12 от принятия решения у1 о том, что фирма находится в процветающем состоянии, тогда как на самом деле имеет место класс S2 фирма убыточна (кризис), должны быть приняты намного большими, чем потери П21 от принятия решения о том, что фирма убыточна (кризис), тогда как на самом деле имеет место класс S1 фирма находится в процветающем состоянии.
Байесовский алгоритм. При наличии полного комплекта данных: априорных вероятностей классов p1 и p2 и матрицы П (6.3) по определению среднего значения дискретной случайной величины
m1 = £ XrPr
r (6.4) можно записать общее выражение среднего риска [2]
R=£ £ пЛу , n Sj}
j=1 k=1 (6.5)
Ply n S }= Ply = П } где K k i} Uk k) - совместная вероятность принятия
решения yk, тогда как на самом деле имел место класс Sj. С учетом правила умножения вероятностей
p{fkn sj }=p{sj ц ksj }=pAyksi} (66)
средний риск R будет иметь следующий вид:
j=1 k=1
P1 [n„P{{1S1 }+ 2| S1 3-^ P2 [П2lP{y }+ П22P{y 2IS2 }] (6.7)
Вероятности ошибок распознавания 1-го рода а (ложных тревог) и 2го рода в (пропуска цели), т. е. соответственно вероятности а того, что будет принято решение y2 о том, что фирма убыточна, тогда как на самом деле она находится в процветающем состоянии S1 и вероятности в (пропуск цели) того, что будет принято решение у1 о том, что фирма процветает, тогда как на самом деле она убыточна, т. е. находится в состоянии S2, по определению равны (см. также (3.6)): а = p{y 2| S1}= Ja>(x/S1 )dx
2
p(yj S1}= J&(x/S1 )dx = 1 -а в = p(yJ S2 }= Jq(x/S2 )dx p{y 2S2 }= 1 -в= ®(xlS2 )dx
X
(6.8)
(6.9)
(6.10) (6.11)
Подставляя (6.8) (6.11) в (6.7), получаем
R = Р1П11 + P2П21 + P ((12 П11 )а P2 (П21 П22 )(1 в) = = Р1П11 + Р2П21 -[Р2(Я21 -)(1 -в)-Р(Я12 -Пц)а] (612)
или, введя обозначения
rif = П11 (1 -а)+ П12а (6.13)
Tf = П2ів + (1 -в), (6.14)
f f
выражаем R через Т и Г2 (для использования при рассмотрении минимаксного алгоритма в последующем материале):
R = Prf + p2r2f (6.15)
В качестве критерия оптимальности алгоритма принятия решения принимается минимальное значение среднего риска R (баейсовский критерий). Тот или иной алгоритм определяется выбором области X2 (или ее дополнения в выборочном пространстве X1), что проявляется через величины а и 1 в. Подставляя значения этих величин из выражений (6.8) и (6.11) в (6.12), получаем
R = Р1П11 + Р2П21 [[Р2((721 П22)со (x|S2)-р(П12 П11 )со (xS1 )]dx,
X2 (6.16)
где
R = Р1Пи + P2 (617)
неотрицательная известная константа и R > 0. Обозначим
f (Х) = Р2 (П21 П22 )® (Х| S2 ) Р (П12 П11 V (x S1 ) , (6 18)
тогда
R = R0 J f (x )dx
X2 . (6.19)
Так как для любого подмножества А множества Х2при
J f (x)dx > J f (x)dX
имеет место неравенство X2 A , то интеграл в правой части
(6.19) достигает максимума тогда и только тогда, когда в область интегрирования включаются все члены выборочного пространства, для
которых подинтегральная функция f(x) неотрицательна. Отсюда следует, что минимальное значение среднего риска достигается при условии, что в область X2 принятия решения у2 включаются все выборки, для которых функция f(x) из (6.18) неотрицательна, а в область X1 принятия решения у1 все выборки, для которых функция f(x) отрицательна, т.
е.
