Плотность вероятности
Плотность вероятности
0,20 0,15 0.10 0.05
Постоянная и случайная составляющие случайной переменной
Часто вместо рассмотрения случайной величины как единого целого можно и удобно разбить ее на постоянную и чисто случайную составляющие, где постоянная составляющая всегда есть ее математическое ожидание. Если х — случайная переменная и д — ее математическое ожидание, то декомпозиция случайной величины записывается следующим образом:
х=і + и, (0.16)
где и — чисто случайная составляющая (в регрессионном анализе она обычно представлена случайным членом).
Конечно, можно было бы посмотреть на это по-другому и сказать, что случайная составляющая и определяется как разность между х и fi:
и = х-і. (0.17)
Из определения следует, что математическое ожидание величины и равно нулю. Из уравнения (0.17) имеем:
Е(и) = Е(х-]й = Е(х)-Е{у) =
= £(х)-ц = ц-ц = 0. (0.18)
Поскольку весь разброс значений х обусловлен и, неудивительно, что теоретическая дисперсия х равна теоретической дисперсии и. Последнее нетрудно доказать. По определению,
ox2 = £{(x-n)2} = £{w2} (0.19)
и
о2 = £ {{и м.о.(и))2} = £{(!/О)2} = £ {и}. (0.20)
Таким образом, о2 может быть эквивалентно определена как дисперсия х или и.
Обобщая, можно утверждать, что если х — случайная переменная, определенная по формуле (0.16), где ц — заданное число и и — случайный член с £(i/) = О и pop. var (и) ?= о2, то математическое ожидание величины х равно а дисперсия — а2.
Способы оценивания и оценки
До сих пор мы предполагали, что имеется точная информация о рассматриваемой случайной переменной, в частности — об ее распределении вероятностей (в случае дискретной переменной) или о функции плотности распределения (в случае непрерывной переменной). С помощью этой информации можно рассчитать теоретическое математическое ожидание, дисперсию и любые другие характеристики, в которых мы можем быть заинтересованы.
Однако на практике, за исключением искусственно простых случайных величин (таких, как число выпавших очков при бросании игральной кости), мы не знаем точного вероятностного распределения или плотности распределения вероятностей. Это означает, что неизвестны также и теоретическое математическое ожидание, и дисперсия. Мы, тем не менее, можем нуждаться в оценках этих или других теоретических характеристик генеральной совокупности.
Процедура оценивания всегда одинакова. Берется выборка из п наблюдений, и с помощью подходящей формулы рассчитывается оценка нужной характеристики. Нужно следить за терминами, делая важное различие между способом или формулой оценивания и рассчитанным по ней для данной выборки числом, являющимся значением оценки. Способ оценивания — это общее правило, или формула, в то время как значение оценки — это конкретное число, которое меняется от выборки к выборке1.
В табл. 0.5 приведены формулы оценивания для двух важнейших характеристик генеральной совокупности. Выборочное среднее х обычно дает оценку для математического ожидания, а формула s2 в табл. 0.5 — оценку дисперсии генеральной совокупности.
Таблица 0.5
Характеристики
генеральной Формулы оценивания
совокупности
Среднее, ц х = —X*/
п
Дисперсия, о2 s Х(х;-дг)
/1-1
Отметим, что это обычные формулы оценки математического ожидания и дисперсии генеральной совокупностиL однако не единственные. Возможно, вы настолько привыкли использовать х в качестве оценки для ц, что даже не задумывались об альтернативах. Конечно, не все формулы оценки, которые можно представить, одинаково хороши. Причина, по которой в действительности используется х 9 в том, что эта оценка в наилучшей степени соответствует двум очень важным критериям — несмещенности и эффективности. Эти критерии будут рассмотрены ниже.
Оценки как случайные величины
1 В русскоязычной литературе и способ оценивания, и значение оценки часто сокращенно называют просто оценкой. Иногда в дальнейшем мы тоже будем так поступать, если из контекста ясно, о чем идет речь. (Прим. ред.)
