Страница 112
Решение проблемы семантического анализа Интернет-документов в настоящее время связывается с использованием двух подходов. В рамках первого из них предполагается, что семантическая разметка HTML-текста выполняется вручную (или полуавтоматически, с применением соответствующих инструментальных средств) его автором на основе специальных метатегов. По существу, результатом такой разметки является семантическая сеть, отражающая знания, представленные в документе. Второй подход связан с автоматическим и/или полуавтоматическим преобразованием исходного текста в специальное семантическое представление, как правило, в онтологию или ее фрагмент.
Подробнее эти подходы обсуждаются ниже. Но и в том и в другом случае для выполнения указанных преобразований целесообразно конвертирование HTML-текстов в более удобное для дальнейшей обработки представление. Для иллюстрации возможностей применения к решению этой задачи средств представления знаний, описанных в предыдущих главах, рассмотрим интеллектуальный HTML-конвертор [Maikevich et al, 1998].
Для сокращения объема материала обсудим подмножество языка HTML, которое может быть задано следующими BNF-определениями:
HTML-текст ::= <HTML> HEAD BODY </HTML>
HEAD ::= TITLE { HEAD } | ...
TITLE ::= <TITLE> строка </TITLE>
BODY ::= <BODY> HTML-BODY </BODY>
HTML-BODY ::= PARAGRAPH { HTML-BODY } |
HEADER { HTML-BODY } | LIST { HTML-BODY } | ...
HEADER ::= <H1> TEXT </H1> \ <H2> TEXT </H2> \ ...
PARAGRAPH ::= <P> TEXT </P>
LIST ::= <UL> LIST-ATOM { LIST-ATOM } </UL> \
<OL> LIST-ATOM { LIST-ATOM } </OL> \
<MENU> LIST-ATOM { LIST-ATOM } <MENU> \ ...
………………………………………………………………………..
ANCHOR ::= <A HREF= LINK > TEXT </A> |
<A NAME= метка > TEXT </A>
TEXT ::= ...
LIST-ATOM ::= ...
LINK ::=...
………………………………………………………………
Некоторые из синтаксических диаграмм, соответствующих приведенным выше правилам, представлены на рис. 8.3 и 8.4.
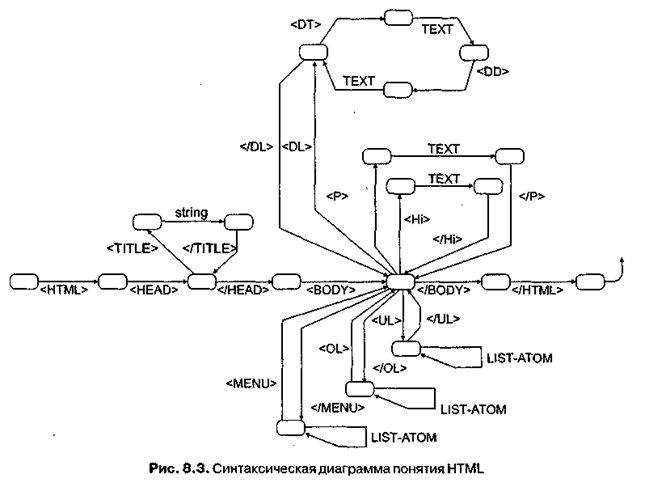
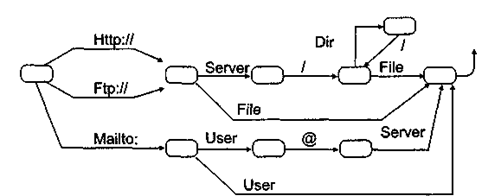
Рис. 8.4. Синтаксическая диаграмма понятия LINK
Как следует из приведенных правил и диаграмм, с теоретической точки зрения HTML — это простой язык программирования с контекстно-свободной грамматикой. Нетрудно показать, что для анализа HTML-текстов можно использовать, например, нисходящие распознаватели, реализуемые на базе метода рекурсивного спуска. При этом возможны разные подходы. Ниже для этого используется продукционно-фреймовый формализм представления знаний и показывается, как на этой основе может быть разработан интеллектуальный HTML-конвертор.
Прежде всего зададим регулярное отображение каждого правила спецификации HTML-конструкций в соответствующий объект базы знаний нагуровне фрейма-прототипа. Система таких прототипов даст нам описание языка, а множество фреймов-экземпляров — спецификацию конкретных и синтаксически правильных HTML-текстов. Основные правила такого отображения следующие:
• каждому концепту из левой части BNF-определения поставим в соответствие имя фрейма-прототипа;
• альтернативам из правой части BNF-определения при этом должны соответствовать имена слотов этого фрейма;
• для концептов-нетерминалов соответствующий слот должен иметь тип frame;
• для концептов-терминалов соответствующие слоты будут, как правило, иметь типы numb или string,
• рекурсия в BNF-определениях заменяется итерацией, а соответствующие слоты становятся множественными.
Применение сформулированных выше правил к BNF-определениям языка HTML приводит нас к следующему множеству фреймов-прототипов:
[htmlis_aprototype, if_added HTML ();
HEADframe, restr_by head;
BODYframe, restr_by body ];
[headis_aprototype, if_added HEAD ();
BODYjframe}, restr_by one_of {title, ...} ];
[title is_aprototype, if_added TITLE ();
BODYstring ];
……………………………………………………………………………
[bodyis_aprototype, if_added BODY ();
SENT{frame}, restr_by one_of {header, paragraph, list, ...} ];
[header is_aprototype;
BODYframe, restr_by text ];
[hi is_aheader,if_added H1()];...[h6 is_aheader, if_added H6()];

Обсуждение Базы знаний интеллектуальных систем
Комментарии, рецензии и отзывы