^(Я21 -П22)сс(хS2)-Рі(Пі2 -Пц)сс(xSi) > 0 ,
(6.20)
откуда
L (х):
со
со
У 2
(nS2)> П12 -Пи р ns,) < П21 -P2
у
1
(6.21)
Если граница между областями X2 и X1 выбраны согласно (6.21), то минимальный средний (байесовский) риск определяется по формуле (6.12), в которой условные вероятности ошибок аБ и РБ вычисляются согласно (6.8) и (6.10), где в интегралах фигурируют области интегрирования X2 и X1, определенные согласно (6.21). Т. е. байесовский алгоритм (6.21) запишется в виде:
У 2
L (х) > ск-
П П P
П22 P2
у1
(6.22)
где
а Б =
сЬ (xS1 )dx рБ = |со (x|S2 )dx
X1
(6.23)
И из (6.12) имеем байесовский риск:
Яб = Р1П11 P2П21 + P1 ((12 Пц )аб -P2 (П21 П22 )(1 Рб ). (6.24)
Минимальная величина R называется байесовским риском, поэтому и правило (6.22) также носит название байесовского.
Поскольку событие х є X2 эквивалентно L (х)~ Сб , а х є X1 со
1,2
событию L(х)<Сб, то с учетом (3.7) и (3.8) вероятности ошибок распознавания аБ и РБ можно выразить однократными интегралами от плотности вероятности оценки отношения правдоподобия
L ((IS )'
P{L (х)> C^S1J= (z|S1 )dz = 1 Fl (CBIS,),
(6.25)
Рб = pl{x)< CJS2 }= /ш£ (zs3 )dz = FL {CJS2),
0 (6.26)
Алгоритм максимальной апостериорной вероятности.
Предположим, матрица потерь П неизвестна, т.е. П12=П21= 1, П11=П22 = 0 и, следовательно П = 1.
По формуле Байеса апостериорная вероятность гипотезы Bj при условии отсутствия события А ( Вк полная группа)
£P {Bk }P{A/Bk }
k=1 (6.27)
P = P (six) P = P (six) Здесь у нас 1 ^ч / и 2 v^ / составляют полную группу:
Р1+Р2=1. Следовательно, по формуле Байеса находим апостериорные
вероятности гипотез Б1и S2, если в результате наблюдений получена
выборка x:
p{sjx}= . рffl.(xlS1 ),
P2 ®(X|S1 )+ P2 ®lX|S2 ) (6.28)
р2 Q(X|S1)+ р2 Q(X|S2 ) (6 29)
откуда:
4^ = L (xp-.
p[SiX) рі (6.зо) Теперь устанавливаем правило решения: принимается S2, если P{Sjx}>P{Sjx} и S1, если P{Sjx}>P{Sjx}, тогда
V 2
L (X )> р
< P
VI , (6.31)
т.е. условие p{si/ x}+p{sJ x}=1 равносильно принятию той гипотезы, для которой апостериорная вероятность больше 1/2.
С другой стороны, алгоритм максимальной апостериорной вероятности (6.з1) можно получить и непосредственно подстановкой в (6.21) значений П12=П21=1 и П11=П22=0.
При этом из (6.24) имеем средний риск RMAB
RMAB = P2 + P1aБ -P2 (1 Рб ) = P1aБ + Р2РБ , (6 32)
который, как видно из (6.32), равен априорной вероятности ошибочного решения. Следовательно, алгоритм максимальной апостериорной вероятности минимизирует априорную вероятность ошибок, т.е. в длинной последовательности решений обеспечивает максимальную частоту правильных решений.
Минимаксный алгоритм
П
Если потери ^Пії Пг2 J известны, но неизвестны априорные
вероятности классов Р1 и Р2, то принимающий решение опасается, что
ему попадется именно тот случай, при котором Р1 и Р2 таковы, что дают
максимум величине минимального байесовского риска. Тогда он
предполагает что Р1 и Р2 распределены наименее благоприятно, и им
соответствует максимум байесовского риска минимаксный риск. Так
как события S1 и S2 составляют полную группу, то достаточно
определить наименее благоприятное значение
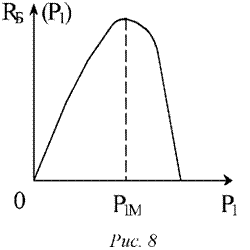
Р1=Р^1}=Р1М, которому соответствует максимум байесовского риска минимаксный риск.