Получаемая оценка представляет частный случай случайной переменной. Причина здесь в том, что сочетание значений х в выборке случайно, поскольку х — случайная переменная и, следовательно, случайной величиной является и функция набора ее значений. Возьмем, например, х — оценку математического ожидания:
хЛ(Х1+Х2+...+ хй). п
(0.21)
Мы только что показали, что величина х в /*-м наблюдении может быть разложена на две составляющие: постоянную часть р. и чисто случайную составляющую и;.
x, = *i + n, (0.22)
Следовательно,
х = ц + й, (0.23)
где и — выборочное среднее величин иґ
Отсюда можно видеть, что х, подобно х, имеет как фиксированную, так и чисто случайную составляющие. Ее фиксированная составляющая — ц, то есть математическое ожидание х, а ее случайная составляющая — и, то есть среднее значение чисто случайной составляющей в выборке.
Функции плотности вероятности для х и х показаны на одинаковых графиках (рис. 0.7). Как показано на рисунке, величина х считается нормально распределенной. Можно видеть, что распределения, как х, так и х, симметричны относительно і — теоретического среднего. Разница между ними в том, что распределение х ^же и выше. Величина х, вероятно, должна быть ближе к р., чем значение единичного наблюдения х, поскольку ее случайная составляющая и есть среднее от чисто случайных составляющих и{9 и2,ип в выборке, которые, по-видимому, «гасят» друг друга при расчете среднего. Далее, теоретическая дисперсия величины и составляет лишь часть теоретической дисперсии и. В разделе 1.7 будет показано, что если pop. var (и) = а2, то pop. var (и) = а2/п.
Функция плотности Функция плотности

Ц X Ц X
Рис. 0.7. Сравнение функций плотности вероятности одиночного наблюдения
и выборочного среднего
вероятности х вероятности X
Величинаs2 — оценка теоретической дисперсних — также является случайной переменной. Вычитая (0.23) из (0.22), имеем:
хі-х = иі-й. (0.24)
Следовательно,
*2 = j^jI{<*/ -х)2} = ^I{(и, -и)2). (0.25)
Таким образом, s1 зависит от (и только от) чисто случайной составляющей наблюдений х в выборке. Поскольку эти составляющие меняются от выборки к выборке, также от выборки к выборке меняется и величина оценки s2.
Несмещенность
Поскольку оценки являются случайными переменными, их значения лишь по случайному совпадению могут в точности равняться характеристикам генеральной совокупности. Обычно будет присутствовать определенная ошибка, которая может быть большой или малой, положительной или отрицательной, в зависимости от чисто случайных составляющих величин х в выборке.
Хотя это и неизбежно, на интуитивном уровне желательно, тем не менее, чтобы оценка в среднем за достаточно длительный период была аккуратной. Выражаясь формально, мы хотели бы, чтобы математическое ожидание оценки равнялось бы соответствующей характеристике генеральной совокупности. Если это так, то оценка называется несмещенной. Если это не так, то оценка называется смещенной, и разница между ее математическим ожиданием и соответствующей теоретической характеристикой генеральной совокупности называется смещением.
Начнем с выборочного среднего. Является ли оно несмещенной оценкой теоретического среднего? Равны ли Е(х) и |i? Да, это так, что непосредственно вытекает из (0.23).
Величинах включает две составляющие -рй. Значение и равно средней чисто случайных составляющих величин х в выборке, и, поскольку математическое ожидание такой составляющей в каждом наблюдении равно нулю, математическое ожидание и равно нулю. Следовательно,
Е(х) = E(i + и) = Е([і) + Е(и) = ц + О = ц. (0.26)
Тем не менее полученная оценка — не единственно возможная несмещенная оценка |i. Предположим для простоты, что у нас есть выборка всего из двух наблюдений — х{ и х2. Любое взвешенное среднее наблюдений х{ и х2 было бы несмещенной оценкой, если сумма весов равна единице. Чтобы показать это, предположим, что мы построили обобщенную формулу оценки:
Z = X{x{+X2x2. (0.27)
Математическое ожидание Z равно:
E(Z) = Е(Х{х{ + Х2х2) = Е(Х{х{) + Е(к2х2) =
= Я.1£(х1) + Х2Е(х2) = xi + X2i = (Хх + X2)i. (0.28)
Если сумма к{ и А., равна единице, то мы имеем E(Z) = (і, и Z является несмещенной оценкой |1.
Таким образом, в принципе число несмещенных оценок бесконечно. Как выбрать одну из них? Почему в действительности мы всегда используем выборочное среднее с Х1=Х1 = 0,5? Возможно, вы полагаете, что было бы несправедливым давать разным наблюдениям различные веса или что подобной асимметрии следует избегать в принципе. Мы, однако, не заботимся здесь о справедливости или о симметрии как таковой. В следующем разделе мы увидим, что имеется и более осязаемая причина.
До сих пор мы рассматривали только оценки теоретического среднего. Выше утверждалось, что величина s2, определяемая в соответствии с табл. 0.5, является оценкой теоретической дисперсии а2. Можно показать, что математическое ожидание s2 равно а2, и эта величина является несмещенной оценкой теоретической дисперсии, если наблюдения в выборке независимы друг от друга. Доказательство этого математически несложно, но трудоемко, и поэтому оно вынесено в приложение О.З в конце данного обзора.
Эффективность
Несмещенность — желательное свойство оценок, но это не единственное такое свойство. Еще одна важная их сторона — это надежность. Конечно, немаловажно, чтобы оценка была точной в среднем за длительный период, но, как однажды заметил Дж. М. Кейнс, «в долгосрочном периоде мы все умрем». Мы хотели бы, чтобы наша оценка с максимально возможной вероятностью давала бы близкое значение к теоретической характеристике, что означает желание получить функцию плотности вероятности, как можно более «сжатую» вокруг истинного значения. Один из способов выразить это требование — сказать, что мы хотели бы получить сколь возможно малую дисперсию.
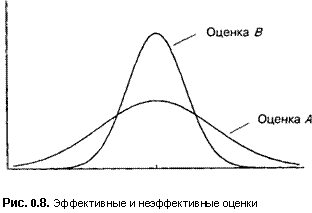
Предположим, что мы имеем две оценки теоретического среднего, рассчитанные на основе одной и той же информации, что обе они являются несме
 |
Функция плотности вероятности
щенными и что их функции плотности вероятности показаны на рис. 0.8. Поскольку функция плотности вероятности для оценки В более «сжата», чем для оценки А, с ее помощью мы скорее получим более точное значение. Формально говоря, эта оценка более эффективна.
Важно заметить, что мы использовали здесь слово «скорее». Даже хотя оценка В более эффективна, это не означает, что она всегда дает более точное значение. При определенном стечении обстоятельств значение оценки А может быть ближе к истине. Однако вероятность того, что оценка^ окажется более точной, чем В, составляет менее 50\%.
Это напоминает вопрос о том, пользоваться ли ремнями безопасности при управлении автомобилем. Множество обзоров в разных странах показало, что значительно менее вероятно погибнуть или получить увечья в дорожном происшествии, если воспользоваться ремнями безопасности. В то же время не раз отмечались странные случаи, когда не сделавший этого индивид чудесным образом уцелел, но погиб бы, будучи пристегнут ремнями. Упомянутые обзоры не отрицают этого. В них лишь делается вывод, что преимущество на стороне тех, кто пользуется ремнями безопасности. Подобным же преимуществом обладает и эффективная оценка. (Неприятный комментарий: в тех странах, где пользование ремнями безопасности сделано обязательным, сократилось предложение для трансплантации почек людей, ставших жертвами аварий.)
Мы говорили о желании получить оценку как можно с меньшей дисперсией, и эффективная оценка — это та, у которой дисперсия минимальна. Сейчас мы рассмотрим дисперсию обобщенной оценки теоретического среднего и покажем, что она минимальна в том случае, когда оба наблюдения имеют равные веса.