RM (P1M )= max RR (P ) mV lM) 0<p1 <1 бу x) (6.33)
Зависимость байесовского риска RE(P1) от вероятности Р1
изображена на рис. 8.
 |
(6.34)
У (P1 ) = r2f + P (r1f r2f )
ff
где r и ri в соответствии с (6.13) и (6.14) равны
rif = П11 (1 -аБ )+ П12аБ (635) ^ = П21вБ + П22 (1 Рб ) . (636)
В точке Р1=Р1М максимума функции RE(P1) касательная к кривой байесовского риска параллельна оси абсцисс и, следовательно, Y(P1) = const, т. е. не зависит от переменной Р1. Согласно (6.34) это условие максимума функции RE(P1) выполняется, если коэффициент при Р1, равен нулю, т.е. значение Р1М удовлетворяет уравнению:
r1f(P1M ) = r2f (P1M ) . (6.37)
Следовательно минимаксный риск
rm (Рім)= r2(Рім) = rif (P1M) . (6.38)
Уравнение для нахождения порога СМ при минимаксном алгоритме
f f
находим, подставляя в (6.38) значения Т и Г2 из (6.35) и (6.36)
П11 (1 ам ) + П12ам = П21вМ + П22 (1 вМ ) (6.39)
или
П11 + (П12 П11 )аМ = П22 + (П21 П22 )вМ , (6.40)
но, как известно (см. (6.25) и (6.26)):
аМ = 1 fl (((m|S1 ), (641) вМ = FL ((CM I S2 ) , (642)
следовательно, искомое трансцендентное уравнение для определения СМ:
Пц + (лк Пц )[1 fl (Cm|S1 )]=+ (П21 - )[f (c^s2 )]. (643)
Алгоритм, оптимальный по критерию Неймана-Пирсона.
При отсутствии данных о потерях П и априорных вероятностях классов P1 и P2 может применяться алгоритм Неймана-Пирсона, который обеспечивает минимальную вероятность ошибок в при условии, что вероятность ошибок а не больше заданного значения а0.
Задача синтеза оптимального алгоритма принятия решения по указанному критерию состоит в определении минимума функционала:
Ф = в + Са, (6.44) в котором вероятность в зависит от правила выбора решения, вероятность а фиксирована, и С - неопределенный множитель Лагранжа. Но сравнивая (6.44) с выражением для среднего риска (6.12)
R = РП + Р2П21 + р(П12 Пц)а-Р2(П21 - )(1 -в), (6.45)
замечаем, что функционал Ф совпадает со средним риском R при P2=P1=1/2, П11=П22=0, П21=2, П12=2С (плата за ошибку первого рода а в С раз больше, чем за ошибку 2-го рода в). В этом случае легко убедиться, что последнее выражение для R становится равным Ф:
R = в + Са = Ф. (646)
Следовательно, минимум функционала Ф достигается при использовании байесовского алгоритма для P1=P2, П11=П22=0, П21=2, П12=2С, тогда он совпадает с минимальным байесовским риском R, определяемым выражением (6.46).
Тогда из (6.21) находим следующий оптимальный по критерию Неймана-Пирсона алгоритм:
У2 1
у1 2 (6.47)
м і нис і и ишиики 1-і и ри
Р{L(x)> ОД}= 1 -FL(C/S,) = а0
где порог С находится из граничного условия (заданного значения вероятности ошибки 1-го рода а0 (6.25) и (6.26):
(6.48)
Минимальная по критерию Неймана-Пирсона вероятность ошибки 2-го рода в получается из (6.26):
в = р {L(x)< од }= fl (cjs2 ) (6 49)
где С определяется согласно (6.48).
Последовательный алгоритм Вальда. При последовательном анализе Вальда, применяемом как и в предыдущем алгоритме, при отсутствии данных об априорных вероятностях классов P1 и P2 и потерях П на каждом этапе пространство значений отношения
правдоподобия L(x) разделяется на три области: допустимую G1,
критическую G2 и промежуточную Если значение отношения
правдоподобия L(x) попадает в промежуточную область Gnp, то делается следующее наблюдение, и так до тех пор, пока при некотором
значении n размера выборки это значение L(x) не попадает в одну из областей G1 или G2, после чего принимается решение о наличии класса S1 (при попадании в допустимую область G1) или S2 ( при попадании в критическую область G2).