Если наблюдениях, их2 независимы, теоретическая дисперсия обобщенной оценки равна:
pop.var(Z) = pop.var^xj + Х2х2) = (Х] + Х22)<з2. (0.29)
(Это можно показать, используя правила расчета дисперсии, рассматриваемые в главе 1.)
Мы уже выяснили, что для несмещенности оценки необходимо равенство единице суммы Х{ и Х2. Следовательно, для несмещенных оценок Х2 = (1 — Х{) и
х] + Х22 = X] + (1 Х{ )2 = 2Х] 2Х{ +1. (О.ЗО)
Поскольку мы хотим выбрать >ч так, чтобы минимизировать дисперсию, нам нужно минимизировать при этом (2Х{2 — 2Х{ + 1). Эту задачу можно решить графически или с помощью дифференциального исчисления. В любом случае минимум достигается при Х{ = 0,5. Следовательно, Х2 также равно 0,5.
Итак, мы показали, что выборочное среднее имеет наименьшую дисперсию среди оценок рассматриваемого типа. Это означает, что оно имеет наиболее «сжатое» вероятностное распределение вокруг истинного среднего и, следовательно (в вероятностном смысле), наиболее точно. Строго говоря, выборочное среднее — это наиболее эффективная оценка среди всех несмещенных оценок. Конечно, мы показали это только для случая с двумя наблюдениями, но сделанные выводы верны для выборок любого размера, если наблюдения не зависят друг от друга.
Два заключительных замечания: во-первых, эффективность оценок можно сравнивать лишь тогда, когда они используют одну и ту же информацию, например один и тот же набор наблюдений нескольких случайных переменных. Если одна из оценок использует в 10 раз больше информации, чем другая, то она вполне может иметь меньшую дисперсию, но было бы неправильно считать ее более эффективной. Во-вторых, мы ограничиваем понятие эффективности сравнением распределений несмещенных оценок. Существуют определения эффективности, обобщающие это понятие на случай возможного сравнения смещенных оценок, но в этой книге мы будем придерживаться данного простого определения.
Упражнения
0.8. Рассчитайте дисперсию обобщенной оценки теоретического среднего для частного случая о2=1 и выборки из двух наблюдений, воспользовавшись уравнением (0.30) с величинами Х1 от 0 до 1 при шаге 0,1. Нанесите полученные точки на график. Важно ли то, чтобы весовые коэффициенты Х{ и Х2 в точности равнялись друг другу?
О.9. Покажите, что при наличии п наблюдений условием того, чтобы обобщенная формула (к{х{ + ... + Хпхп) давала несмещенную оценку ц, является Х{ + ... + А,Я=1.
0.10. Вообще говоря, при увеличении размера выборки дисперсия распределения оценки убывает. Правильно ли утверждать при этом, что оценка становится более эффективной?
Противоречия между несмещенностью и минимальной дисперсией
В данном обзоре мы уже выяснили, что для оценки желательна несмещен
 |
 |
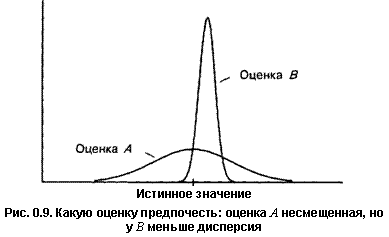
Оценка А хороша своей несмещенностью, но преимуществом оценки В является то, что ее значения практически всегда близки к истинному значению. Какую из них вы бы выбрали?
Данный выбор зависит от обстоятельств. Если возможные ошибки вас не очень тревожат при условии, что за длительный период они «погасят» друг друга, то, по-видимому, вы выберете А. С другой стороны, если для вас приемлемы малые ошибки, но неприемлемы большие, то вам следует выбрать В.
Формально говоря, выбор определяется функцией потерь, стоимостью сделанной ошибки как функцией ее размера. Обычно выбирают оценку, дающую наименьшее ожидание потерь, и делается это путем взвешивания функции потерь по функции плотности вероятности. (Если вы не любите риск, то можете также пожелать учесть дисперсию потерь.)
Типичным примером функции потерь, показанной квадратичной параболой нарис. 0.10, может служить квадрат ошибки. Ее математическое ожидание, известное как среднеквадратичная ошибка (MSE), может быть разложено на составляющие:
MSE = Дисперсия оценки + Квадрат смещения.
(0.31)
Чтобы показать это, предположим, что оценка Z используется для оценивания неизвестного значения параметра генеральной совокупности 9. Предположим, что математическое ожидание Z равно |іг. Оно будет равняться 9 только в том случае, если Z— несмещенная оценка. В общем случае будет иметь место смещение, равное (цг9). ДисперсияZ равна Е{(Z|iz)}2. Величина MSE оценки Z может быть разложена на составляющие следующим образом:
MSE(Z) = E{(Z в)2} = E{([Z цг] + [цг в])2} =
= £{(Z цг)2} + 2E{(Z -цг)(Нг в)} + £{(цг в)2 =
= pop.var(Z) + 2(цг -G)£{(Z -цг)} + Квадрат смещения =
= pop. var(Z) + Квадрат смещения,
(0.32)
поскольку £{(Z -цг)} = E(Z)-iz = 0.
На рис. 0.9 оценка А не имеет составляющей смещения, но имеет гораздо большую составляющую дисперсии, чем В, и поэтому она хуже по данному критерию.
Hiawatha Designs an Experiment1 M. G. Kendall
Hiawatha, mighty fighter,
He could shoot ten arrows upwards
Shoot them with such strength and swiftness
That the last had left the bowstring
Ere the first to earth descended
This was commonly regarded
As a feat of skill and cunning.
One or two sarcastic spirits Pointed out to him, however That it might be much more useful If he sometimes hit the target. Why not shoot a little straighter And employ a smaller sample?
Hiawatha, who at college Majored in applied statistics Consequently felt entitled To instruct his fellow men on Any subject whatsoever, Waxed exceedingly indignant Talked about the law of error Talked about truncated normals Talked of loss of information Talked about his lack of bias Pointed out that in the long run Independent observations
Even though they missed the target Had an average point of impact Very near the spot he aimed at (With the possible exception Of a set of measure zero).
This, they said, was rather doubtful. Anyway, it did not matter
1 По согласованию с автором, мы решили сохранить в этом издании на языке оригинала приводимое им шуточное стихотворение М. Дж. Кендалла на мотивы «Песни о Гайавате». Читатель вполне может пропустить его без ущерба для понимания материала книги. (Прим. ред.)
What resulted in the long run;
Either he must hit the target Much more often than at present Or himself would have to pay for All the arrows that he wasted.
Hiawatha, in a temper, Quoted parts of R. A. Fisher Quoted Yates and quoted Finney Quoted yards of Oscar Kempthorne Quoted reams of Cox and Cochran Practically in extenso
Trying to impress upon them That what actually mattered Was to estimate the error.
One or two of them admitted Such a thing might have it uses Still, they said, he might do better If he shot a little straighter.
Hiawatha, to convince them, Organized a shooting contest Laid out in the proper manner Of designs experimental Recommended in the textbooks (mainly used for tasting tea, but Sometimes used in other cases) Randomized his shooting order In factorial arrangements
Used in the theory of Galois Fields of ideal polynomials Got a nicely balanced layout And successfully confounded Second-order interactions.
All the other tribal marksmen Ignorant, benighted creatures Of experimental set-ups Spent their time of preparation Putting in a lot of practice Merely shooting at a target.
Thus it happened in the contest
That their scores were most impressive
With one solitary exception
This (I hate to have to say it)
Was the score of Hiawatha
Who, as usual, shot his arrows
Shot them with great strength and swiftness
Managing to be unbiased
Not, however, with his salvo, Managing to hit the target.
There, they said to Hiawatha This is what we all expected.