Критерием качества последовательного правила выбора решения обычно является минимум среднего значения размера выборки, необходимой для принятия решения (после чего процедура последовательного анализа завершается) при заданных значениях вероятностей ложной тревоги а и пропуска сигнала в. А. Вальдом показано [10], что среди всех правил выбора решения (в том числе и непоследовательных и, в частности, известных критериев байесовского, максимума апостеорной вероятности, максимума правдоподобия, Неймана-Пирсона, минимаксного), для которых условные вероятности ложной тревоги и пропуска сигнала не превосходят а и в, последовательное правило выбора решения, состоящее в сравнении
отношения правдоподобия L (x"Х2,к'xk) с двумя порогами, нижним с1 и верхним с2, приводит к наименьшим средним значениям размера выборок m1{n | S1} (при наличии класса S1) и m1{n I S2} (при наличии класса S2).
Аналитически процедура последовательного анализа может быть выражена следующим образом: при n-м наблюдении принимается решение о наличии класса S1, если
С1 <Lfc,...,xk)<с2 Lft,...,xn)<c1 n-1
и решение о наличии класса S2, если
c1 <
L ft,..., xk )< c2, L ft,..., x„ )> k=1, n-1 . (6.50)
Нижний и верхний пороги cl и с2 с некоторым приближением
могут быть выражены через заданные значения вероятностей ложной
тревоги а и пропуска сигнала в [10]
в 1 -в
с1 = с2 =
1 -а , а . (6.51)
Таким образом, последовательное правило выбора решения, в отличие от алгоритмов: байесовского, максимума апостериорной вероятности, максимума правдоподобия, Неймана-Пирсона, минимаксного предусматривает сравнение отношения правдоподобия с порогами с1 и с2, не зависящими от априорных вероятностей наличия или отсутствия сигнала и от потерь.
Алгоритм максимального правдоподобия. Если как и в рассмотренных последних двух алгоритмах принятия решений (Неймана-Пирсона и последовательном вальдовском) данные о потерях П и априорных вероятностях классов P1 и P2 отсутствуют, то может также применяться алгоритм максимального правдоподобия, который получается из байесовского алгоритма (6.21) при потерях П11=П22=0; П12=П21=1 и априорных вероятностях классов P1=P2=1/2
У 2
со<
у1 (6.52)
и заключается в принятии решения о наличии того класса S1 и S2,
которому соответствует большее значение функции правдоподобия
со (х|51) со(cS2) v 1 v или v 1 2/.
Подстановкой значений потерь П=1 и априорных вероятностей классов P1 и P2 в выражение для минимального байесовского риска (6.24) получаем выражение для минимального риска РМП, получающееся при использовании алгоритма максимального правдоподобия
RMn =амп + вМП _> (6^3)
где вероятности ошибок аМП и вМП получаются из (6.25) и (6.26):
UL (z/S1 )dz
1 (6.54)
1
0 . (6.55)
Из (6.53) видно, что алгоритм максимального правдоподобия минимизирует суммарную вероятность ошибок распознавания РчМП, в чем также проявляются его оптимальные свойства.
Выбор алгоритма, сохраняющего свои оптимальные свойства при использовании в нем оценок отношения правдоподобия. В начале раздела уже указывалось, что в рассмотренные решающие правила
вместо отношения правдоподобия rox 1> подставляется его
L (x) = ||fj
оценка ю^х1 Проведенная в работах [1, 2] проверка
оптимальности рассмотренных алгоритмов: байесовского, максимума апостериорной вероятности, минимаксного, Неймана-Пирсона, последовательного вальдовского и максимума правдоподобия при
подстановке в них оценок L(x) отношения правдоподобия вместо l(X показала, что при указанной подстановке оптимальные свойства сохраняет только алгоритм максимального правдоподобия, который, вследствие этого, практически во всех случаях будет использоваться в последующем изложении. При этом используется решающее правило (6.52), либо эквивалентное указанному правилу решающее правило для логарифма отношения правдоподобия [см. также (6.1)]:
У 2
, -/ ч , со(xS2) > ln L (x) = ln 0 соxSj) <
(6.56)

Обсуждение Диагностика кризисного состояния предприятия
Комментарии, рецензии и отзывы