Hiawatha, nothing daunted Called for pen and called for paper Did analyses of variance
Finally produced the figures
Showing beyond peradventure
Everybody else was biased
And the variance components
Did not differ from each other
Or from Hiawatha's
(this last point, one should acknowledge
Might have been much more convincing
If he hadn't been compelled to
Estimate his own component
From experimental plots in
Which the values all were missing
Still, they didn't understand it
So they couldn't raise objections
This is what so often happens
With analyses of variance).
All the same, his fellow tribesmen Ignorant, benighted heathens Took away his bow and arrows, Said that though my Hiawatha Was a brilliant statistician
He was useless as a bowman. As for variance components Several of the more outspoken Made primeval observations Hurtful of the finer feelings Even of a statistician.
In a corner of the forest Dwells alone my Hiawatha Permanently cogitating On the normal law of error Wondering in idle moments Whethering an increased precision Might perhaps be rather better Even at the risk of bias
If thereby one, now and then, could Register upon the target.
From Kendall, 1959
Упражнения
0.11. Приведите примеры приложений, в которых вы могли бы: 1) предпочесть оценку типа А (рис. 0.9); 2) предпочесть оценку типа В (рис. 0.9).
0.12. Изобразите функцию потерь для прибытия в аэропорт позже (или раньше) времени окончания регистрации.
0.13. Имеются две оценки неизвестного параметра генеральной совокупности. Обязательно ли является более эффективной та из них, которая имеет меньшую дисперсию?
Влияние увеличения размера выборки на точность оценок
Будем по-прежнему предполагать, что мы исследуем случайную переменную х с неизвестным математическим ожиданием д и теоретической дисперсией а2 и что для оценивания i используется х. Каким образом точность оценки х зависит от числа наблюдений я?
Ответ неудивителен: при увеличении п оценка х, вообще говоря, становится более точной. В единичном эксперименте большая по размеру выборка необязательно даст более точную оценку, чем меньшая выборка, — всегда может присутствовать элемент везения, — но общая тенденция должна быть
именно такой. Поскольку дисперсия х выражается формулой с2/п, она тем меньше, чем больше размер выборки и, значит, тем сильнее «сжата» функция плотности вероятности ДЛЯ х.
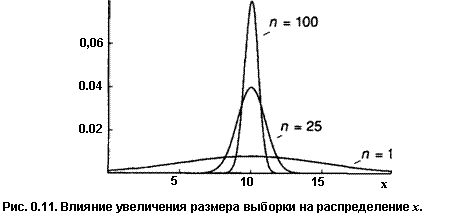
Это показано на рис. 0.11. Мы предполагаем, чтох нормально распределена со средним 25 и стандартным отклонением 50. Если размер выборки равен 25,
то стандартное отклонение величины х, равное о / л/л , составит: 50 / V25 = 10.
Если размер выборки равен 100, то это стандартное отклонение равно 5. На рис. 0.11 показаны соответствующие функции плотности вероятности. Вторая (п= 100) выше первой в окрестности что говорит о более высокой вероятности получения с ее помощью аккуратной оценки. За пределами этой окрестности вторая функция всюду ниже первой.
Чем больше размер выборки, тем уже и выше будет график функции плотности вероятности для х. Если п становится действительно большим, то график функции плотности вероятности будет неотличим от вертикальной прямой, соответствующей х = д. Для такой выборки случайная составляющая х становится действительно очень малой, и поэтому х обязательно будет очень близкой
к х. Это вытекает из того факта, что стандартное отклонение х, равное а / fn , становится очень малым при больших л.
В пределе, при стремлении п к бесконечности, а / V« стремится к нулю и х стремится в точности к ц. Это можно записать математически:
 Функция плотности вероятности
Функция плотности вероятности
°0
0.08
lim х = l
(0.33)
Эквивалентный и более распространенный способ описания этого факта предлагает использование термина plim, где plim означает «предел по вероятности» и подчеркивает, что предел достигается в вероятностном смысле:
plim х = ц,
(0.34)
когда для любых сколь угодно малых є и 5 вероятность того, что х отличается от ц больше, чем на є, будет меньшей 8 при достаточно большом размере выборки.

Обсуждение Введение в эконометрику
Комментарии, рецензии и отзывы